
🧩 Что такое Microfunctions (Микрофункции)?
Простое объяснение: Представьте, что вместо одной огромной программы у вас есть набор маленьких программок-лего. Каждая делает одну простую вещь:
- Одна умеет определять котиков на картинке
- Другая — переводить текст
- Третья — считать сумму покупок
Microfunction = одна маленькая функция, которая:
- Делает ОДНУ задачу
- Живёт отдельно от других
- Может работать на любом компьютере в сети
- Вызывается мгновенно и завершает работу
🚀 Шаг 1: Подготовка среды для Microfunctions
Цель шага: Создать "песочницу", где будем строить микрофункции.
Что нужно установить:
- Docker — как "контейнерный грузовик" для перевозки функций
- OpenFaaS — как "диспетчер" для управления функциями
Пошаговая установка:
bash
# 1. Установите Docker (если ещё нет)
# Скачайте с https://www.docker.com/products/docker-desktop/
# 2. Установите OpenFaaS CLI (командный интерфейс)
# Для Mac/Linux:
curl -sSL https://cli.openfaas.com | sudo sh
# Для Windows (через PowerShell):
Invoke-WebRequest -Uri "https://cli.openfaas.com" -OutFile "faas-cli.exe"
# 3. Разверните OpenFaaS локально
docker swarm init # Включаем режим роя (если не включён)
faas-cli deploy -f https://raw.githubusercontent.com/openfaas/faas/master/stack.yml
Проверка установки:
bash
# Откройте в браузере:
# http://localhost:8080
# Логин: admin
# Пароль: получите командой:
echo $(cat ~/openfaas_password.txt)
Что должно получиться:
✅ OpenFaaS работает на localhost:8080
✅ Есть веб-интерфейс управления
✅ Можно создавать функции через командную строку
На что обратить внимание:
- Docker должен быть запущен
- Порт 8080 не должен быть занят
- Если ошибка с swarm — проверьте, что Docker Desktop настроен на использование swarm
📝 Шаг 2: Ваша первая Microfunction
Цель шага: Создать и запустить простейшую микрофункцию.
Что такое "шаблон функции":
OpenFaaS предоставляет готовые "болванки" функций на разных языках. Как формы для выпечки — залил тесто (код) и получил кекс (функцию).
bash
# Посмотрим доступные шаблоны
faas-cli template store list
Вы увидите что-то вроде:
text
python3
node
golang
csharp
...
Создаём первую функцию на Python:
bash
# Создаём функцию "привет мир"
faas-cli new hello-world --lang python3
Что создалось:
text
hello-world/
├── handler.py # ← КОД ФУНКЦИИ (главный файл)
├── requirements.txt # ← Библиотеки Python
└── hello-world.yml # ← Конфигурация развёртывания
Смотрим код функции:
python
# hello-world/handler.py
def handle(req):
"""Обработчик функции - вызывается при каждом запросе"""
print("📨 Получен запрос:", req)
# Простейшая логика: возвращаем приветствие
return f"Привет, мир! Ты отправил: {req}"
Объяснение терминов:
- req — request (запрос) — то, что пришло в функцию
- return — ответ функции
- handle — главная функция, которая вызывается всегда
Собираем и разворачиваем функцию:
bash
# 1. Собираем Docker-образ функции
faas-cli build -f hello-world.yml
# 2. Разворачиваем в OpenFaaS
faas-cli deploy -f hello-world.yml
Тестируем функцию:
bash
# Через командную строку
echo "Тестовое сообщение" | faas-cli invoke hello-world
# Через curl (HTTP запрос)
curl http://localhost:8080/function/hello-world -d "Привет из браузера"
Что должно получиться:
✅ В терминале: Привет, мир! Ты отправил: Тестовое сообщение
✅ Функция появилась в веб-интерфейсе OpenFaaS
✅ Можно вызывать её из любого места
На что обратить внимание:
- При первом запуске будет долго — скачиваются образы Docker
- Функция запускается "по требованию" — если не вызывать, она "спит"
- Логи можно посмотреть в веб-интерфейсе или командой: faas-cli logs hello-world
🧠 Шаг 3: Создаём ИИ-микрофункцию
Цель шага: Сделать полезную ИИ-функцию — анализатор настроения текста.
