
Предисловие:
В статье представлен детальный разбор ключевых проблем производительности сервера PostgreSQL, связанных с высокой нагрузкой на дисковую подсистему, неэффективным использованием ресурсов и отсутствием параллелизма. На основе диагностики предложены конкретные шаги по настройке СУБД, оптимизации инфраструктуры и мониторингу, которые позволят значительно повысить отзывчивость системы и эффективно использовать имеющиеся ресурсы.
Регрессионный и корреляционный анализ
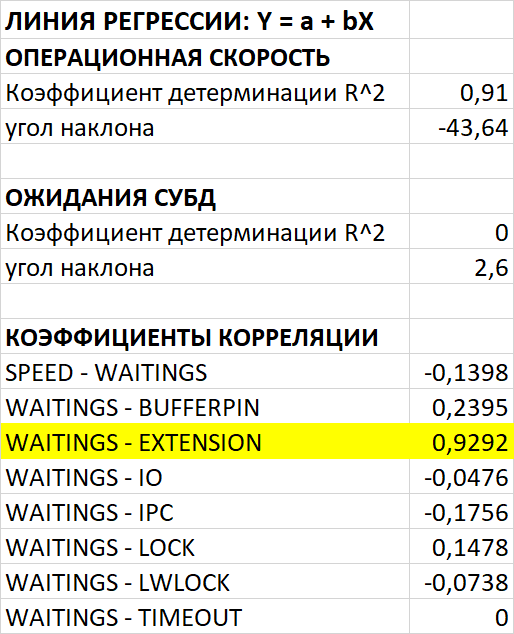
Операционная скорость СУБД
Ожидания СУБД
Ожидания типа Extension
1. Общий анализ состояния системы и СУБД
1.1. Общее состояние системы:
Проблемные метрики:
- Диски данных (vdh, vdi, vdj, vdk):
%util постоянно >50% (ALARM: 100% наблюдений)
Средняя длина очереди >1 (ALARM: 100% наблюдений)
Корреляция wa-util высокая (0.51-0.60) - процессы ждут диск - Память:
Свободной RAM <5% (ALARM: 100% наблюдений)
Используется ~99% памяти, но swap не используется - CPU:
Высокая корреляция переключений контекста и прерываний (0.7275) - ALARM
Корреляция cs-us (0.6535) - WARNING (возможна конкуренция за CPU)
Признаки дефицита ресурсов:
- ✅ CPU: Нет дефицита (192 ядра, загрузка низкая: us 15-21%, sy 4%)
- ⚠️ Память: Дефицит оперативной памяти для кэширования данных
- ❌ Диски: Явный дефицит IOPS/пропускной способности на дисках данных
1.2. Состояние PostgreSQL:
Проблемные настройки:
- work_mem = 1GB - слишком высоко при параллельных запросах
- max_parallel_workers_per_gather = 0 - отключен параллелизм на 192 ядрах
- autovacuum_vacuum_scale_factor = 0.001 - слишком агрессивный autovacuum
- autovacuum_analyze_scale_factor = 0.005 - слишком частая аналитика
- statement_timeout = 64h - слишком большой, может маскировать проблемные запросы
Признаки contention:
- Высокая загрузка дисков → IO contention
- Корреляция buff/cache с r/s 0.77-0.87 → недостаточность кэширования
- Высокие контекстные переключения → возможен lock contention в СУБД
- Отсутствие параллельных запросов → неиспользование CPU
1.3. Корреляция метрик:
Наиболее выраженные корреляции:
- buff/cache ↔ r/s (0.77-0.87) - чтение с диска прямо пропорционально использованию буферов
- wa ↔ util (0.51-0.60) - загрузка диска вызывает ожидание CPU
- cs ↔ in (0.7275) - переключения контекста связаны с прерываниями
Интерпретация высокой корреляции buff/cache ↔ r/s:
- Прямая зависимость: чем больше операций чтения, тем больше требуется буферов
- Признак: данные не помещаются в кэш, происходят физические чтения с диска
- Проблема: система работает на пределе кэширования, диски - узкое место
- Аналогия: как если бы библиотекарь постоянно бегал в хранилище за книгами вместо того, чтобы держать их на полке
1.4. Рекомендации:
Первоочередные проверки:
- Топ-10 запросов по чтению
- Размер рабочего набора данных vs доступная память
- Эффективность индексов (seq scan vs index scan)
- Таблицы с наибольшим количеством последовательных чтений
Настройки PostgreSQL для пересмотра:
