Отслеживание посылок, ленты соцсетей и биржевые торги — что общего? Ключевая технология для потоков данных, которая незаметно связывает весь цифровой мир. Объясняем на пальцах и без кода, как работает эта «нервная система» для приложений.
Представьте, что вам нужно организовать работу почтового сортировочного центра в день гигантской распродажи. Миллионы посылок приезжают каждую секунду от разных магазинов. Их нужно моментально рассортировать по городам, отправить в нужные фургоны для доставки, а ещё — вести точный журнал: какая посылка куда уехала, чтобы в случае проблемы всё можно было восстановить. При этом некоторые «посылки» (например, уведомления о скидке) нужно разослать сразу всем клиентам в городе. Примерно такую же задачу в мире софта решает Apache Kafka. Это не база данных и не обычная очередь сообщений. Это высокопроизводительная, отказоустойчивая и масштабируемая платформа для потоковой передачи событий в реальном времени, которая стала промышленным стандартом для построения современных data-driven приложений. Если говорить простыми словами, Kafka — это центральная «нервная система» для данных, которая позволяет десяткам и сотням разных программ обмениваться информацией быстро, надёжно и без потерь. Давайте разберёмся, как она устроена, на понятных аналогиях и почему без неё не могут обойтись ни Netflix, ни Uber, ни ваш банк.
Зачем это нужно? Или что не так со старым способом?
Давайте начнём с боли, которую Kafka лечит. Раньше, когда одной программе (например, сайту интернет-магазина) нужно было отправить данные другой (например, сервису рассылки email-чеков), они общались напрямую. Сайт просто вызывал API сервиса рассылки. Казалось бы, что тут плохого?
Представьте нашу аналогию: каждый магазин (программа-отправитель) нанимает своего личного курьера (прямое соединение) для каждой посылки каждому клиенту (программе-получателю). Что получается?
- Хаос и хрупкость: Если сервис рассылки «лег» на пять минут, все заказы за это время теряются. Сайту придётся их заново отправлять.
- Медленное масштабирование: Если мы захотим добавить ещё один сервис, который анализирует покупки, нам нужно переписать код сайта, чтобы он слал данные и туда тоже.
- Перегрузка отправителя: Сайт тратит свои ресурсы на ожидание ответов от всех сервисов. Это как если бы кассир сам бегал на склад за каждым товаром.
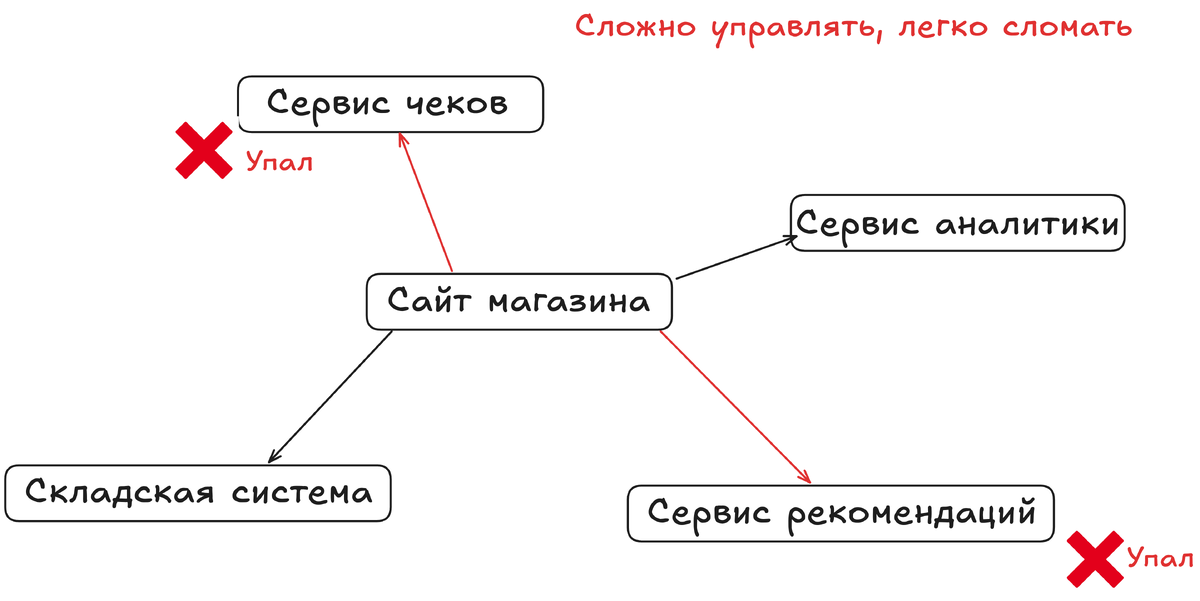
Kafka решает эту проблему радикально. Она становится единым централизованным «посредником» для всех данных. Теперь сайту не нужно знать, кто и как будет обрабатывать заказ. Его задача — просто бросить «посылку» с информацией о покупке (событие) в Kafka и забыть о ней. Дальше Kafka гарантированно сохранит это событие и доставит всем, кому оно интересно. Сайт свободен и может работать дальше.
