
Когда мы говорим о том, что данные помогают принимать решения, то мы невольно очень упрощаем реальность. Есть окружающий мир, процессы в нем, а есть данные, которые отражают этот мир, и также есть человек, который на основе этих данных делает какие-то выводы.
Данные при таком подходе понимаются как некоторое «нейтральное зеркало», а решения видятся нам как результат чистого рационального мышления.
На практике же всё работает гораздо тоньше и, честно говоря, опаснее.
Данные не просто помогают принимать решения, они на самом деле формируют рамку, внутри которой решение вообще становится возможным, и чаще всего мы этого не замечаем и не осознаем.
Иллюзия нейтральных данных 🧠
Одна из самых устойчивых иллюзий в аналитике - это вера в то, что данные сами по себе нейтральны. Вы, наверное, слышали такое: цифры никогда не врут, графики отражают объективные процессы, а если есть искажение и есть, то оно скорее в интерпретации этих данных.
Но в этой статье я попробую указать на тот момент, что проблема начинается гораздо раньше интерпретации данных.
Данные всегда получаются в результате цепочки решений. Если данные есть, уже заранее было определено:
- что нужно считать тем или иным событием,
- в какой момент важно фиксировать это событие,
- в каких срезах его нужно хранить,
- какие поля считать более важными, а какие менее.
То есть ещё до того, как аналитик начал смотреть на цифры, реальность уже была упрощена.
То есть, на самом деле, мы принимаем решения не на основе реальности, а на основе того, как реальность была формализована, что мы решили сделать важным, а что второстепенным.
Фрейминг: когда один и тот же факт выглядит по-разному 📊
Возьмем некоторый датасет об операционной деятельности крупной промышленной компании: задачи, время выполнения и т.п.
Уточню, что никаких оценок эффективности в данных нет. Только факты процессов.
В рамках этого датасета мы можем задать себе разные вопросы:
- где у нас падение эффективности?
- кто работает хуже / лучше?
- где узкие места в процессах?
И каждый из этих вопросов создаёт свой фрейм, внутри которого данные начинают «говорить».
Если мы смотрим среднее время выполнения задач - мы начинаем думать про скорость. Если долю просрочек, то про дисциплину работы. Если распределение по командам, то про людей.
Данные те же самые, а вот решения уже будут разные.
Как один и тот же датасет ведёт к разным выводам 🔍
Вариант 1. Смотрим среднее время выполнения
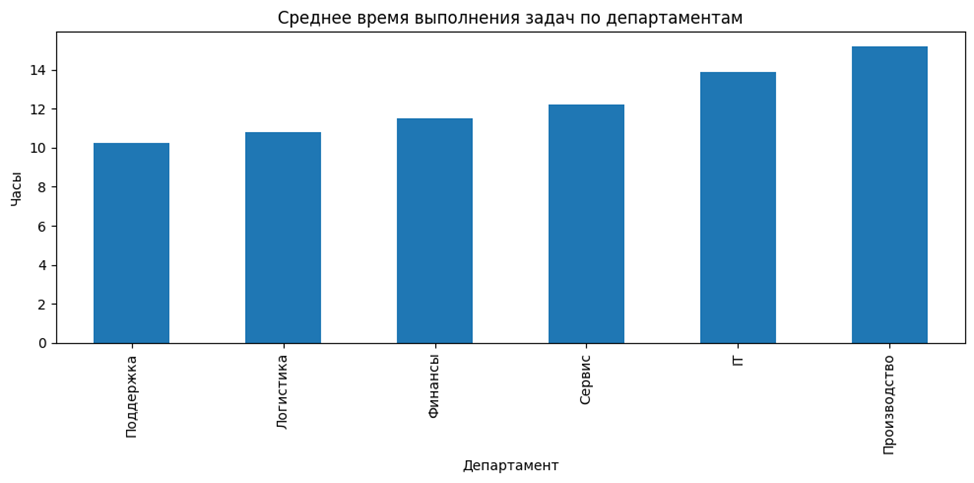
На основании данных мы можем сделать вывод о том, что: задачи производства и IT закрываются дольше.
Вариант 2. Смотрим распределения
Когда вместо среднего мы смотрим распределение, картина меняется. Оказывается, что в IT и Производстве есть длинный хвост сложных задач, при этом медиана везде примерно одна и та же. Получается, что редкие, но очень тяжёлые задачи «тянут» среднее вверх.
И вот вывод здесь уже может быть иной: проблема не в скорости, а в структуре задач.
Вариант 3. Смотрим только высокоприоритетные задачи
Если отфильтровать только высокоприоритетные задачи, вдруг выясняется, что:
- у IT отдела нет проблем с выполнением важных задач, а в производстве она существует,
- и неожиданно, в департаменте финансов сбоят приоритетные задачи, хотя на других графиках они никак не выделялись.
Этот график почти всегда приводит к вопросу: а точно ли мы правильно управляем приоритетными задачами?
Вывод 🤔
Важно понимать очень банальную вещь: аналитик не просто анализирует данные, он формирует пространство решений через представление этих данных.
Всегда нужно держать в голове:
- какие графики мы показываем первыми, такие вопросы от пользователей и будут заданы;
- в каких разрезах мы выбрали показывать данные, такие выводы и сделает руководство;
- какие метрики мы вынесли на дашборды, такие управленческие действия и будут приниматься
Самая коварная ловушка - это считать, что раз данные есть, код ошибок не выдает, а графики аккуратные и красивые, то и решения объективны. Лучше всего воспринимайте аналитику как линзу, а не как зеркало. Аналитика усиливает одни сигналы и гасит другие.
Если аналитик не задаёт себе вопрос «что я сейчас не показываю?», то решение принимается в слепой зоне.
Я регулярно разбираю такие темы в своём Telegram-канале, если вам интересно глубже понимать аналитику и работать с данными, там регулярно выходят короткие заметки и практические примеры.