
Архитектурная философия и назначение
Apache Kafka — железнодорожная станция данных
Метафора: Представьте грузовую железнодорожную станцию, где вагоны (сообщения) сцеплены в составы (партиции) и движутся по рельсам (топики) с гарантированной сохранностью груза.
Основное назначение:
- Высокопроизводительная потоковая платформа
- Хранилище событий с долгосрочным хранением (дни, недели)
- Обработка потоков данных в реальном времени
- Связующее звено между системами в архитектуре event-driven
Специализация для ИИ-агентов:
python
# Типичный сценарий Kafka для ИИ:
1. ИИ-агент анализирует видео-поток
2. Каждый кадр → сообщение в топик "video-frames"
3. Группа моделей ИИ подписывается на топик:
- Детекция объектов (модель 1)
- Распознавание лиц (модель 2)
- Анализ эмоций (модель 3)
4. Результаты → новые топики → агрегация
RabbitMQ — почтовая служба доставки
Метафора: Традиционная почта с маршрутизацией, очередями и гарантией доставки конкретному получателю.
Основное назначение:
- Очереди сообщений с гибкой маршрутизацией
- Обмен сообщениями между микросервисами
- Работа с задачами и заданиями (task queues)
- RPC-коммуникация (request/reply)
Специализация для ИИ-агентов:
python
# RabbitMQ для координации ИИ-агентов:
1. Главный агент отправляет задачу в очередь "image-processing"
2. Рабочие агенты (Worker Pool):
- Worker 1: Берет задачу → обрабатывает → кладет результат
- Worker 2: Следующая задача...
3. Балансировка нагрузки между агентами
4. Гарантия, что каждая задача выполнится ровно 1 раз
Apache Pulsar — облачная платформа реального времени
Метафора: Гибрид аэропорта (высокая пропускная способность) и распределенного склада (многоуровневое хранение).
Основное назначение:
- Пуба/саб система следующего поколения
- Многоарендность и изоляция (cloud-native)
- Сегментированное хранение (Apache BookKeeper)
- Поддержка колокации вычислений (Pulsar Functions)
Специализация для ИИ-агентов:
python
# Pulsar для распределенных ИИ-агентов:
1. Агенты в разных дата-центрах подписываются на топик
2. Pulsar гарантирует доставку всем, несмотря на задержки
3. Встроенные функции (Pulsar Functions):
@Function
def preprocess_image(content):
# Выполняется рядом с данными
return resize(content, 224x224)
4. Автоматическая репликация между регионами
Сравнительная таблица по ключевым параметрам
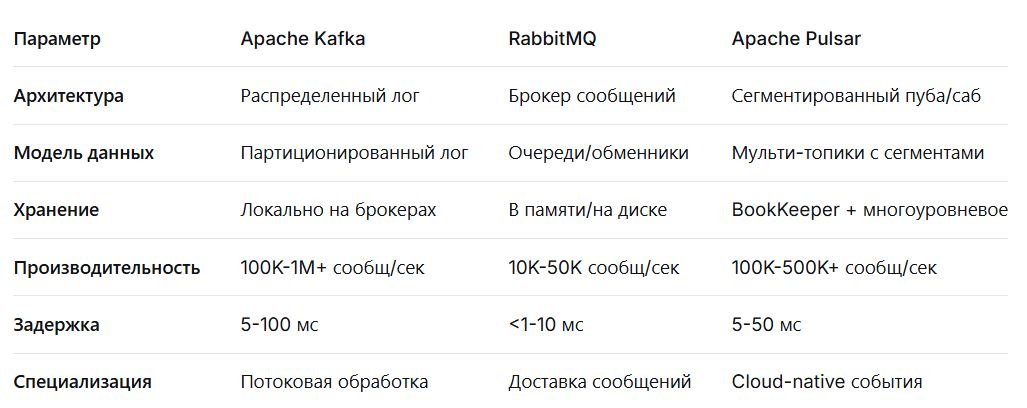
Лицензирование и стоимость
Apache Kafka
Лицензия: Apache 2.0 (полностью открытая)
Бесплатная версия:
- Полнофункциональный Open Source
- Включает: Kafka Connect, Kafka Streams, KSQL
- Самостоятельная установка и администрирование
Коммерческие предложения:
- Confluent Platform (основатели Kafka)
Starter: $0 (ограниченная функциональность)
Standard: ~$0.11/час за брокер (~$80/мес)
Enterprise: ~$0.65/час за брокер (~$470/мес)
Полный managed-сервис с поддержкой - AWS Managed Streaming for Kafka (MSK)
t3.small: ~$35/мес
r5.2xlarge: ~$600/мес
стоимость трафика и хранения - Прочие: Aiven Kafka, Instaclustr, Redpanda
Для ИИ-агентов:
yaml
# Типичная стоимость для проекта ИИ:
kafka_cluster:
nodes: 3
type: "r5.xlarge" (32GB RAM, 8 vCPU)
storage: 1TB SSD
monthly_cost:
self_hosted: ~$400 (инфраструктура)
confluent_cloud: ~$900
aws_msk: ~$1200
RabbitMQ
Лицензия:
- Ядро: Mozilla Public License 1.1
- Плагины: различные (включая коммерческие)
Бесплатная версия:
- Полнофункциональный RabbitMQ Community
- Все основные протоколы (AMQP 0-9-1, MQTT, STOMP)
- UI management plugin
Коммерческие предложения:
- VMware Tanzu RabbitMQ (бывш. Pivotal)
Старт: ~$2000/год за ноду
Предприятие: ~$10000+/год
Поддержка 24/7, SLA - CloudAMQP (managed)
Бесплатный план: 1M сообщений/мес
Little Lemur: $19/мес (30M сообщений)
Big Bunny: $199/мес (1B сообщений) - AWS Amazon MQ
mq.t3.micro: ~$10/мес
mq.m5.large: ~$300/мес
Особенность: Многие используют бесплатную версию в продакшене из-за зрелости сообщества.
