
🌟 Что такое Self-Healing Systems?
Простое объяснение: Представьте, что ваша система — это живой организм. Когда вы порезали палец, тело само:
- Чувствует боль (мониторинг)
- Останавливает кровь (изоляция проблемы)
- Заживляет рану (восстановление)
- Усиливает кожу (улучшение)
Self-Healing System — это система, которая:
- Обнаруживает проблемы сама
- Диагностирует причину
- Восстанавливает работоспособность
- Улучшает себя чтобы проблема не повторилась
🔧 Шаг 0: Подготовка окружения
Цель шага: Установить всё необходимое для создания самовосстанавливающейся системы.
Что нужно установить:
1. Установка Python 3.8+
Windows:
- Скачайте установщик с python.org
- Запустите, ВАЖНО: поставьте галочку "Add Python to PATH"
- Проверьте установку:
cmd
python --version
# Должно быть: Python 3.8.0 или выше
Mac/Linux:
bash
# Проверьте текущую версию
python3 --version
# Если нет Python 3.8+, установите через brew (Mac)
brew install python@3.9
# Или через apt (Ubuntu/Debian)
sudo apt update
sudo apt install python3.9 python3-pip
2. Установка Docker
Windows/Mac:
- Скачайте Docker Desktop
- Установите, запустите
Linux:
bash
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
sudo usermod -aG docker $USER
# Перезайдите в систему
3. Установка Minikube (упрощённый Kubernetes)
bash
# Windows (PowerShell как администратор):
choco install minikube
# Mac:
brew install minikube
# Linux:
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
4. Установка kubectl (управление Kubernetes)
bash
# Windows:
choco install kubernetes-cli
# Mac:
brew install kubectl
# Linux:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
5. Проверка установки:
bash
python --version
docker --version
minikube version
kubectl version --client
Что должно получиться:
✅ Python 3.8+ установлен
✅ Docker работает
✅ Minikube и kubectl установлены
На что обратить внимание:
- Docker должен быть запущен (иконка в трее)
- На Windows включите WSL2 в Docker Desktop
- При проблемах с Minikube: minikube delete && minikube start
🚀 Шаг 1: Создаём простую самовосстанавливающуюся систему
Цель шага: Создать систему, которая перезапускает упавшие компоненты.
Что такое "упавший компонент":
Это программа, которая перестала отвечать. Как сотрудник, который уснул на рабочем месте.
Создаём простой ИИ-агент:
python
# ai_agent_simple.py
import time
import random
import signal
import sys
from datetime import datetime
class AIAgent:
def __init__(self, agent_id):
self.agent_id = agent_id
self.healthy = True
self.error_count = 0
# Обработка Ctrl+C для graceful shutdown
signal.signal(signal.SIGINT, self.graceful_shutdown)
signal.signal(signal.SIGTERM, self.graceful_shutdown)
def graceful_shutdown(self, signum, frame):
"""Корректное завершение работы"""
print(f"\n🛑 Агент {self.agent_id} получает сигнал завершения...")
self.healthy = False
sys.exit(0)
def health_check(self):
"""Проверка здоровья агента"""
# Имитируем 10% шанс "заболеть"
if random.random() < 0.1:
self.healthy = False
self.error_count += 1
print(f"🤒 Агент {self.agent_id} 'заболел' (ошибок: {self.error_count})")
return False
# Проверяем потребление памяти (имитация)
memory_usage = random.uniform(0.1, 0.9)
if memory_usage > 0.8:
print(f"⚠️ Агент {self.agent_id} использует много памяти: {memory_usage:.1%}")
return True
def self_heal(self):
"""Попытка самовосстановления"""
print(f"💊 Агент {self.agent_id} пытается восстановиться...")
