Когда сроки ИТ-задач начинают расти, менеджеры часто ищут виноватых. Но гуру качества Эдвард Деминг учил: «94% проблем создаются системой». Чтобы найти реальный источник сбоя, а не наказывать невиновных, профессионалы используют SPC (статистическое управление процессами).
Ниже — пошаговый алгоритм, как отличить «рабочий шум» от системного кризиса на примере процесса предоставления физической ИТ-инфраструктуры
Исходные данные и графики примера
Шаг 1. Сбор данных и определение «голоса процесса»
Прежде чем анализировать, нужно понять, как процесс работает в нормальном состоянии. Мы фиксируем срок выполнения заявки.
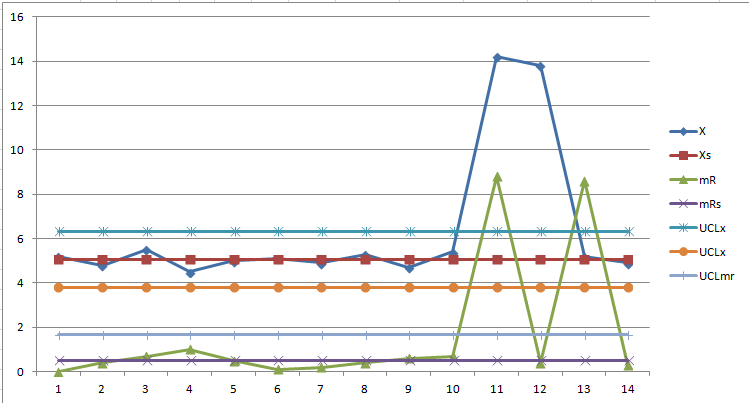
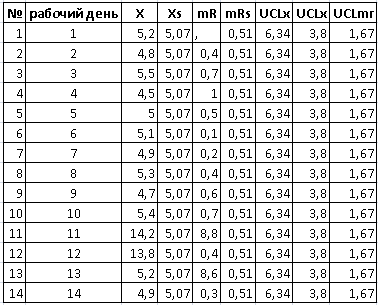
- Пример: Мы замерили срок предоставления серверов за 10 дней. Средний срок составил 5.07 дня. Это «базовая линия» — то, на что наша система способна сейчас.
Шаг 2. Расчет границ дозволенного
В любом процессе есть естественные колебания (админ отвлекся, сервер дольше обновлялся). На основе вариабельности первых 10 дней мы рассчитываем Верхнюю контрольную границу (UCL). В нашем примере она составила 6.34 дня.
- Суть: Всё, что быстрее 6.34 дня — это общие причины вариабельности. В них нет виноватых, это просто особенности системы. Мы не вмешиваемся.
Шаг 3. Идентификация сигнала (Обнаружение особой причины)
Мы продолжаем наносить данные на график. И вдруг видим резкий скачок.
- Пример: На 11-й день срок выполнения составил 14.2 дня.
- Действие: Точка «пробила» границу 6.34. В SPC это сигнал о появлении Особой причины. Система сообщает нам: «Внутри меня что-то радикально изменилось, разберитесь с этим!».
Шаг 4. Локализация источника проблемы
Теперь мы ищем не «кто виноват», а «что изменилось в системе в этот момент». Для этого мы смотрим на скользящий размах (разницу между соседними днями).
- Пример: Между 10-м и 11-м днем размах прыгнул с 0.7 до 8.8. Это подтверждает: произошел резкий технический или логистический сдвиг.
Шаг 5. Поиск системного дефекта (Метод 6M)
Мы анализируем категории: Люди, Оборудование, Материалы, Методы, Измерения, Среда.
- Пример: Проверяем «Материалы» и «Методы». Выясняется, что в ERP-системе произошло обновление, из-за которого перестал работать аллерт о нехватке комплектующих. Инженеры пришли на склад, а там пусто. Они физически не могли предоставить сервер вовремя.
Шаг 6. Устранение причины и проверка стабильности
Мы устраняем источник проблемы (баг в ERP), а не наказываем инженеров за простой.
- Пример: Баг исправлен. Мы смотрим на данные 13-го дня. Срок выдачи — 5.2 дня.
- Результат: Точка вернулась в границы (ниже 6.34). Процесс снова стабилен и предсказуем.
Почему это важно для ИТ?
Если бы мы смотрели только на «среднее», 11-й день просто немного испортил бы нам статистику. Но контрольная карта Шухарта заставляет нас расследовать каждый выход за границы.
Благодаря SPC мы не просто узнали, что «стало медленнее», а локализовали системную проблему в автоматизации и управлении ресурсами. Процесс был исправлен, и уже к 13-му дню (5.2 дня) система вернулась в границы нормы.
Итог для руководителя
Если бы мы не вели контрольные карты, мы бы узнали о проблеме через неделю из гневных писем заказчиков.
SPC позволило нам:
- Увидеть аномалию в первый же день её появления.
- Понять, что проблема — не в лени сотрудников, а в ИТ-инструментарии (ERP).
- Математически доказать, что после фикса бага процесс снова стал стабильным.
А вы уже научили свои процессы «разговаривать» с вами через графики?
Как вы ищете причины задержек в своих процессах?
Делитесь в комментариях!