Apache Pulsar
Лицензия: Apache 2.0
Бесплатная версия:
- Полнофункциональный Apache Pulsar
- Включает: Pulsar Functions, Pulsar IO
- Требует ZooKeeper + BookKeeper (3 компонента)
Коммерческие предложения:
- StreamNative Cloud (основатели Pulsar)
Sandbox: Бесплатно (10GB трафика)
Standard: $0.50/час за кластер (~$360/мес)
Enterprise: Контактная цена - Datastax Pulsar (ранее DataStax Luna)
Бесплатно: Community support
Enterprise: от $25000/год
Полное управление + Astra Streaming - AWS / GCP / Azure: Нет нативного managed-сервиса
Интересный факт: Yahoo! (создатели Pulsar) обрабатывают 100+ миллиардов сообщений в день на Pulsar.
Специализация для задач ИИ-агентов
Когда выбирать Kafka:
python
# Сценарии для Kafka:
1. # Обучение моделей на исторических данных
for message in kafka_consumer(seek_to_beginning=True):
# Переиграть ВСЕ события с начала времён
train_model(message)
2. # Feature Store для ML
# Каждое изменение фичей → событие в Kafka
topics:
- user_features
- product_features
- transaction_features
3. # Мониторинг дрейфа данных
# Сравнение распределений: production vs training
compare_distributions(
source=kafka_topic("production_events"),
target=kafka_topic("training_dataset")
)
Сильные стороны для ИИ:
- ✅ Единый источник истины (event sourcing)
- ✅ Возможность переигрывания (replay)
- ✅ Интеграция с Apache Spark/Flink для ML
- ✅ Зрелая экосистема (Kafka Connect для любых источников)
Когда выбирать RabbitMQ:
python
# Сценарии для RabbitMQ:
1. # Распределение задач между ИИ-агентами
# 1 задача = 1 сообщение = 1 обработчик
channel.basic_publish(
exchange='',
routing_key='image_queue',
body=image_data,
properties=pika.BasicProperties(
delivery_mode=2, # persistent
headers={'priority': 'high'}
)
)
2. # RPC-вызовы к моделям ИИ
# Синхронные запросы к ML-сервисам
result = rpc_client.call("predict", {"text": user_input})
3. # Управление оркестрацией агентов
# Разные очереди для разных типов агентов
queues:
- computer_vision_agents
- nlp_agents
- reinforcement_learning_agents
Сильные стороны для ИИ:
- ✅ Простота развертывания и отладки
- ✅ Отличная балансировка нагрузки
- ✅ Гибкая маршрутизация (exchanges, routing keys)
- ✅ Поддержка протоколов (AMQP, MQTT, STOMP)
Когда выбирать Pulsar:
python
# Сценарии для Pulsar:
1. # Глобально распределенные ИИ-агенты
# Агенты в разных регионах → один топик
producer = client.create_producer(
"persistent://global/ai/inference",
producer_name=f"region-{REGION}"
)
2. # Встроенная потоковая обработка
# Функции выполняются рядом с данными
from pulsar import Function
class PreprocessFunction(Function):
def process(self, input, context):
# Предобработка перед ИИ-моделью
return preprocess(input)
3. # Многоарендность для SaaS ИИ-сервисов
# Изоляция данных клиентов
tenants:
- company-a:/ai/vision/*
- company-b:/ai/nlp/*
- internal:/ai/research/*
Сильные стороны для ИИ:
- ✅ Гео-репликация из коробки
- ✅ Многоуровневое хранение (горячие/холодные данные)
- ✅ Встроенные функции (Pulsar Functions)
- ✅ Идеален для мульти-облачных ИИ-систем
Критерии выбора для разработчика ИИ-агентов
Выбирайте Kafka если:
- Объем данных: > 1TB событий в день
- Сценарий: Обучение моделей на исторических данных
- Экосистема: Используете Spark, Flink, или уже есть Kafka в компании
- Бюджет: Можете позволить себе managed-сервис или есть команда для поддержки
- Требования: Нужен единый источник истины для всех событий
Пример ИИ-проекта для Kafka:
yaml
project: "Рекомендательная система для 10M пользователей"
requirements:
- Обработка 1M событий/сек
- Хранение 30 дней истории
- Интеграция с Spark ML
- Возможность A/B тестов
choice: "Kafka + Kafka Streams + KSQL"
Выбирайте RabbitMQ если:
- Объем данных: < 100M сообщений в день
- Сценарий: Координация между микросервисами/агентами
- Команда: Маленькая, нужна простота и быстрый старт
- Протоколы: Нужна поддержка MQTT для IoT или STOMP для веб-сокетов
- Гарантии: Точная доставка, без потерь
Пример ИИ-проекта для RabbitMQ:
yaml
project: "Оркестрация компьютерного зрения на 100 камерах"
requirements:
- Балансировка между 20 GPU-серверами
- Приоритизация задач
- Dead letter queues для неудачных обработок
- Простой мониторинг
choice: "RabbitMQ с конкурентными потребителями"
Выбирайте Pulsar если:
- Архитектура: Cloud-native, multi-tenant
- География: Агенты распределены по миру
- Сценарий: Нужны встроенные stream processing функции
- Хранение: Требуется автоматическое управление жизненным циклом данных
- Масштаб: Планируете рост от стартапа до глобального решения
Пример ИИ-проекта для Pulsar:
yaml
project: "SaaS-платформа ИИ-аналитики для ритейла"
requirements:
- Изоляция данных клиентов
- Репликация между AWS и GCP
- Встроенная ETL для подготовки данных
- Платная подписка с лимитами трафика
choice: "Pulsar с многоарендностью и гео-репликацией"
Практический чеклист для выбора
Технические вопросы:
- Сколько данных?
