От гигантского космического корабля до звёздного флота: как самые крутые IT-компании мира разбивают свои программы на атомы, чтобы они не сломались под вашим вниманием
Представьте, что вам нужно запустить в производство новый, невероятно популярный смартфон. У вас есть выбор. Первый вариант: построить один гигантский, невероятно сложный завод-робот. На входе — песок и пластик, на выходе через сотни этапов — готовый телефон. Если в этом монолите сломается конвейер по производству дисплеев, встанет всё: и сборка корпуса, и упаковка, и логистика. Чтобы добавить новую камеру, придётся останавливать и перестраивать всё предприятие целиком. Второй вариант: построить городок из небольших, умных и самостоятельных цехов. Один делает только экраны, другой — только процессоры, третий — камеры, четвёртый — аккумуляторы. Они чётко договорились, как общаться друг с другом, и финальная линия просто собирает готовые модули. Сломался цех камер? Остальные продолжают работать, а проблему можно быстро исправить в одном месте. Меняется технология экранов? Перестраивается только один цех, не трогая остальные. Здравый смысл подсказывает, что второй путь надёжнее и гибче.
Именно по этому второму пути в последнее десятилетие пошли все ведущие технологические компании мира, создавая свои самые нагруженные и сложные системы — от Netflix и Uber до Spotify и «Сбера». Этот подход называется микросервисной архитектурой, и сегодня мы разберём её по кирпичикам так, чтобы стало понятно даже тому, кто далёк от программирования.
Монолит, который всем надоел: а что было до этого?
Чтобы понять, зачем вообще понадобились микросервисы, нужно взглянуть на то, что им предшествовало. На протяжении десятилетий стандартом де-факто была монолитная архитектура. По сути, это один большой, единый кусок программы. Представьте интернет-магазин. В монолите все его части — каталог товаров, корзина покупателя, система оплаты, личный кабинет, служба доставки — это один огромный программный «комок», который работает как единое целое. Его пишет одна большая команда разработчиков на одном стеке технологий, он компилируется и запускается целиком.
В этом есть своя простота на старте. Но представьте, что этот магазин стал очень популярным. И вот что начинается:
- Проблема масштаба. Чтобы выдержать нагрузку тысяч покупателей, нужно запустить копию всего монолита на десятках серверов. Даже если нагрузка высока только на каталог, вы всё равно умножаете всё: и корзину, и оплату, и личный кабинет. Это как если бы для увеличения пропускной способности столовой вам пришлось клонировать не только поваров, но и кассу, уборщиц и гардероб.
- Проблема изменений. Хотите обновить дизайн кнопки в корзине? Вам нужно заново собрать, протестировать и развернуть весь монолит целиком. Исправление крошечной ошибки в модуле доставки может случайно сломать систему оплаты, потому что всё связано в одном котле.
- Проблема технологического стека. Вся команда обязана использовать один язык программирования (например, Java) и одну базу данных, даже если для какой-то задачи гораздо лучше подошёл бы, скажем, Python или специальная СУБД для графиков.
Именно эти «боли» гигантов вроде Amazon и Netflix в середине 2000-х и привели к рождению идеи: а что если разбить этот монолит на множество маленьких, независимых сервисов?
Суть микросервисов: один сервис — одна ответственность
Если монолит — это швейцарский армейский нож с десятком инструментов в одной рукоятке, то микросервисная архитектура — это профессиональный ящик с инструментами, где каждый инструмент (сервис) делает только одну работу, но делает её блестяще.
Микросервис — это автономная, независимо разворачиваемая программа, которая реализует одну конкретную бизнес-возможность и общается с другими такими же сервисами через чёткие, лёгкие протоколы (чаще всего HTTP/REST или gRPC).
Давайте снова вернёмся к нашему интернет-магазину, но теперь представим его как набор микросервисов.