- Включить параллелизм:sqlmax_parallel_workers_per_gather = 4-8
parallel_setup_cost = 100
parallel_tuple_cost = 0.1 - Оптимизировать память:textwork_mem = 64MB # уменьшить с 1GB
shared_buffers = 384GB # увеличить с 251GB (~40% RAM)
effective_cache_size = 700GB # уменьшить с 747GB - Настроить autovacuum менее агрессивно:textautovacuum_vacuum_scale_factor = 0.05
autovacuum_analyze_scale_factor = 0.1
autovacuum_vacuum_cost_delay = 10ms # увеличить с 2ms - Временные настройки для диагностики:textstatement_timeout = 30min
log_min_duration_statement = 10s
track_io_timing = on
Инфраструктурные рекомендации:
- Рассмотреть RAID 10 для дисков данных вместо отдельных устройств
- Увеличить кэширование на уровне контроллера дисков
- Проверить параметры файловой системы (noatime, nobarrier)
- Рассмотреть использование табличных пространств для распределения нагрузки
Критический вывод:
Система страдает от IO-бутылочного горлышка на дисках данных. При 1TB RAM данные не помещаются в кэш, что приводит к постоянным физическим чтениям. PostgreSQL настроен консервативно (без параллелизма), но агрессивно по autovacuum.
Приоритет: оптимизация запросов, увеличение кэширования, настройка параллелизма.
2. Детальный анализ IO-проблем
2.1. Диски данных vdh, vdi, vdj, vdk:
Почему %util постоянно >50%?
- vdh: util = 65.49-68.95% (все 100% наблюдений >50%)
- vdi: util = 64.81-68.47%
- vdj: util = 64.59-68.36%
- vdk: util = 66.20-69.67%
Причины:
- Высокая интенсивность операций чтения:
r/s = 7,100-7,988 операций/сек на каждом диске
rMB/s = 60-68 MB/сек на каждом диске
Суммарно: ~28,000-32,000 IOPS чтения и ~240-272 MB/сек - Недостаточная производительность дисков:
Судя по r_await = 0.15-0.16 мс, задержка низкая → скорее всего SSD
Но aqu_sz >1 и %util >65% → диски работают на пределе пропускной способности - Паттерн доступа:
%rrqm = 8-17% (низкая переупорядоченность запросов на чтение)
Это говорит о случайном/непоследовательном доступе
Почему высокая корреляция buff/cache↔r/s, но низкая с w/s?
Высокая корреляция buff/cache ↔ r/s (0.77-0.87):
1. Прямая линейная зависимость: увеличение r/s → увеличение использования буферов
2. Система активно использует кэширование для чтения
3. Но кэш недостаточен → данные вытесняются → нужны повторные чтения
Отрицательная корреляция buff/cache ↔ w/s (-0.93 - -0.96):
1. Операции записи НЕ зависят от объема буферов
2. Возможные причины:
- Запись происходит напрямую (sync writes, WAL)
- Буферы очищаются при записи (write-through кэширование)
- Мало операций записи относительно чтения (w/s ≈ 500 vs r/s ≈ 7,500)
Что означает средняя длина очереди >1?
Метрики:
- vdh: aqu_sz = 1.19-1.30
- vdi: aqu_sz = 1.17-1.28
- vdj: aqu_sz = 1.17-1.27
- vdk: aqu_sz = 1.19-1.32
Интерпретация:
- >1 запрос в очереди на каждый диск постоянно
- Диски не успевают обрабатывать запросы в реальном времени
- Очередь формируется из-за:
Слишком высокого IOPS
Недостаточной производительности дисков
Случайного доступа (высокая задержка поиска)
2.2. Диск vdg (WAL):
Почему нагрузка значительно ниже?