Что такое "зависимости" в Python:
Это библиотеки (дополнительный код), которые нужны для работы функции. Например, для ИИ нужны библиотеки машинного обучения.
Создаём функцию анализа настроения:
bash
faas-cli new sentiment-analyzer --lang python3
Редактируем requirements.txt:
txt
# hello-world/sentiment-analyzer/requirements.txt
transformers==4.30.0
torch
numpy
Объяснение:
- transformers — библиотека для работы с моделями ИИ от Hugging Face
- torch — фреймворк машинного обучения (PyTorch)
- numpy — для работы с числами и массивами
Пишем ИИ-логику:
python
# sentiment-analyzer/handler.py
import json
from transformers import pipeline
# ЗАГРУЖАЕМ МОДЕЛЬ ПРИ СТАРТЕ ФУНКЦИИ
# (чтобы не грузить каждый раз при вызове)
print("🤖 Загружаю модель анализа настроения...")
sentiment_analyzer = pipeline("sentiment-analysis", model="blanchefort/rubert-base-cased-sentiment")
print("✅ Модель загружена!")
def handle(req):
"""Анализирует настроение текста на русском языке"""
try:
# Пытаемся понять, что нам прислали
if not req or req.strip() == "":
return json.dumps({
"error": "Пустой текст",
"advice": "Отправьте текст для анализа"
})
print(f"📊 Анализирую текст: {req[:50]}...")
# Анализируем настроение с помощью ИИ
result = sentiment_analyzer(req)[0]
# Переводим label на русский
label_translation = {
"positive": "позитивный",
"negative": "негативный",
"neutral": "нейтральный"
}
# Формируем красивый ответ
response = {
"text": req,
"sentiment": label_translation.get(result['label'], result['label']),
"confidence": round(result['score'] * 100, 2), # Проценты
"emoji": "😊" if result['label'] == "positive" else
"😢" if result['label'] == "negative" else "😐"
}
print(f"✅ Результат: {response['sentiment']} ({response['confidence']}%)")
return json.dumps(response, ensure_ascii=False)
except Exception as e:
# Обработка ошибок
error_response = {
"error": "Ошибка анализа",
"details": str(e),
"tip": "Проверьте текст и попробуйте снова"
}
print(f"❌ Ошибка: {e}")
return json.dumps(error_response)
Разворачиваем ИИ-функцию:
bash
# Собираем (это займёт время - скачивается модель 500MB!)
faas-cli build -f sentiment-analyzer.yml
# Разворачиваем
faas-cli deploy -f sentiment-analyzer.yml
Тестируем ИИ-функцию:
bash
# Тестируем разные тексты
echo "Я люблю программирование!" | faas-cli invoke sentiment-analyzer
echo "Ненавижу ошибки в коде" | faas-cli invoke sentiment-analyzer
echo "Сегодня обычный день" | faas-cli invoke sentiment-analyzer
Пример ответа:
json
{
"text": "Я люблю программирование!",
"sentiment": "позитивный",
"confidence": 99.87,
"emoji": "😊"
}
Что должно получиться:
✅ Функция определяет настроение текста
✅ Модель загружается один раз при старте
✅ Ответ в формате JSON для удобства
✅ Есть обработка ошибок
На что обратить внимание:
- Первый запуск долгий — скачивается модель ИИ (~500MB)
- Функция "помнит" модель между вызовами
- Размер функции большой из-за модели — нужно настроить memory limits
🔧 Шаг 4: Настройка параметров функции
Цель шага: Оптимизировать работу функции (память, время выполнения, масштабирование).
