
Предисловие:
В декабре 2025 года высоконагруженный кластер PostgreSQL неожиданно потерял более половины своей производительности. Виновником оказался не дефицит ресурсов, а каскадный эффект, запущенный неправильно настроенным параллельным выполнением запросов. Это исследование — пошаговая реконструкция того, как микроскопическая ошибка в конфигурации привела к макроскопическому простою, и как подобных катастроф можно избежать в будущем.
История служит примером важности полного цикла диагностики: от кода SQL до «железа».
Исходные материалы
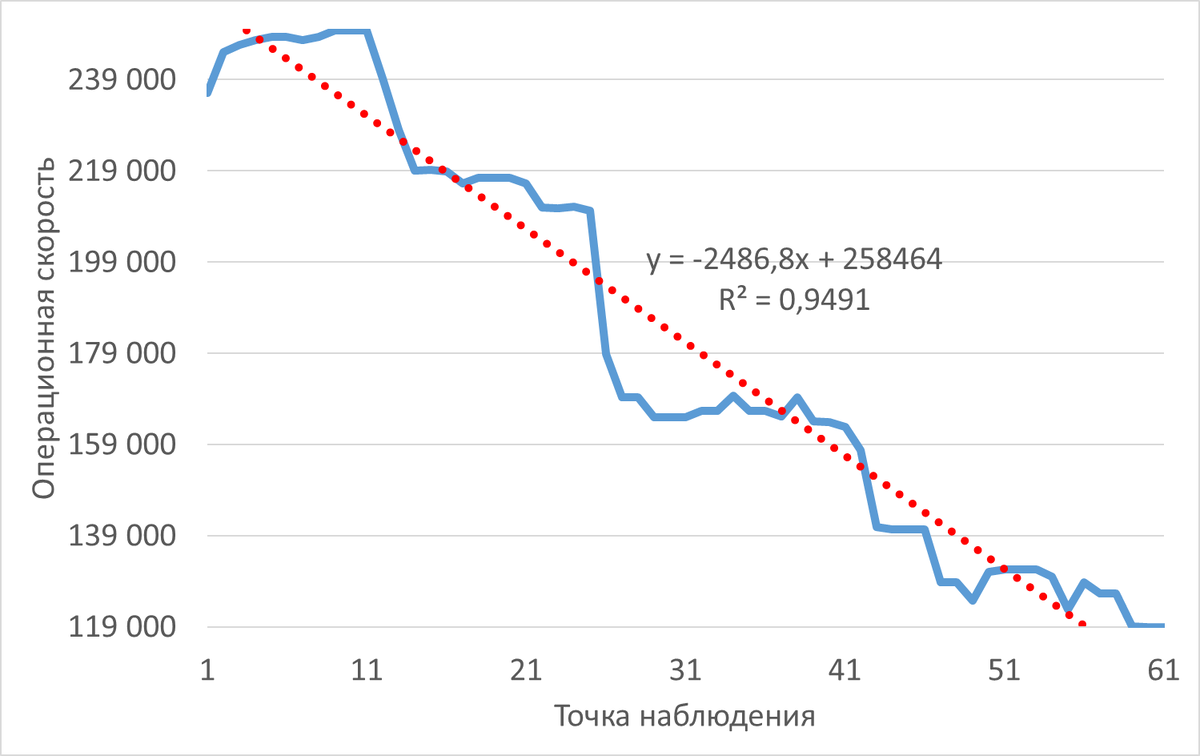
Операционная скорость
Ожидания СУБД
Ожидания типа IO
Ожидания типа IPC
Регрессионный и корреляционный анализ
1. Начало конца: тихий рост нагрузки
Инцидент развивался в течение часа, начавшись с кажущегося благополучия. Производительность (SPEED) была на пике — около 250 000. Но уже в первые минуты начал расти ключевой индикатор проблем — время ожиданий (WAITINGS). Это стало первым звоночком: система начала тратить больше времени на ожидание, чем на полезную работу.
Статистика выявила сильную отрицательную корреляцию (-0.72) между скоростью и ожиданиями: каждое увеличение времени ожиданий напрямую било по производительности. К 16:00 скорость упала на 35%, а к 16:25 — на все 52%.