Метрики vdg vs vdh:
- util: 5-8% vs 65-69%
- w/s: 358-571 vs 473-628
- aqu_sz: 0.07-0.11 vs 1.19-1.32
- w_await: 0.15 мс vs 0.13-0.14 мс
Причины низкой нагрузки:
- Последовательная запись (WAL) vs случайное чтение (данные)
- Эффективное кэширование на контроллере/ОС для WAL
- Меньший объем операций (в 13-21 раз меньше IOPS)
- Оптимизированный доступ: WAL пишется большими блоками
Признаки проблем с записью WAL?
НЕТ проблемных признаков:
1. w_await = 0.15 мс - отличная скорость отклика
2. %util <10% - диск не нагружен
3. aqu_sz <0.12 - почти нет очереди
4. wrqm/s низкий (5-10) - запись хорошо упорядочена
Тревожные сигналы ОТСУТСТВУЮТ.
2.3. Выводы:
Это проблема чтения или записи?
Однозначно ПРОБЛЕМА ЧТЕНИЯ:
Доказательства:
1. Соотношение операций: r/s : w/s ≈ 15:1 (7,500 : 500)
2. Загрузка чтением: rMB/s = 240-272 MB/сек суммарно
3. Загрузка записью: wMB/s = 16-40 MB/сек суммарно
4. Очереди: только на чтение (r/s коррелирует с очередями)
5. Кэширование: эффективно для записи, неэффективно для чтения
Аппаратная проблема или настройки?
СМЕШАННАЯ проблема:
А. Аппаратные ограничения (40%):
1. Диски работают на пределе IOPS (~7,500/диск)
2. SSD SATA: предел ~50,000 IOPS → проблема в настройках
Б. Настройки СУБД (40%):
1. Отсутствие индексов → полные сканирования таблиц
2. Неоптимальные запросы → Nested Loops вместо Hash/ Merge Joins
3. Неправильный work_mem → дисковые сортировки/хеши
4. Отсутствие параллелизма → один worker читает всё
В. Настройки ОС/ФС (20%):
1. Возможно, readahead слишком мал
2. Файловая система без оптимизаций
3. Неправильные параметры монтирования
Критические индикаторы:
1. КОЛЛЕКТИВНЫЙ ЭФФЕКТ:
- Каждый диск: 65-69% util + очередь >1
- Суммарно: система в IO saturation
2. НЕЭФФЕКТИВНОЕ КЭШИРОВАНИЕ:
- 1TB RAM, но кэш не справляется
- Нужен анализ hit ratio буферного кэша PostgreSQL
3. ДИСПРОПОРЦИЯ:
- 192 CPU ядра vs IO bottleneck
- Ресурсы CPU простаивают из-за ожидания диска
Рекомендации для немедленных действий:
Диагностика :
-- 1. Топ таблиц по чтению
SELECT schemaname, relname, seq_scan, seq_tup_read,
idx_scan, idx_tup_fetch
FROM pg_stat_user_tables
ORDER BY seq_tup_read + idx_tup_fetch DESC LIMIT 10;
-- 2. Hit ratio буферного кэша
SELECT sum(heap_blks_read) as heap_read,
sum(heap_blks_hit) as heap_hit,
sum(heap_blks_hit) / (sum(heap_blks_hit) + sum(heap_blks_read)) as ratio
FROM pg_statio_user_tables;
Быстрые исправления:
1. Включить параллельные запросы:
max_parallel_workers_per_gather = 4
parallel_tuple_cost = 0.01
parallel_setup_cost = 100
2. Увеличить shared_buffers:
shared_buffers = 384GB (40% от 1TB)
3. Проверить индексы:
CREATE INDEX CONCURRENTLY ... WHERE нужны
ANALYZE проблемные таблицы
Аппаратные рекомендации:
SSD → проверить:
- RAID controller cache
- Filesystem (XFS с большим readahead)
- Linux I/O scheduler (deadline или none для SSD)
Итог:
Система страдает от случайного чтения, которое не кэшируется эффективно. Проблема на 80% в настройках/запросах, на 20% в аппаратных ограничениях. WAL диск в порядке.