Редактируем конфигурацию YAML:
yaml
# sentiment-analyzer.yml
version: 1.0
provider:
name: openfaas
gateway: http://127.0.0.1:8080
functions:
sentiment-analyzer:
lang: python3
handler: ./sentiment-analyzer
image: sentiment-analyzer:latest
# ⚙️ НАСТРОЙКИ ФУНКЦИИ
environment:
# Переменные окружения
write_timeout: "300s" # 5 минут на выполнение
read_timeout: "300s" # 5 минут на чтение
exec_timeout: "300s" # 5 минут максимально
limits:
memory: 2Gi # ОЗУ для функции (модель требует памяти!)
cpu: "1000m" # 1 ядро CPU
requests:
memory: 1Gi # Минимум ОЗУ
cpu: "200m" # Минимум CPU
# 🔁 АВТОМАСШТАБИРОВАНИЕ
annotations:
# Минимум и максимум копий функции
com.openfaas.scale.min: "1"
com.openfaas.scale.max: "10"
# Целевая нагрузка для автомасштабирования
# (средняя задержка в секундах)
com.openfaas.scale.target: "0.5"
# Шаг масштабирования
com.openfaas.scale.step: "1"
Обновляем функцию с новыми настройками:
bash
# Пересобираем и обновляем
faas-cli build -f sentiment-analyzer.yml
faas-cli deploy -f sentiment-analyzer.yml
Проверяем настройки:
bash
# Смотрим информацию о функции
faas-cli describe sentiment-analyzer
Что должно получиться:
✅ Функция имеет гарантированные ресурсы
✅ Можно обрабатывать длинные тексты (таймаут 5 минут)
✅ Автомасштабирование включено
На что обратить внимание:
- Memory limits важны для ИИ-моделей
- Таймауты нужно увеличивать для сложных вычислений
- Автомасштабирование экономит ресурсы
📚 Шаг 5: Управление версиями функций
Цель шага: Научиться обновлять функции без сбоев и откатываться при проблемах.
Проблема:
Как обновить функцию, если в ней есть ошибка? Нужна возможность быстро вернуть старую рабочую версию.
Решение: Docker теги!
Аналогия: Git для кода, а Docker теги — для образов функций.
Создаём версионированную функцию:
bash
# 1. Создаём новую версию функции-счётчика
faas-cli new word-counter --lang python3
python
# word-counter/handler.py
import json
import re
def handle(req):
"""Считает слова и символы в тексте"""
try:
# Удаляем лишние пробелы
text = req.strip()
if not text:
return json.dumps({
"version": "1.0.0",
"error": "Нет текста для анализа"
})
# Считаем слова (разные методы)
words = re.findall(r'\b\w+\b', text)
characters = len(text.replace(' ', ''))
result = {
"version": "1.0.0",
"text_length": len(text),
"word_count": len(words),
"character_count": characters,
"unique_words": len(set(words)),
"average_word_length": round(sum(len(w) for w in words) / len(words), 2) if words else 0
}
return json.dumps(result, ensure_ascii=False)
except Exception as e:
return json.dumps({
"version": "1.0.0",
"error": str(e)
})
Разворачиваем версию 1.0.0:
yaml
# word-counter.yml
version: 1.0
provider:
name: openfaas
gateway: http://127.0.0.1:8080
functions:
word-counter:
lang: python3
handler: ./word-counter
image: word-counter:1.0.0 # ← ВЕРСИЯ В ТЕГЕ!
bash
# Собираем и деплоим
faas-cli build -f word-counter.yml
faas-cli deploy -f word-counter.yml
Тестируем:
bash
echo "Привет мир, это тестовый текст" | faas-cli invoke word-counter
Создаём новую версию 1.1.0:
python
# word-counter/handler.py (обновлённая версия)
import json
import re
from collections import Counter
def handle(req):
"""Считает слова и символы в тексте (версия 1.1.0)"""
try:
text = req.strip()
if not text:
return json.dumps({
"version": "1.1.0",
"error": "Пожалуйста, введите текст для анализа"
})
# Улучшенный анализ
words = re.findall(r'\b\w+\b', text.lower()) # Приводим к нижнему регистру
characters = len(text.replace(' ', ''))
# Считаем частоту слов
word_freq = Counter(words)
most_common = word_freq.most_common(3)
result = {
"version": "1.1.0",
"text": text[:100] + ("..." if len(text) > 100 else ""),
"metrics": {
"length": len(text),
"words": len(words),
"characters": characters,
"unique_words": len(set(words)),
"avg_word_length": round(sum(len(w) for w in words) / len(words), 2) if words else 0
},
"top_words": [
{"word": word, "count": count}
for word, count in most_common
],
"readability_score": calculate_readability(text)
}
return json.dumps(result, ensure_ascii=False, indent=2)
except Exception as e:
return json.dumps({
"version": "1.1.0",
"error": str(e),
"tip": "Попробуйте другой текст"
})
def calculate_readability(text):
"""Оценивает удобочитаемость текста"""
words = re.findall(r'\b\w+\b', text)
sentences = re.split(r'[.!?]+', text)
if len(words) == 0 or len(sentences) == 0:
return 0
avg_words_per_sentence = len(words) / len(sentences)
# Простая формула
if avg_words_per_sentence < 10:
return "легко"
elif avg_words_per_sentence < 20:
return "средне"
else:
return "сложно"
Разворачиваем версию 1.1.0:
yaml
# word-counter.yml (обновляем тег)
functions:
word-counter:
lang: python3
handler: ./word-counter
image: word-counter:1.1.0 # ← НОВАЯ ВЕРСИЯ!
