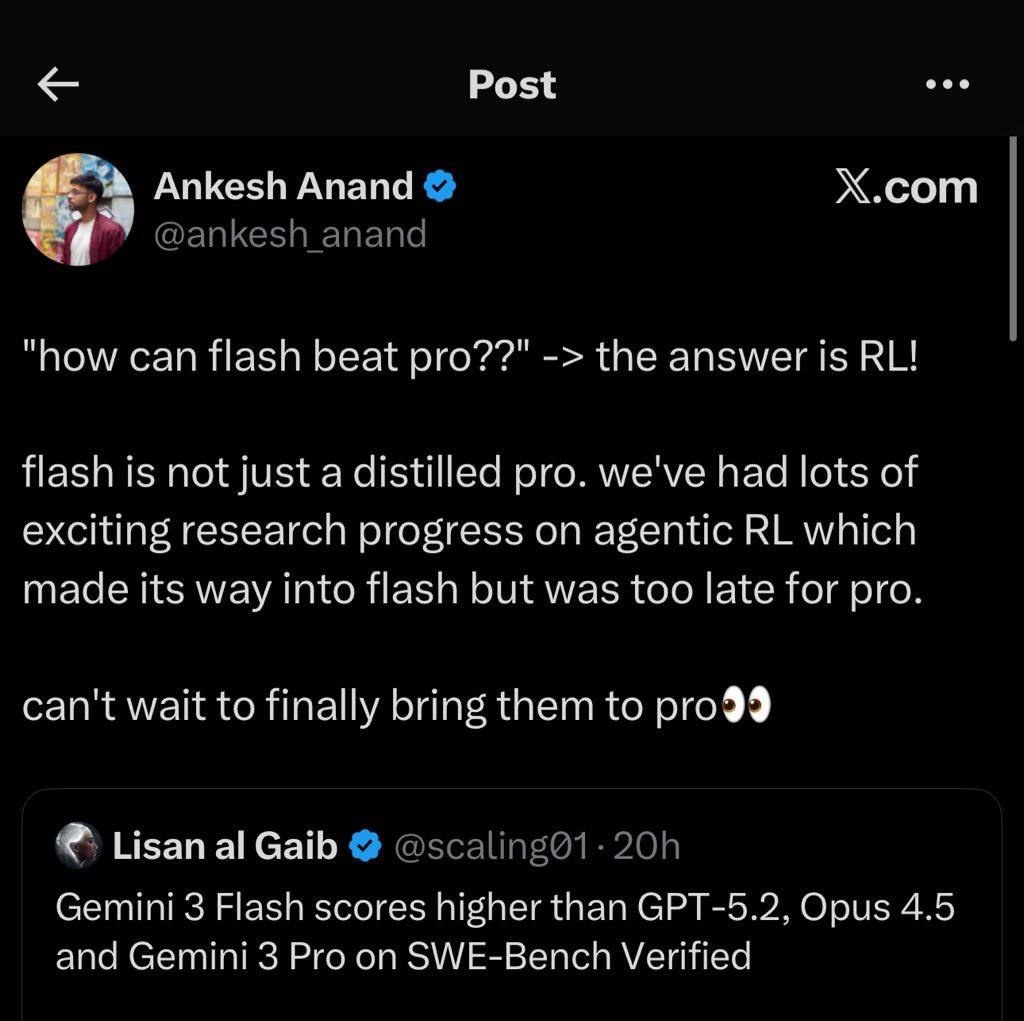
🚀 Google DeepMind раскрыли, как Gemini 1.5 Flash разделалась с конкурентами на SWE-bench
SWE-bench - это не обычный тест для чат-ботов на знание синтаксиса Python. Тут все по-взрослому: модели дают реальные задачи из GitHub и репозитории на 100 000+ строк. Нужно найти и исправить баги. Косяк в логике или сломанные зависимости стоят победы.
Самое интересное кроется в версии Verified. Этот список задач вручную отбирали эксперты из OpenAI и Anthropic. Они убрали мусор и оставили только чистые кейсы. Получается, Google победил на чужом поле по правилам, которые писали его главные соперники.
🔹 В чем секрет?
Пока глава Anthropic Дарио Амодеи тратит миллиарды на обычное дообучение, Google выбрал Reinforcement Learning (RL) - обучение через поощрение.
Логика тут железная. Базовые знания нейронок застряли на месте. В интернете почти не осталось новых данных, а скармливать им мусор из сети вредно. Для программирования не нужна эрудиция. Тут важнее умение рассуждать, проверять свои идеи и видеть ошибки.
✍️ Техническая сторона:
Google внедрил PRM (Process Reward Models). Эта система оценивает каждый шаг в цепочке мыслей. Если модель ошибается в середине пути - ее сразу поправляют. Поэтому легкая Flash-версия соображает быстрее и точнее тяжелых программ конкурентов.
Похоже, возвращение Сергея Брина к управлению дает результат. Пока лидеры рынка спорят, у кого база данных длиннее, инженеры Google придумывают хитрые решения.
Я уверен: время гигантских моделей уходит. Будущее за RL и тщательной проверкой хода мыслей. Если вы до сих пор оцениваете ИИ только по объему памяти - вы застряли в прошлом.
Что выберете для работы: помощника, который помнит все библиотеки, или того, кто сам правит свои глюки?
#Google #Gemini #AI #DeepMind #Programming