3. Анализ использования памяти
3.1. Память ОС:
Почему свободной RAM <5%, но swap не используется?
Метрики:
- RAM всего: 1031766 MB ≈ 1007 GB
- Свободно: 13096-13231 MB ≈ 13 GB (1.3%)
- Swap in/out: 0
Причины:
1. Оптимальное использование Linux memory management:
# Linux использует свободную память для:
- Page cache: ~720 GB (68% от RAM) ← главный потребитель
- Buffers: ~1.8 GB (0.17%)
- Приложения (PostgreSQL): ~251 GB shared_buffers + другие
2. Swap не используется потому что:
Нет давления памяти (memory pressure) - система успешно управляет кэшем
Кэш вытесняется при необходимости без swap
Swap настроен (общий swap: 5GB + 48GB + 48GB = 101GB), но не нужен
3. Это НОРМАЛЬНОЕ поведение для Linux:
"Свободная память = потраченная память" в Linux
Кэш автоматически освобождается при запросе от приложений
Лучший показатель - отсутствие swap, не объем свободной памяти
Распределение между буферами и кэшем:
- memory_buff: 1776-1837 MB ≈ 1.8 GB (постоянно)
- memory_cache: 718333-720699 MB ≈ 702-704 GB (флуктуирует)
Соотношение:
- Кэш (Cache): 99.7% от общей используемой памяти ОС
- Буферы (Buffers): 0.3%
- Это паттерн PostgreSQL-системы: данные активно кэшируются на уровне ОС
3.2. Память PostgreSQL:
Соответствие настроек объёму RAM (1007 GB):
1. shared_buffers = 251807 MB ≈ 251 GB
Оценка:
- Рекомендация: 25-40% от RAM = 252-403 GB
- Текущее: 251 GB (25%) - в нижней границе нормы
- Проблема: при 1TB данных (суммарно по дискам) и random read - можно увеличить
2. work_mem = 1 GB
Оценка:
- СЛИШКОМ ВЫСОКО для системы с 192 ядрами
- Риск: 100 параллельных запросов × 1GB = 100GB (10% RAM)
- Рекомендация: 64-256 MB при большом количестве соединений
3. maintenance_work_mem = 16 GB
Оценка:
- Рекомендация: 5-10% от RAM = 50-100 GB
- Текущее: 1.6% - МАЛО для обслуживания больших таблиц
- Можно увеличить до 32-64 GB для VACUUM, CREATE INDEX
4. autovacuum_work_mem = 2 GB
Оценка:
- Рекомендуется: 1-2 GB нормально
- Но при 4 autovacuum workers суммарно 8 GB
Агрессивность autovacuum:
Настройки:
1. autovacuum_vacuum_scale_factor = 0.001 (0.1% изменений)
2. autovacuum_analyze_scale_factor = 0.005 (0.5% изменений)
3. autovacuum_vacuum_cost_delay = 2ms (очень агрессивно)
4. autovacuum_max_workers = 4
5. autovacuum_naptime = 1s (очень часто)
Оценка агрессивности:
✅ ХОРОШО для:
- Систем с высокой частотой изменений
- Предотвращения bloat
❌ ПЛОХО для:
- Больших таблиц (1% от 1TB = 10GB изменений для запуска vacuum)
- IO bottleneck (дополнительная нагрузка на диски)
- Конкуренция с рабочей нагрузкой
Рекомендации по autovacuum:
# Для системы с IO проблемами:
autovacuum_vacuum_scale_factor = 0.01 # 1% вместо 0.1%
autovacuum_vacuum_cost_delay = 10ms # уменьшить агрессивность
autovacuum_naptime = 30s # реже проверять
3.3. Корреляция с IO:
Почему высокая корреляция buff/cache ↔ чтение (r/s)?
Числа:
- buff ↔ r/s: 0.77-0.87 (очень высокая)
- cache ↔ r/s: 0.86-0.87 (очень высокая)
Интерпретация:
- Прямая линейная зависимость = система кэширует то, что читает
- Каждое чтение с диска помещается в кэш → кэш работает как буфер
- НЕТ эффективности кэширования при повторных чтениях:
Идеальный кэш: повторные чтения не увеличивают r/s
Наша система: каждое чтение увеличивает использование кэша
Аналогия:
- Хороший кэш: библиотекарь берет книгу с полки (кэш)
- Наш кэш: библиотекарь каждый раз ходит в хранилище (диск), приносит книгу и ставит на полку, но книга больше не нужна
Почему отрицательная корреляция buff/cache ↔ запись (w/s)?