bash
# Собираем и деплоим новую версию
faas-cli build -f word-counter.yml
faas-cli deploy -f word-counter.yml
Откатываемся на версию 1.0.0 если что-то пошло не так:
bash
# Просто меняем тег в YAML обратно на 1.0.0 и деплоим
faas-cli deploy -f word-counter.yml --image word-counter:1.0.0
Что должно получиться:
✅ Две версии функции в Docker registry
✅ Быстрый откат при проблемах
✅ Чёткое понимание, какая версия работает
На что обратить внимание:
- Всегда указывайте версию в ответе функции
- Тестируйте новую версию перед массовым деплоем
- Храните старые версии на случай отката
🔗 Шаг 6: Связываем функции в цепочки
Цель шага: Создать сложную логику из простых функций.
Что такое "цепочка функций":
Когда одна функция вызывает другую. Как на конвейере: первый рабочий делает деталь, второй её красит, третий упаковывает.
Создаём цепочку для обработки отзывов:
Задача: Получить отзыв → Определить настроение → Сгенерировать ответ → Сохранить в базу
python
# 1. Функция-маршрутизатор (orchestrator.py)
import json
import requests
def handle(req):
"""Главная функция, которая вызывает остальные"""
try:
data = json.loads(req)
review_text = data.get("review", "")
user_id = data.get("user_id", "anonymous")
if not review_text:
return json.dumps({"error": "Нет текста отзыва"})
print(f"👤 Отзыв от пользователя {user_id}")
# 📝 Шаг 1: Анализ настроения
sentiment_result = requests.post(
"http://gateway:8080/function/sentiment-analyzer",
data=review_text
).json()
print(f"📊 Настроение: {sentiment_result.get('sentiment', 'unknown')}")
# 🔢 Шаг 2: Анализ текста
analysis_result = requests.post(
"http://gateway:8080/function/word-counter",
data=review_text
).json()
# ✍️ Шаг 3: Генерация ответа (новая функция)
response_data = {
"review": review_text,
"sentiment": sentiment_result,
"analysis": analysis_result,
"user_id": user_id,
"timestamp": "2024-01-15T12:00:00Z" # В реальности использовать datetime
}
# 💾 Шаг 4: Сохранение (имитация)
save_result = save_to_db(response_data)
# 📨 Шаг 5: Формирование финального ответа
final_response = {
"status": "success",
"message": generate_response_message(sentiment_result),
"data": {
"sentiment": sentiment_result.get("sentiment"),
"confidence": sentiment_result.get("confidence"),
"word_count": analysis_result.get("metrics", {}).get("words", 0)
},
"saved": save_result.get("success", False)
}
return json.dumps(final_response, ensure_ascii=False, indent=2)
except Exception as e:
return json.dumps({"error": str(e)})
def generate_response_message(sentiment_result):
"""Генерирует ответ в зависимости от настроения"""
sentiment = sentiment_result.get("sentiment", "нейтральный")
responses = {
"позитивный": "Спасибо за позитивный отзыв! Мы рады, что вам понравилось! 😊",
"негативный": "Спасибо за отзыв. Нам жаль, что вы остались недовольны. Мы работаем над улучшениями. 🙏",
"нейтральный": "Спасибо за ваш отзыв! Мы учтём ваши замечания. 👍"
}
return responses.get(sentiment, "Спасибо за отзыв!")