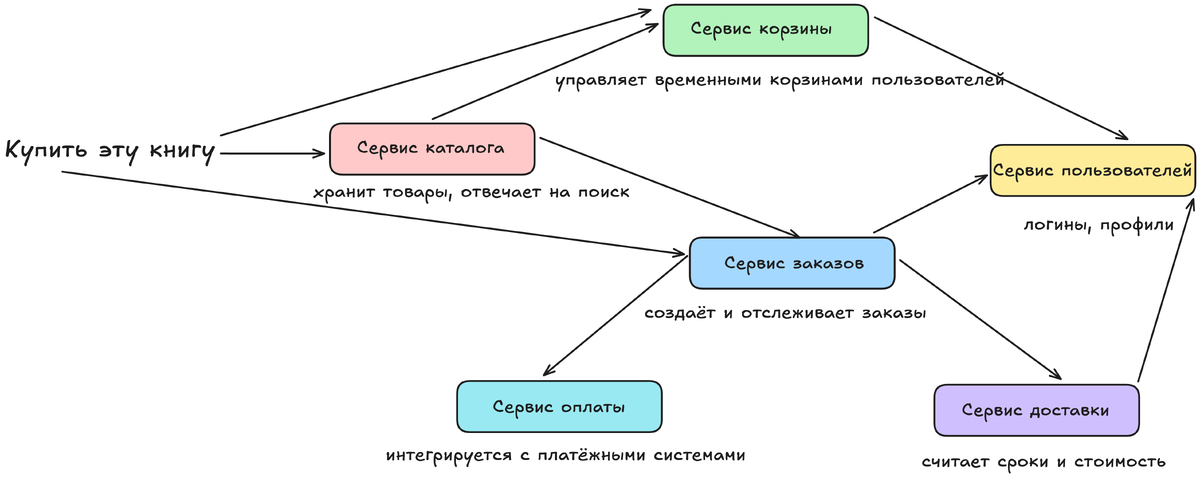
Сервис каталога только и делает, что отвечает на вопросы «покажи все книги» или «найди синюю футболку XL». Он ничего не знает о корзинах и платежах. Если покупатель нажимает «добавить в корзину», фронтенд (приложение или сайт) отправляет запрос уже в сервис корзины. Тот в свою очередь, чтобы показать актуальную цену, может отправить внутренний запрос в сервис каталога: «Какова цена товара с ID=12345?». Когда пользователь нажимает «оформить заказ», в дело вступает сервис заказов, который координирует работу: создаст запись о заказе, попросит сервис оплаты списать деньги, а после успешной оплаты отправит событие в сервис доставки.
Эти сервисы не делятся одной общей базой данных. У каждого своя, приватная база данных или схема хранения. Сервис корзины хранит только данные о корзинах, сервис заказов — только о заказах. Чтобы получить информацию, они общаются друг с другом через API, а не лезут прямо в чужую базу. Это обеспечивает связность внутри сервиса и слабую связанность между сервисами — краеугольный камень архитектуры.
Чем они общаются? Язык событий и сообщений
Как же эти независимые сервисы координируют сложные процессы, такие как оформление заказа? Существует два основных паттерна.
Первый — синхронное взаимодействие по HTTP (REST/GRPC). Это как телефонный звонок. Сервис А звонит (отправляет HTTP-запрос) сервису Б и ждёт, пока тот ответит, чтобы продолжить работу. «Эй, Сервис оплаты, списать 100 рублей с карты X?» — «Да, списал» — «Отлично, теперь иду создавать доставку».
Но представьте, что сервис оплаты временно недоступен. Весь процесс оформления заказа встанет. Чтобы избежать этого, используют второй, более гибкий подход — асинхронное взаимодействие через брокер сообщений (Message Broker). Представьте почтовое отделение или очередь. Сервис А не звонит напрямую, а оставляет сообщение в определённой «очереди» или «топике» (почтовом ящике) на специальном сервере-брокере, таком как RabbitMQ, Apache Kafka или NATS. И спокойно идёт дальше, не дожидаясь ответа.
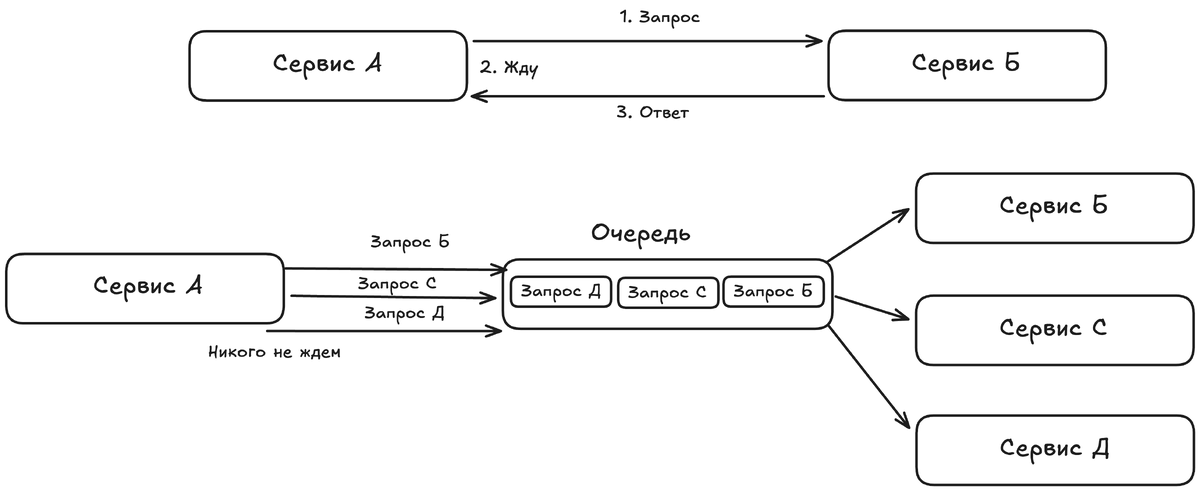
Сервис Б подписан на эту очередь, забирает сообщения, когда готов, и обрабатывает их. Например, после создания заказа сервис заказов публикует событие «Заказ №456 создан» в очередь orders.created. На это событие независимо друг от друга могут отреагировать: сервис нотификаций (отправит письмо «Заказ принят!»), сервис аналитики (запишет статистику) и сервис склада (запустит процесс комплектации). Если сервис нотификаций упадёт на час, сообщения просто накопятся в очереди и будут доставлены, когда он оживёт. Система в целом останется работоспособной.
