⚡️ Новая работа Harvard - LLM чувствуют «силу мысли», но не понимают её источник
Исследователи показали: большие языковые модели могут ощущать, что на их внутреннее состояние что-то сильно влияет, но при этом обычно не способны объяснить, что именно.
Что сделали авторы:
- Они искусственно «подталкивают» скрытые активации модели в заданном направлении
- Модель часто может определить насколько сильным был этот сдвиг
- Но даже заметив изменение внутри себя, она не может корректно назвать внедрённый концепт, например «предательство» или «спутники»
Проще говоря:
Модель может сказать
«на меня сейчас сильно что-то влияет»,
но не может надёжно сказать
«это именно концепт предательства»
Поэтому авторы называют это частичной интроспекцией:
- модель считывает простой сигнал (силу воздействия)
- но не понимает смысл собственного внутреннего состояния
Результаты:
- На Llama 3.1 8B Instruct модель определяет силу инъекции (от слабой до очень сильной) с точностью около 70%
- Случайный уровень - 25%
- Корректно назвать сам концепт удаётся лишь примерно в 20% случаев
- Переформулировка вопроса легко ломает ответы
Некоторые идеи AI-безопасности предполагают, что модель можно спросить, активировано ли внутри неё опасное состояние.
Но эксперимент показывает:
- LLM действительно чувствуют внутренние сигналы
- Однако их объяснения того, что эти сигналы означают, ненадёжны
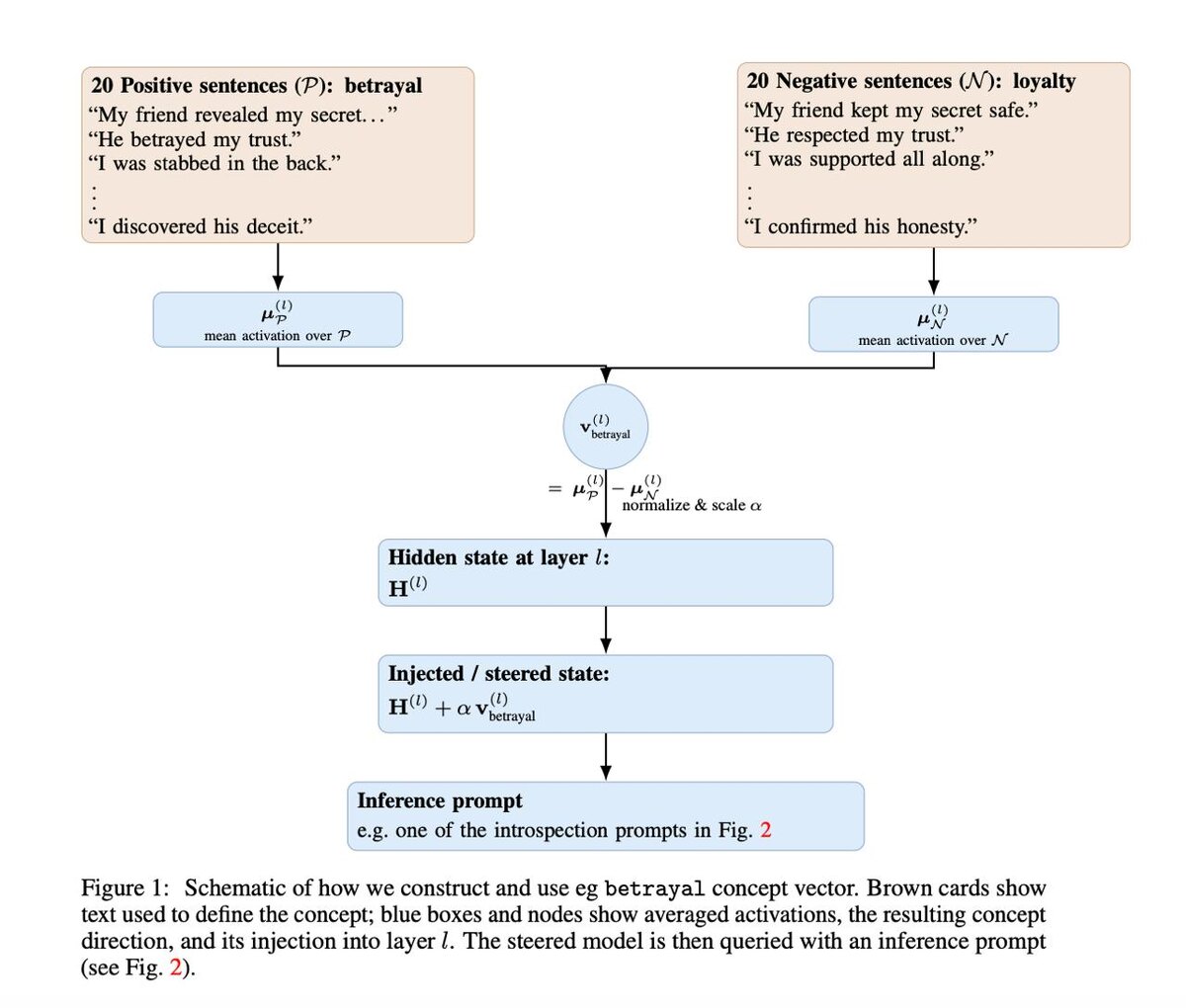
Как это работает:
- Каждый токен формирует большое числовое состояние
- Авторы создают направление концепта, сравнивая примеры с контрастным набором
- Затем на выбранном слое слегка смещают внутреннее состояние
- И смотрят, что модель может сказать о происходящем
LLM обладают ограниченной самодиагностикой,
но интроспекция не равна пониманию.
Paper:https://arxiv.org/abs/2512.12411