def save_to_db(data):
"""Имитация сохранения в базу данных"""
# В реальности здесь было бы подключение к БД
print(f"💾 Сохраняю данные: {data['user_id']}")
return {"success": True, "id": "fake_id_123"}
Создаём и разворачиваем оркестратор:
bash
# Создаём функцию
faas-cli new review-processor --lang python3
# Копируем код в handler.py
# Добавляем requests в requirements.txt
echo "requests" > review-processor/requirements.txt
# Собираем и деплоим
faas-cli build -f review-processor.yml
faas-cli deploy -f review-processor.yml
Тестируем цепочку:
bash
# Подготавливаем JSON с отзывом
echo '{"review": "Отличный продукт, всем рекомендую!", "user_id": "user_123"}' | faas-cli invoke review-processor
Что должно получиться:
text
{
"status": "success",
"message": "Спасибо за позитивный отзыв! Мы рады, что вам понравилось! 😊",
"data": {
"sentiment": "позитивный",
"confidence": 98.5,
"word_count": 4
},
"saved": true
}
На что обратить внимание:
- Функции общаются через HTTP
- Можно добавлять/убирать шаги в цепочке
- Каждая функция независима и может быть заменена
- Ошибка в одной функции не ломает всю систему
📊 Шаг 7: Мониторинг и логирование функций
Цель шага: Научиться отслеживать работу функций и находить проблемы.
Смотрим логи функций:
bash
# Логи конкретной функции
faas-cli logs review-processor
# Логи за последние 10 минут
faas-cli logs review-processor --since 10m
# Следить за логами в реальном времени
faas-cli logs review-processor --follow
# Логи с фильтрацией
faas-cli logs review-processor | grep "ERROR\|error"
Добавляем структурированное логирование в функции:
python
# advanced-logger/handler.py
import json
import time
import sys
class FunctionLogger:
def __init__(self, function_name):
self.function_name = function_name
def log(self, level, message, **extra):
"""Структурированное логирование"""
log_entry = {
"timestamp": time.time(),
"function": self.function_name,
"level": level.upper(),
"message": message,
**extra
}
# Пишем в stderr (OpenFaaS перехватывает stderr)
print(json.dumps(log_entry), file=sys.stderr)
return log_entry
# Создаём логгер
logger = FunctionLogger("advanced-logger")
def handle(req):
"""Функция с продвинутым логированием"""
start_time = time.time()
request_id = f"req_{int(start_time * 1000)}"
logger.log("info", "Начало обработки",
request_id=request_id,
input_length=len(req))
try:
# Имитация работы
time.sleep(0.5)
# Бизнес-логика
result = {"processed": True, "request_id": request_id}
execution_time = time.time() - start_time
logger.log("info", "Обработка завершена",
request_id=request_id,
execution_time=round(execution_time, 3),
result_size=len(json.dumps(result)))
return json.dumps(result)
except Exception as e:
logger.log("error", "Ошибка обработки",
request_id=request_id,
error=str(e),
error_type=type(e).__name__)
return json.dumps({"error": str(e)})
Используем Prometheus для мониторинга:
bash
# Установите Prometheus и Grafana для визуализации
# Или используйте встроенные метрики OpenFaaS:
# Смотрите метрики функций
curl http://localhost:8080/system/metrics
# Метрики конкретной функции
curl http://localhost:8080/system/function-metrics?function=review-processor
Создаём дашборд для мониторинга:
python
# monitor-dashboard/handler.py
import json
import requests
from datetime import datetime, timedelta
def handle(req):
"""Дашборд для мониторинга функций"""
gateway_url = "http://gateway:8080"
try:
# Получаем список функций
functions_response = requests.get(f"{gateway_url}/system/functions")
functions = functions_response.json()
dashboard = {
"timestamp": datetime.now().isoformat(),
"status": "online",
"functions": [],
"summary": {
"total_functions": 0,
"healthy": 0,
"errors_last_hour": 0,
"total_invocations": 0