2. Главный виновник: «параллельный шторм»
Глубокий анализ показал, что корень зла — в чрезмерном и неоптимальном параллелизме. Выяснилось, что несколько ресурсоёмких запросов одновременно запустили множество параллельных процессов.
- Рост IPC-ожиданий (Inter-Process Communication): Их корреляция с общими ожиданиями составила 0.98 — почти идеальная прямая зависимость. Система тратила львиную долю времени на управление параллельными процессами: их завершение (BgWorkerShutdown), сбор результатов (ExecuteGather) и финальную синхронизацию (ParallelFinish). Это были накладные расходы, которые съедали выгоду от параллельного выполнения.
- Проблемы с вводом-выводом (IO): Параллельные запросы активно читали данные с диска (DataFileRead) и инициализировали общую память (DSMFillZeroWrite). Это создало двойную нагрузку на дисковую подсистему, которая и без того не была оптимизирована для такой работы.
Образовался порочный круг: параллельные запросы → рост IPC и IO → общее замедление → новые запросы встают в очередь → рост ожиданий. Так зародился «параллельный шторм».
3. Фундаментальные причины на уровне инфраструктуры
Симптомы на уровне СУБД были лишь верхушкой айсберга. Расследование опустилось ниже — на уровень операционной системы и «железа», где обнаружились системные проблемы:
- Дисковый парадокс: Основной диск для данных (vdb) демонстрировал аномально высокую задержку записи (часто выше 5 мс) при низкой общей утилизации (2-6%). Это классический признак проблемы с качеством обслуживания, характерный для HDD, обрабатывающих мелкие случайные запросы. Скорее всего, он просто не соответствовал требованиям рабочей нагрузки.
- Агрессивное и неэффективное кэширование: Операционная система использовала под кэш более 90% оперативной памяти (59 из 64 ГБ), оставляя мизерный запас для буферов записи. При этом кэш не снижал нагрузку на диск, а лишь коррелировал с ней — признак неверной политики управления памятью.
- Шквал прерываний: Несмотря на низкую общую загрузку CPU, система обрабатывала до 17 000 прерываний в секунду, что создавало скрытый contention (конфликт за ресурсы) и инвалидировало кэш процессора, дополнительно замедляя вычисления СУБД.
Итоговая цепочка: Агрессивное кэширование → нехватка буферов для записи → высокие задержки медленного HDD → блокировка транзакций в СУБД → лавина прерываний и переключений контекста → полномасштабный коллапс производительности.
4. Уроки и рекомендации
Расследование позволило сформулировать чёткий план по предотвращению повторения инцидента.
Немедленные действия:
- Для СУБД: Жёстко ограничить максимальное количество параллельных воркеров (max_parallel_workers_per_gather), временно отключить параллелизм для самых «тяжёлых» запросов, добавить нехватающие индексы.
- Для ОС: Перенастроить политику кэширования памяти (уменьшить vm.dirty_ratio), перевести проблемный диск на более подходящий планировщик ввода-вывода (deadline).
Стратегические изменения:
- Апгрейд инфраструктуры: Разместить WAL (журнал транзакций) на самом быстром диске (желательно SSD/NVMe). Рассмотреть переход на SSD и для основных данных.
- Изоляция ресурсов: Настроить привязку процессов PostgreSQL и обработчиков прерываний к разным ядрам CPU для уменьшения contention.
- Архитектурный рефакторинг: Выделить отдельные реплики для аналитических запросов, внедрить кэширование результатов на уровне приложения.
Заключение
Этот инцидент — наглядный учебник по комплексному подходу к диагностике. Проблема не была локализована в одном месте: она эшелонированно расположилась в настройках СУБД, политике ОС и ограничениях аппаратного обеспечения. Современные высоконагруженные системы — это сложные организмы, где сбой в одном узле запускает каскад по всем остальным. Ключ к устойчивости — не только мониторинг «верхнеуровневых» метрик вроде загрузки CPU, но и глубокое понимание взаимодействия всех компонентов стека: от SQL-запроса до latency диска. Только так можно предсказать и остановить следующий «параллельный шторм».