Основные понятия: разбираем «сортировочный центр» по косточкам
Давайте прогуляемся по нашей аналогии и сопоставим её с реальными терминами Kafka (официальная документация проекта Apache Kafka — наш главный источник).
1. Событие (Event / Message) — это посылка/событие.
Это минимальная порция информации. Например: { "order_id": 12345, "user_id": "ivan_2025", "action": "purchase", "timestamp": "2025-11-20T10:30:00Z" }. Это и есть та самая коробка на конвейере.
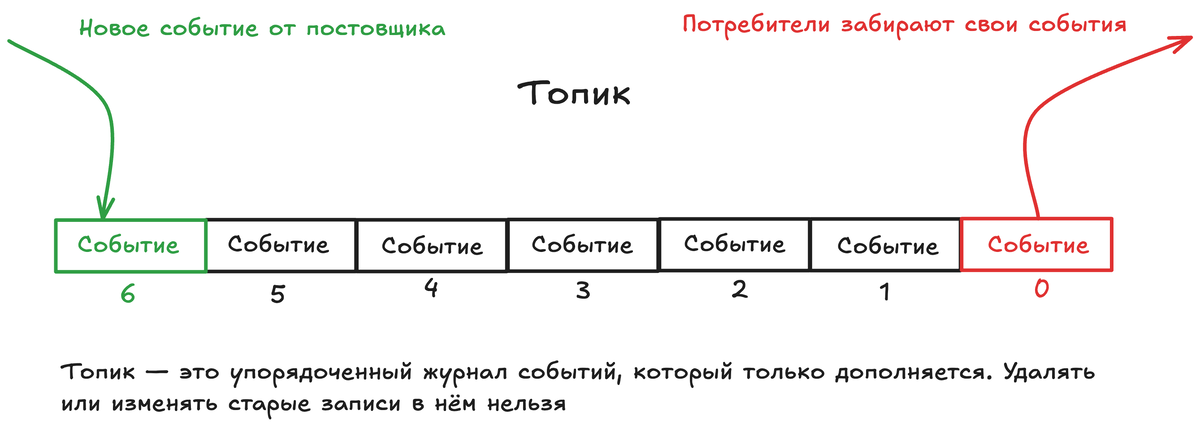
2. Топик (Topic) — это «город назначения» или «тип посылок».
В сортировочном центре посылки летят в разные желоба: «Москва», «Электроника», «Хрупкое». В Kafka события записываются в топики. Это логические категории, именованные потоки данных. Например, могут быть топики user_actions, financial_transactions, server_logs. Все события о действиях пользователей летят в топик user_actions.
3. Продюсер (Producer) — это магазин поставщик, который привозит посылки. Это любое приложение или сервис, которое генерирует события и отправляет (публикует) их в определённый топик Kafka. Наш сайт интернет-магазина — это продюсер для топика user_actions.
4. Консьюмер (Consumer) — это фургон доставки или склад-получатель или потребитель. Это приложение, которое подписывается на один или несколько топиков и читает из них события для своей работы. Сервис отправки чеков — это консьюмер, читающий топик user_actions и ищущий там события с action: "purchase".
5. Брокер (Broker) — это «сортировочный узел» или «рабочий сервер».
Это один сервер (нода) в кластере Kafka. Весь «сортировочный центр» — это кластер, состоящий из нескольких брокеров для надёжности и масштабирования. Данные в топиках распределены между ними.
Секрет скорости и надёжности: Партиции и репликация
Вот мы подобрались к самой магии. Как Kafka выдерживает гигантские нагрузки в миллионы событий в секунду (как, например, в LinkedIn, где она и была создана)?
Представьте, что топик user_actions стал слишком «тяжёлым» — в него пишут 100 тысяч событий в секунду. Один конвейер (брокер) не справляется. Решение Kafka — разбить топик на партиции (partitions).
Offset — это порядковый номер, который уникально идентифицирует каждое сообщение в пределах одной партиции топика.
Партиция — это независимый, упорядоченный подпоток внутри топика.
События в одной партиции гарантированно идут в порядке записи. Но между разными партициями порядка нет — они обрабатываются параллельно. Это как если бы мы в нашем логистическом центре проложили не один широкий конвейер в город, а 4 параллельных узких. Грузовики могут выгружаться на все сразу, и пропускная способность растёт.
Как события распределяются по партициям? По ключу (key). Если у события есть ключ (например, user_id), то все события с одним и тем же ключом всегда попадут в одну и ту же партицию. Это критически важно! Это гарантирует, что все действия одного пользователя будут обработаны в правильной последовательности (ведь они лежат в одной упорядоченной партиции). Если ключа нет, события распределяются по партициям по кругу.