}
}
for func in functions:
# Получаем метрики для каждой функции
metrics_url = f"{gateway_url}/system/function-metrics?function={func['name']}"
metrics_response = requests.get(metrics_url)
function_info = {
"name": func['name'],
"image": func['image'],
"invocation_count": func.get('invocationCount', 0),
"replicas": func.get('replicas', 0),
"status": "healthy" if func.get('availableReplicas', 0) > 0 else "unhealthy"
}
dashboard["functions"].append(function_info)
dashboard["summary"]["total_functions"] += 1
if function_info["status"] == "healthy":
dashboard["summary"]["healthy"] += 1
dashboard["summary"]["total_invocations"] += function_info["invocation_count"]
return json.dumps(dashboard, ensure_ascii=False, indent=2)
except Exception as e:
return json.dumps({
"timestamp": datetime.now().isoformat(),
"status": "error",
"error": str(e)
})
Что должно получиться:
✅ Структурированные логи в JSON формате
✅ Мониторинг через Prometheus метрики
✅ Дашборд со статусом всех функций
✅ Быстрый поиск проблем
На что обратить внимание:
- Логируйте все важные события
- Добавляйте request_id для трассировки
- Мониторьте потребление памяти и CPU
- Настройте алерты при ошибках
🚀 Шаг 8: Оптимизация и best practices
Цель шага: Научиться писать эффективные и надёжные микрофункции.
Правило 1: Одна функция — одна ответственность
Плохо:
python
def handle(req):
# И анализирует настроение, И переводит, И сохраняет в БД
sentiment = analyze_sentiment(req)
translation = translate(req, "en")
save_to_db(req, sentiment, translation)
return "Готово"
Хорошо:
python
# Функция 1: Анализ настроения
def handle(req):
return analyze_sentiment(req)
# Функция 2: Перевод
def handle(req):
return translate(req, "en")
# Функция 3: Сохранение
def handle(req):
return save_to_db(req)
Правило 2: Кэшируйте тяжёлые операции
python
import json
from transformers import pipeline
import pickle
import os
# КЭШ МОДЕЛИ В ПАМЯТИ
_MODEL_CACHE = None
def get_model():
global _MODEL_CACHE
if _MODEL_CACHE is None:
print("🔄 Загружаю модель в кэш...")
_MODEL_CACHE = pipeline("sentiment-analysis")
print("✅ Модель загружена в кэш")
return _MODEL_CACHE
def handle(req):
# Используем кэшированную модель
model = get_model()
result = model(req)
return json.dumps(result)
Правило 3: Используйте пулы соединений
python
import json
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# СОЗДАЁМ СЕССИЮ С ПУЛОМ СОЕДИНЕНИЙ
_session = None
def get_session():
global _session
if _session is None:
_session = requests.Session()
# Настройка повторных попыток
retry = Retry(
total=3,
backoff_factor=0.1,
status_forcelist=[500, 502, 503, 504]
)
adapter = HTTPAdapter(
max_retries=retry,
pool_connections=10, # Размер пула
pool_maxsize=10
)
_session.mount('http://', adapter)
_session.mount('https://', adapter)
return _session
def handle(req):
session = get_session()
# Используем общую сессию для всех вызовов
response = session.post(
"http://another-function:8080",
json={"data": req},
timeout=5
)
return response.text
Правило 4: Валидируйте входные данные
python
import json
import jsonschema
from jsonschema import validate
# СХЕМА ВАЛИДАЦИИ
REQUEST_SCHEMA = {
"type": "object",
"properties": {
"text": {"type": "string", "minLength": 1, "maxLength": 1000},
"language": {"type": "string", "enum": ["ru", "en", "es"]},
"options": {
"type": "object",
"properties": {
"detailed": {"type": "boolean"},
"fast_mode": {"type": "boolean"}
}
}
},
"required": ["text"],
"additionalProperties": False
}
def handle(req):
try:
# Парсим JSON
data = json.loads(req)
# Валидируем по схеме
validate(instance=data, schema=REQUEST_SCHEMA)
# Если дошли сюда — данные валидны
text = data["text"]
language = data.get("language", "ru")