< 10GB/день → RabbitMQ
10GB-1TB/день → Все три варианта
1TB/день → Kafka или Pulsar - Какая задержка критична?
< 10 мс → RabbitMQ
10-100 мс → Kafka/Pulsar
100 мс → Любой - Нужен ли replay данных?
Да → Kafka или Pulsar
Нет → Любой
Организационные вопросы:
- Размер команды:
1-2 человека → RabbitMQ (проще)
3-10 человек → Kafka (больше документации)
10+ человек → Pulsar (для сложных сценариев) - Бюджет:
Нет бюджета → RabbitMQ Community
$100-1000/мес → Managed Kafka или Pulsar
$1000/мес → Enterprise версии - Навыки команды:
Знакомы с Java/Scala → Kafka
Знакомы с Python/Go → RabbitMQ
Хотят latest tech → Pulsar
Для ИИ-агентов особо:
- Где работает агент?
Edge устройства → MQTT (RabbitMQ)
Облако → Kafka/Pulsar
Гибрид → Pulsar с гео-репликацией - Как обучается модель?
Online learning → RabbitMQ (быстрые обновления)
Batch training → Kafka (исторические данные)
Federated learning → Pulsar (распределенные агенты) - Мониторинг агентов:
Простое → RabbitMQ UI
Продвинутое → Kafka + Prometheus
Cloud-native → Pulsar + Kubernetes
Стартовые рекомендации для проектов ИИ-агентов
Стартап / MVP:
bash
# Начинайте с RabbitMQ - быстрее получить работающий прототип
docker run -d --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:management
# Пример агента на Python (30 строк):
import pika, json
def ai_agent_callback(ch, method, properties, body):
data = json.loads(body)
prediction = model.predict(data)
ch.basic_publish(exchange='',
routing_key=properties.reply_to,
body=json.dumps(prediction))
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='ai_requests')
channel.basic_consume(queue='ai_requests',
on_message_callback=ai_agent_callback)
channel.start_consuming()
Проект с инвестициями:
bash
# Используйте managed Kafka (Confluent Cloud или AWS MSK)
# Более масштабируемо, но сложнее начать
# Структура топиков для ИИ-платформы:
confluent kafka topic create raw-images
confluent kafka topic create processed-features
confluent kafka topic create model-predictions
confluent kafka topic create anomaly-alerts
Корпоративный / глобальный проект:
bash
# Pulsar для распределенных команд
helm install pulsar datastax-pulsar/pulsar
# Мульти-региональная архитектура:
pulsar-admin tenants create global-ai
pulsar-admin namespaces create global-ai/production
pulsar-admin namespaces set-clusters global-ai/production \
--clusters us-west,eu-central,ap-southeast
Тренды 2024 для ИИ-агентов и брокеров сообщений
- Конвергенция: Pulsar добавляет Kafka-совместимые API, Kafka добавляет Pulsar-подобные функции
- Serverless интеграция: Все три интегрируются с AWS Lambda, Google Cloud Functions
- MLOps интеграция:
Kafka → MLflow, Kubeflow
RabbitMQ → Ray, Dask
Pulsar → Seldon, BentoML - Edge computing:
RabbitMQ MQTT для IoT агентов
Kafka Connect с edge-коннекторами
Pulsar Proxy для edge-кластеров
Резюме для разработчика ИИ-агентов:
- Экспериментируете? → RabbitMQ (быстро, понятно)
- Строите data-intensive систему? → Kafka (проверено, надежно)
- Создаете cloud-native платформу? → Pulsar (современно, гибко)
Все три технологии отлично подходят для ИИ-агентов, но на разных этапах и для разных масштабов проекта.