Магия независимости: как это меняет жизнь разработки
Вот на этом этапе и раскрывается вся магия подхода, ради которого идут на его огромную изначальную сложность.
- Независимое развертывание и масштабирование. Это самый большой козырь. У вас началась распродажа, и нагрузка на сервис каталога взлетела в 100 раз? Без проблем! Вы запускаете дополнительные 50 экземпляров только сервиса каталога, не трогая сервисы корзины, оплаты и доставки. Это называется горизонтальное масштабирование, и оно становится адресным и дешёвым. Каждый сервис можно обновлять и выкатывать в продакшен десятки раз в день, независимо от других.
- Технологическая свобода. Сервис машинного обучения для рекомендаций товаров можно написать на Python, потому что для этого он идеально подходит. Высоконагруженный сервис ценообразования — на Go или Rust. Сервис для сложных транзакций — на Java. Каждая команда выбирает лучший инструмент для своей конкретной задачи.
- Устойчивость к сбоям. Благодаря асинхронной связи и чёткой изоляции, выход из строя одного сервиса не должен обрушивать всю систему. Можно реализовать паттерны («автоматический выключатель»), который при множественных ошибках сервиса оплаты временно «разрывает цепь» и не дергает его, возвращая пользователю заглушку «платёжная система временно недоступна, попробуйте позже», пока остальные функции магазина работают. Это в разы лучше, чем «ошибка 500» на всей странице.
Обратная сторона медали: сложность, которая взрывает мозг
Переход на микросервисы — это не простая модернизация. Это смена всей парадигмы разработки и эксплуатации, и цена за гибкость очень высока.
Распределённый монстр. Если в монолите была одна точка входа и одна база данных, то здесь у вас десятки, сотни разрозненных сервисов. Как их все отслеживать? Как понять, почему тормозит процесс оформления заказа, если он проходит через 5 разных сервисов? Для этого нужна целая экосистема дополнительных инструментов: Service Discovery (чтобы сервисы находили друг друга в динамическом облаке), Tracing (распределённая трассировка запросов, например, Jaeger или Zipkin), Centralized Logging (централизованный сбор логов, например, в ELK-стек), Мониторинг (панели в Grafana).
Сложность тестирования и отладки. Протестировать монолит можно, просто запустив его локально. Как протестировать сценарий, который затрагивает 10 микросервисов? Для этого строят сложные стенды, используют consumer-driven contracts и симуляторы.
Проблемы с согласованностью данных. В монолите одна транзакция в базе данных гарантировала, что и заказ создан, и оплата прошла, и резерв на складе снят. В мире микросервисов, где у каждого своя база, эта атомарность исчезает. Приходится применять сложные компенсирующие транзакции (Saga Pattern): если после списания денег не удалось создать доставку, нужно запустить откат — вернуть деньги. Это сложная логика.
Именно поэтому мантра опытных архитекторов звучит так: «Не начинайте с микросервисов!». Для стартапа с одной командой и непонятным продуктом монолит — идеальный и быстрый выбор. Микросервисы становятся оправданы, когда у вас есть несколько автономных команд (по модели Конвея), понятные границы сервисов (по бизнес-доменам) и реальные проблемы с масштабированием монолита. Это эволюция, а не революция с чистого листа.
Понимание микросервисов — это понимание того, как устроена современная, высоконагруженная цифровая экосистема. Это взгляд под капот того, почему ваше приложение так быстро обновляется, почему скидки на AliExpress появляются одновременно у миллионов и почему гигантские системы не рассыпаются под всеобщим вниманием. Это архитектура не для простоты, а для контроля над сверхсложностью.
👍 Ставьте лайки если хотите разбор других интересных тем.
👉 Подписывайся на IT Extra на Дзен чтобы не пропустить следующие статьи
Если вам интересно копать глубже, разбирать реальные кейсы и получать знания, которых нет в открытом доступе — вам в IT Extra Premium.
Что внутри?
✅ Закрытые публикации: Детальные руководства, разборы сложных тем (например, архитектура высоконагруженных систем, глубокий анализ уязвимостей, оптимизация кода, полезные инструменты объяснения сложных тем простым и понятным языком).
✅ Конкретные инструкции: Пошаговые мануалы, которые вы сможете применить на практике уже сегодня.
✅ Без рекламы и воды: Только суть, только концентрат полезной информации.
✅ Ранний доступ: Читайте новые материалы первыми.
Это — ваш личный доступ к экспертизе, упакованной в понятный формат. Не просто теория, а инструменты для роста.
👉 Переходите на Premium и начните читать то, о чем другие только догадываются.
👇
Понравилась статья? В нашем Telegram-канале ITextra мы каждый день делимся такими же понятными объяснениями, а также свежими новостями и полезными инструментами. Подписывайтесь, чтобы прокачивать свои IT-знания всего за 2 минуты в день!