# Обработка...
result = process_text(text, language)
return json.dumps({
"success": True,
"result": result
})
except json.JSONDecodeError:
return json.dumps({
"success": False,
"error": "Неверный JSON формат"
})
except jsonschema.ValidationError as e:
return json.dumps({
"success": False,
"error": f"Ошибка валидации: {e.message}",
"field": e.path[0] if e.path else None
})
Правило 5: Добавляйте health checks
yaml
# В YAML файле функции
functions:
my-function:
lang: python3
handler: ./my-function
image: my-function:latest
# HEALTH CHECK
health_check: "http://127.0.0.1:8080/health"
health_check_interval: "10s"
health_check_timeout: "5s"
health_check_start_period: "30s"
python
# health-check/handler.py
import json
def handle(req):
"""Health check endpoint"""
# Проверяем зависимости
checks = {
"api_connection": check_api(),
"database": check_database(),
"memory": check_memory(),
"model_loaded": check_model()
}
all_healthy = all(checks.values())
response = {
"status": "healthy" if all_healthy else "unhealthy",
"timestamp": "2024-01-15T12:00:00Z",
"checks": checks
}
status_code = 200 if all_healthy else 503
return json.dumps(response), status_code
def check_api():
# Проверка внешнего API
return True
def check_database():
# Проверка БД
return True
def check_memory():
# Проверка памяти
import psutil
return psutil.virtual_memory().percent < 90
def check_model():
# Проверка загрузки модели
return True
🎓 Итог: Что вы научились делать
✅ Вы освоили:
- Создавать микрофункции на Python с помощью OpenFaaS
- Управлять версиями через Docker теги
- Связывать функции в цепочки для сложной логики
- Мониторить и логировать работу функций
- Оптимизировать производительность
🚀 Где хранить функции:
- Локально — для разработки и тестирования
- Docker Registry — для хранения образов (Docker Hub, GitLab Registry, AWS ECR)
- Git репозиторий — для хранения кода (GitHub, GitLab, Bitbucket)
🔧 Как управлять версионностью:
- Docker теги — function-name:1.0.0, function-name:1.1.0
- Git теги — привязывайте версию Docker к коммиту
- Semantic Versioning — MAJOR.MINOR.PATCH (1.2.3)
💻 На каком языке писать:
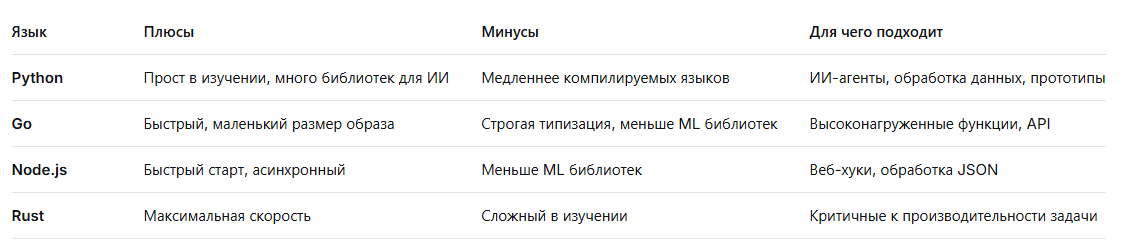
📚 Для ИИ-агентов рекомендую:
- Python — для прототипов и ML-функций
- Go — для оркестраторов и API
- Node.js — для веб-хуков
🎯 Следующие шаги для развития:
- Изучите Serverless Framework — альтернатива OpenFaaS
- Попробуйте облачные FaaS: AWS Lambda, Google Cloud Functions
- Добавьте базу данных к функциям (Redis, PostgreSQL)
- Настройте CI/CD для автоматического деплоя
- Создайте реальный проект — чат-бот, анализатор логов, система рекомендаций
💡 Помните:
- Начинайте с простого — одна функция, одна задача
- Тестируйте локально перед деплоем
- Мониторьте потребление ресурсов
- Документируйте функции — что принимают, что возвращают
Удачи в создании ваших ИИ-агентов с микрофункциями! 🚀