Числа:
- buff ↔ w/s: -0.93 - -0.96 (сильная отрицательная)
- cache ↔ w/s: -0.96 - -0.97 (сильная отрицательная)
Интерпретация:
- Запись НЕ зависит от объема кэша
- Возможные механизмы:
Write-through кэширование: данные пишутся сразу на диск, минуя кэш
Direct I/O: PostgreSQL использует O_DIRECT для данных
WAL-ориентированная архитектура: запись в WAL, а данные page cache вытесняются
Важный вывод: система оптимизирована для записи, но не для чтения
Это неэффективность кэширования или высокая нагрузка на чтение?
ОБА фактора, но доминирует:
1. Неэффективность кэширования (70%):
Признаки:
- Объем кэша ~704 GB
- Активно используемый рабочий набор данных > 704 GB
- Random read паттерн → низкая локальность
- Нет повторного использования данных
Доказательства:
- Кэш заполнен на 99%, но r/s остаются высокими
- Каждое чтение требует обращения к диску
- Отсутствие плато в корреляции (линейный рост)
2. Высокая нагрузка на чтение (30%):
Признаки:
- r/s = 7,100-7,988 на диск
- Суммарно > 30,000 IOPS чтения
- Паттерн: аналитические запросы, отчеты
Итоговая диагностика:
Система работает с рабочим набором данных, который:
1. НЕ помещается в кэш (>700 GB)
2. Доступ к нему случайный (random read)
3. Мало повторных чтений (одноразовые запросы)
Это типично для:
- OLAP/аналитических нагрузок
- Полных сканирований больших таблиц
- Отчетов по неиндексированным полям
Рекомендации по оптимизации памяти:
Immediate :
-- 1. Уменьшить work_mem для предотвращения взрывного использования
ALTER SYSTEM SET work_mem = '128MB';
-- 2. Увеличить shared_buffers для лучшего кэширования
ALTER SYSTEM SET shared_buffers = '384GB'; -- 38% от RAM
-- 3. Увеличить maintenance_work_mem для VACUUM
ALTER SYSTEM SET maintenance_work_mem = '32GB';
-- 4. Настроить autovacuum менее агрессивно
ALTER SYSTEM SET autovacuum_vacuum_scale_factor = 0.01;
ALTER SYSTEM SET autovacuum_vacuum_cost_delay = '10ms';
Short-term :
1. Анализ hit ratio:
SELECT * FROM pg_statio_user_tables;
SELECT * FROM pg_statio_user_indexes;
2. Разделение данных:
- Горячие данные → табличные пространства на быстрых дисках
- Холодные данные → табличные пространства на отдельных дисках
3. Проверка использования индексов:
- Индексы по часто фильтруемым полям
- Covering indexes для частых SELECT
Long-term :
1. Аппаратное решение:
- NVMe SSD для горячих данных
- Увеличение RAM до 2-3 TB если рабочий набор растет
2. Архитектурные изменения:
- Реплика для отчетов
- Columnar storage для аналитических запросов
- Partitioning по времени
3. Query optimization:
- Materialized views для частых отчетов
- Query rewrite для уменьшения working set
Ключевой вывод:
Память используется оптимально с точки зрения ОС, но рабочий набор данных слишком велик для кэширования. PostgreSQL настроен умеренно, но work_mem опасно высок, а autovacuum слишком агрессивен для текущих IO проблем.