А что, если один из конвейеров (брокеров) сломается? Данные потеряются? Нет, благодаря репликации (replication). Каждая партиция имеет несколько реплик (копий), которые хранятся на разных брокерах. Одна реплика — лидер (leader) — принимает все запросы на запись и чтение. Остальные — последователи (followers) — лишь тихо её копируют. Если брокер-лидер падает, один из последователей мгновенно становится новым лидером, и работа продолжается без остановки и потери данных. Фактор репликации 3 (одна основная копия и две резервные) — это стандарт в индустрии.
Consumer Groups: как работают «бригады грузчиков»
Допустим, топик очень быстрый, и один консьюмер (один фургон) не успевает забирать все посылки. Решение — Consumer Group (группа потребителей).
Это несколько одинаковых консьюмеров, которые работают вместе, чтобы читать один топик. Kafka автоматически и прозрачно распределяет партиции топика между консьюмерами в группе.
Важнейшее правило: Одну партицию в один момент времени читает только один консьюмер из группы. Это гарантирует, что события будут обработаны в порядке их поступления в этой партиции. Если один консьюмер в группе «умирает», его партиции автоматически перераспределяются между оставшимися. Если мы добавим в группу четвёртого консьюмера, партиции перераспределятся снова (кому-то достанется только одна). Это и есть горизонтальное масштабирование обработки данных.
В классических очередях (RabbitMQ) сообщение удаляется после обработки. Kafka же хранит события определённое время (например, 7 дней) или до достижения определённого размера. Это её суперсила. Благодаря этому:
- Можно «отмотать назад». Новый консьюмер может подключиться к топику и прочитать всю его историю за последнюю неделю. Хотите запустить новый сервис аналитики? Он прочитает все прошлые данные и начнёт работать с актуальным состоянием.
- Ошибка — не приговор. Если консьюмер сломался и три дня чинился, он может перечитать события, пропущенные за эти дни.
- Одно событие — много потребителей. На одно и то же событие о покупке могут подписаться десятки независимых сервисов: для чека, аналитики, рекомендаций, обновления бонусного счёта. И каждый будет читать топик в своём собственном темпе, не мешая другим. Этого не позволяет сделать простая очередь.
Где это всё применяется? Не просто «для больших данных»
- Стриминговая аналитика в реальном времени: Мониторинг мошеннических операций в банке. Каждая транзакция — событие в Kafka. Система фрод-детекта читает этот поток и в реальном времени ищет аномалии, блокируя подозрительные платежи за миллисекунды.
- Микросервисная архитектура: Это идеальный «клей» для микросервисов. Когда один сервис что-то делает (например, добавляет товар в корзину), он публикует событие. Другие сервисы (корзина, рекомендации, инвентарь) узнают об этом через Kafka и обновляют свои данные, не вызывая друг друга напрямую.
- Сбор логов и метрик: Все сервера присылают логи в Kafka, а оттуда они расходятся в системы мониторинга (Grafana), долгосрочного хранения (S3) и анализа (Elasticsearch).
- Event Sourcing и CQRS: Продвинутые архитектурные паттерны, где состояние приложения восстанавливается путём воспроизведения всех произошедших с ним событий (которые хранятся в Kafka).
Kafka — это не просто очередной инструмент. Это платформа для построения реактивных, масштабируемых и отказоустойчивых систем, работающих с потоками данных как с первоклассной сущностью. Она превращает хаотичный обмен сообщениями между приложениями в управляемый, надёжный и упорядоченный поток «событий», который можно хранить, переигрывать и масштабировать практически бесконечно. Её парадигма — «логи, которые можно подписывать» — легла в основу современной data-инфраструктуры. Если ваша система выросла из двух серверов и теперь должна обрабатывать миллионы событий от тысяч источников, вы неизбежно придёте к чему-то подобному Kafka. Она — тот самый «сортировочный центр» для цифровой экономики, без которого сегодня не обходится ни один крупный IT-проект.
Переходите к следующему уроку, где мы детально рассмотрим работу Kafka по шагам!
👍 Ставьте лайки если хотите разбор других интересных тем.
👉 Подписывайся на IT Extra на Дзен чтобы не пропустить следующие статьи
Если вам интересно копать глубже, разбирать реальные кейсы и получать знания, которых нет в открытом доступе — вам в IT Extra Premium.
Что внутри?
✅ Закрытые публикации: Детальные руководства, разборы сложных тем (например, архитектура высоконагруженных систем, глубокий анализ уязвимостей, оптимизация кода, полезные инструменты объяснения сложных тем простым и понятным языком).
✅ Конкретные инструкции: Пошаговые мануалы, которые вы сможете применить на практике уже сегодня.
✅ Без рекламы и воды: Только суть, только концентрат полезной информации.
✅ Ранний доступ: Читайте новые материалы первыми.
Это — ваш личный доступ к экспертизе, упакованной в понятный формат. Не просто теория, а инструменты для роста.
👉 Переходите на Premium и начните читать то, о чем другие только догадываются.
👇
Понравилась статья? В нашем Telegram-канале ITextra мы каждый день делимся такими же понятными объяснениями, а также свежими новостями и полезными инструментами. Подписывайтесь, чтобы прокачивать свои IT-знания всего за 2 минуты в день!