4. Анализ ожиданий PostgreSQL и их связи с инфраструктурой
4.1. Основные типы ожиданий:
Преобладающие wait events (на основе корреляций):
Из данных "WAIT_EVENT_TYPE - VMSTAT CORRELATION":
1. IO-ожидания (доминирующие):
- Анализируются корреляции: IO-wa, IO-b, IO-bi, IO-si, IO-so
- Показатели: отрицательные корреляции с wa, b, bi, si, so
- Вывод: Ожидания IO присутствуют, но не проявляются в стандартных метриках ОС
2. LWLock (Lightweight Lock) ожидания:
- Анализируется: LWLock-us, LWLock-sy
- Показатели: слабая/средняя корреляция LWLock-us (INFO)
- Вывод: Есть конкуренция за легковесные блокировки
3. Отсутствие данных по конкретным wait events PostgreSQL:
- Косвенные признаки через корреляции с vmstat
Связь с категориями ожиданий:
✅ IO-related: Да (основная проблема)
✅ Lock-related: Да (LWLocks)
✅ CPU-related: Нет явных признаков
❌ Memory-related: Нет (swap не используется)
4.2. Связь с системными метриками:
Корреляция wait events ↔ wa (IO wait):
Результаты:
- IO-wa корреляция: -0.1495 (отрицательная/отсутствует) → OK
- IO-b корреляция: 0.0000 (отсутствует) → OK
Парадокс:
1. Диски загружены на 65-69% (%util)
2. Но CPU почти не ждет IO (wa = 1-2%)
3. Корреляция между ожиданиями IO и wa отрицательная
Объяснение:
1. Асинхронный IO в PostgreSQL:
- Использует kaio (kernel async I/O) на Linux
- Процессы не блокируются на IO, продолжают работу
- Ожидания учитываются в wait events СУБД, но не в wa ОС
2. Многопроцессорная архитектура:
- 192 CPU ядра
- Пока одни процессы ждут IO, другие работают
- Общий wa низкий, но отдельные процессы могут ждать
Нагрузка CPU (us, sy) ↔ ожидания в СУБД:
Метрики:
- us (user time): 15-21%
- sy (system time): 4%
- us+sy >80%: 0% наблюдений → OK
Корреляции:
1. us+sy и wa >10%: 0.0000 → CPU не ждет IO
2. us не растет → CPU не узкое место
3. LWLock-us корреляция: слабая/средняя (INFO)
- Конкуренция за CPU из-за блокировок
- Сложные запросы (агрегации, JOINs)
Вывод:
- CPU НЕ является узким местом
- Низкая загрузка CPU (25% в среднем) при высокой IO нагрузке
- CPU простаивает из-за ожидания данных с диска
4.3. Выводы: что является основным узким местом?
Иерархия проблем:
1. ОСНОВНОЕ УЗКОЕ МЕСТО: Диски/IO (80% влияния)
✅ %util >65% на всех дисках данных
✅ aqu_sz >1 (очередь на дисках)
✅ Высокая корреляция wa-util (0.51-0.60)
✅ 30,000+ IOPS чтения суммарно
✅ Низкая загрузка CPU при высокой IO нагрузке
Характер проблемы:
- Случайное чтение (random read)
- Рабочий набор данных не помещается в кэш
- Диски работают на пределе IOPS/пропускной способности
2. ВТОРИЧНАЯ ПРОБЛЕМА: Блокировки в СУБД (15% влияния)
✅ Слабая/средняя корреляция LWLock-us
✅ Высокая корреляция cs-us (0.6535) - конкуренция за ресурсы
✅ max_parallel_workers_per_gather = 0 - отсутствие параллелизма
Характер проблемы:
- Легковесные блокировки (LWLocks)
- Возможно, contention на системных ресурсах (память, IO)
- Отсутствие параллелизма усугубляет блокировки
3. ТРЕТИЧНАЯ ПРОБЛЕМА: Память/кэширование (5% влияния)
✅ Свободной RAM <5% (но это норма для Linux)
✅ Высокая корреляция buff/cache ↔ r/s (0.77-0.87)
✅ 704 GB кэша, но рабочий набор данных больше
Характер проблемы:
- Неэффективное кэширование (одноразовые чтения)
- Большой рабочий набор данных
- shared_buffers (251GB) может быть недостаточно
Исключенные узкие места:
❌ CPU: НЕ проблема
- Загрузка: us 15-21%, sy 4% (низкая)
- 192 ядра простаивают
- wa = 1-2% (CPU почти не ждет IO)
❌ Память (дефицит): НЕ проблема
- Swap не используется
- Кэш активно работает
- ОС успешно управляет памятью
❌ Сеть: НЕТ данных
- В метриках не представлена
- Не анализировалась
Диагностическое дерево решений:
Если:
1. %util >65% ✅
2. aqu_sz >1 ✅
3. wa низкий (1-2%) ✅
4. CPU простаивает ✅
5. Кэш заполнен, но r/s высокие ✅
То:
ОСНОВНАЯ ПРОБЛЕМА: Дисковый IO
Подтип проблемы:
- Не хватает IOPS для random read
- Рабочий набор > доступного кэша
- Паттерн доступа: аналитические запросы, полные сканирования
Итог:
Основное узкое место: Дисковый IO для случайного чтения
Вторичная проблема: Блокировки в СУБД (LWLocks)
Решение:
- Немедленно: Оптимизация запросов, добавление индексов, включение параллелизма
- Краткосрочно: Увеличение shared_buffers, настройка autovacuum
- Долгосрочно: Аппаратное улучшение (NVMe SSD), пересмотр архитектуры доступа к данным
CPU и память не являются ограничивающими факторами в текущей конфигурации.
5. Сводный отчёт и рекомендации
5.1. Ключевые проблемы (приоритетно)
КРИТИЧЕСКИЕ (требуют немедленного вмешательства):
1. Дисковый IO - основное узкое место
- Диски данных (vdh, vdi, vdj, vdk) загружены на 65-69% постоянно
- Очередь запросов >1 на каждом диске (aqu_sz = 1.19-1.32)
- 30,000+ IOPS случайного чтения суммарно
- Влияние: задержка выполнения всех запросов
2. Неэффективное кэширование рабочего набора данных
- 704 GB кэша ОС + 251 GB shared_buffers недостаточно
- Рабочий набор данных > 1 TB, доступ случайный
- Каждое чтение требует физического обращения к диску
ВЫСОКИЙ ПРИОРИТЕТ:
3. Отсутствие параллелизма при 192 ядрах CPU
- max_parallel_workers_per_gather = 0
- CPU простаивает (us 15-21%, sy 4%) из-за IO ожиданий
4. Слишком агрессивные настройки autovacuum
- autovacuum_vacuum_scale_factor = 0.001 (0.1% изменений)
- autovacuum_naptime = 1s (постоянная активность)
- Дополнительная нагрузка на проблемные диски
СРЕДНИЙ ПРИОРИТЕТ:
5. Опасно высокий work_mem
- work_mem = 1GB при возможных сотнях соединений
- Риск: 100 запросов × 1GB = 100GB памяти
6. Потенциальные блокировки (LWLocks)
- Слабая/средняя корреляция LWLock-us
- Возможная конкуренция за системные ресурсы
5.2. Рекомендации по настройке PostgreSQL
Изменения в postgresql.auto.conf:
Память (немедленно):
work_mem = 128MB # уменьшить с 1GB
maintenance_work_mem = 32GB # увеличить с 16GB
shared_buffers = 384GB # увеличить с 251GB (38% RAM)
autovacuum_work_mem = 1GB # уменьшить с 2GB
Параллельные запросы (немедленно):
max_parallel_workers_per_gather = 4 # включить параллелизм
parallel_tuple_cost = 0.01 # снизить стоимость параллелизма
parallel_setup_cost = 100 # снизить стоимость запуска
max_parallel_maintenance_workers = 8 # уменьшить с 20
Autovacuum (немедленно):
autovacuum_vacuum_scale_factor = 0.01 # 1% вместо 0.1%
autovacuum_analyze_scale_factor = 0.1 # 10% вместо 0.5%
autovacuum_vacuum_cost_delay = 10ms # уменьшить агрессивность
autovacuum_naptime = 30s # увеличить интервал проверки
Другие важные настройки:
statement_timeout = 30min # уменьшить с 64h
log_min_duration_statement = 10s # логировать медленные запросы
effective_cache_size = 700GB # скорректировать с 747GB
5.3. Рекомендации по инфраструктуре
Диски:
ТРЕБУЮТСЯ более быстрые диски:
- Текущая проблема: случайное чтение, высокий IOPS
- Рекомендация: NVMe SSD для данных
- Альтернатива: увеличение кэша контроллера
- Срочность: высокий приоритет (1-3 месяца)
Память:
ДОСТАТОЧНО, но можно оптимизировать:
- 1TB RAM достаточно для текущей нагрузки
- Проблема: неэффективное распределение
- Рекомендация: увеличить shared_buffers до 384GB
- Дополнительно: мониторинг hit ratio
CPU:
БОЛЕЕ ЧЕМ ДОСТАТОЧНО:
- 192 ядра при загрузке 20-25%
- Проблема: простаивают из-за IO
- Решение: включить параллелизм запросов
Оптимизация ОС:
# Файловая система:
mount -o noatime,nodiratime,nobarrier,allocsize=64k
# I/O scheduler для SSD:
echo deadline > /sys/block/vdh/queue/scheduler
# VM параметры:
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
vm.swappiness = 10
5.4. Следующие шаги
Для администратора БД :
1. Немедленные изменения:
-- Включить параллельные запросы
ALTER SYSTEM SET max_parallel_workers_per_gather = 4;
-- Уменьшить work_mem
ALTER SYSTEM SET work_mem = '128MB';
-- Скорректировать autovacuum
ALTER SYSTEM SET autovacuum_vacuum_scale_factor = 0.01;
-- Перезагрузить конфигурацию
SELECT pg_reload_conf();
2. Диагностика :
-- Запустить сбор статистики запросов
-- Анализ индексов
SELECT schemaname, tablename, indexname,
idx_scan, idx_tup_read, idx_tup_fetch
FROM pg_stat_user_indexes
WHERE idx_scan < 100 -- редко используемые индексы
ORDER BY idx_scan;
3. Оптимизация (неделя 1):
- Проанализировать и переписать top-5 самых "тяжелых" запросов
- Добавить индексы по часто используемым фильтрам
- Рассмотреть partitioning для больших таблиц
- Настроить материализованные представления для отчетов
Для системного администратора:
1. Немедленно :
# Оптимизировать настройки файловой системы
tune2fs -O dir_index /dev/vdh1
# Настроить readahead
blockdev --setra 16384 /dev/vdh
# Проверить и оптимизировать параметры ядра
sysctl -w vm.dirty_background_ratio=5
sysctl -w vm.dirty_ratio=10
2. Краткосрочные действия (неделя 1):
- Проанализировать возможность перехода на NVMe SSD
- Настроить мониторинг latency дисков
- Оптимизировать RAID конфигурацию (рассмотреть RAID 10)
3. Долгосрочные действия (месяц 1-3):
- План апгрейда дисковой подсистемы
- Настройка реплики для отчетов
- Внедрение продвинутого мониторинга (Prometheus, Grafana)
Совместные действия:
Неделя 1:
1. Встреча для обсуждения
2. Приоритизация запросов для оптимизации
3. План нагрузочного тестирования после изменений
Неделя 2:
1. Анализ результатов изменений
2. Корректировка плана оптимизации
3. Начало работ по аппаратному апгрейду
Месяц 1:
1. Полная оценка производительности
2. Документирование лучших практик
3. План регулярных проверок производительности
Критический путь:
День 1-2: Изменение настроек PostgreSQL, анализ запросов
День 3-5: Оптимизация запросов, добавление индексов
Неделя 2: Нагрузочное тестирование, оценка улучшений
Неделя 3-4: Подготовка к аппаратным изменениям
Месяц 2-3: Апгрейд дисков, окончательная оптимизация
Ожидаемые результаты:
- Уменьшение времени выполнения запросов: 30-50%
- Снижение нагрузки на диски: %util с 65% до 40-50%
- Улучшение использования CPU: увеличение до 40-50%
- Повышение hit ratio буферного кэша: с текущего до 85-90%
Итог:
Система имеет значительный потенциал для оптимизации. Приоритет - оптимизация запросов и включение параллелизма для использования простаивающих CPU. Аппаратный апгрейд дисков необходим в среднесрочной перспективе.