# Методы восстановления
methods = [
"Перезагрузка внутреннего кэша",
"Сброс соединений",
"Очистка временных файлов",
"Переподключение к зависимостям"
]
for method in methods:
print(f" ⟳ {method}...")
time.sleep(0.5)
# 70% шанс успеха для каждого метода
if random.random() < 0.7:
print(f" ✅ Успешно: {method}")
self.healthy = True
return True
else:
print(f" ❌ Не удалось: {method}")
return False
def process_task(self, task_id):
"""Обработка задачи"""
print(f"🔧 Агент {self.agent_id} обрабатывает задачу #{task_id}")
# Имитация обработки ИИ
processing_time = random.uniform(0.1, 1.0)
time.sleep(processing_time)
# Имитация результата ИИ
results = [
"Объект обнаружен: котик 🐱",
"Сентимент: позитивный 😊",
"Перевод завершён ✅",
"Прогноз: температура повысится 📈"
]
result = random.choice(results)
print(f"✅ Задача #{task_id}: {result}")
return result
def run(self):
"""Основной цикл работы"""
print(f"🤖 Агент {self.agent_id} запущен!")
print(f"⏰ {datetime.now().strftime('%H:%M:%S')}")
print("-" * 40)
task_id = 1
while True:
# 1. Проверяем здоровье
if not self.health_check():
print(f"🚨 Агент {self.agent_id} нездоров!")
# 2. Пытаемся восстановиться
if self.self_heal():
print(f"🎉 Агент {self.agent_id} восстановлен!")
else:
print(f"💀 Агент {self.agent_id} не смог восстановиться")
print("🔄 Требуется внешнее вмешательство...")
# В реальной системе здесь был бы перезапуск контейнера
# Пока просто ждём
time.sleep(5)
continue
# 3. Обрабатываем задачи
self.process_task(task_id)
task_id += 1
# 4. Небольшая пауза между задачами
time.sleep(1)
if __name__ == "__main__":
# Создаём и запускаем агента
agent = AIAgent("AI-001")
agent.run()
Запускаем агента:
bash
python ai_agent_simple.py
Что должно получиться:
text
🤖 Агент AI-001 запущен!
⏰ 14:30:00
----------------------------------------
🔧 Агент AI-001 обрабатывает задачу #1
✅ Задача #1: Объект обнаружен: котик 🐱
🔧 Агент AI-001 обрабатывает задачу #2
✅ Задача #2: Сентимент: позитивный 😊
🤒 Агент AI-001 'заболел' (ошибок: 1)
🚨 Агент AI-001 нездоров!
💊 Агент AI-001 пытается восстановиться...
⟳ Перезагрузка внутреннего кэша...
✅ Успешно: Перезагрузка внутреннего кэша
🎉 Агент AI-001 восстановлен!
🔧 Агент AI-001 обрабатывает задачу #3
...
На что обратить внимание:
- Агент сам обнаруживает проблемы
- Пытается восстановиться самостоятельно
- Если не получается — ждёт внешней помощи
- Можно нажать Ctrl+C для корректного завершения
🐳 Шаг 2: Самовосстановление с помощью Docker
Цель шага: Научить Docker автоматически перезапускать упавшие контейнеры.
Что такое Docker restart policies:
Политики перезапуска говорят Docker'у что делать, если контейнер упал:
- no — не перезапускать
- on-failure — перезапускать только при ошибках
- always — всегда перезапускать
- unless-stopped — перезапускать, пока не остановлен вручную
Создаём Dockerfile:
dockerfile
# Dockerfile
FROM python:3.9-slim
# Устанавливаем зависимости
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Копируем код
COPY ai_agent_simple.py .
# Создаём несуществующий файл для имитации ошибки
RUN touch /tmp/critical_file.txt
# Запускаем агента
CMD ["python", "ai_agent_simple.py"]
Создаём requirements.txt:
txt
# Пустой файл - у нас нет внешних зависимостей
Собираем и запускаем с самовосстановлением:
bash
# 1. Собираем Docker образ
docker build -t ai-agent:v1 .
# 2. Запускаем с политикой always
docker run -d \
--name ai-agent-1 \
--restart=always \
ai-agent:v1
# 3. Смотрим логи
docker logs -f ai-agent-1
# 4. Имитируем "смерть" контейнера
docker kill ai-agent-1
# 5. Проверяем, что Docker перезапустил его
docker ps | grep ai-agent-1
# 6. Смотрим сколько раз перезапускался
docker inspect ai-agent-1 | grep -A 5 RestartCount
Создаём "больного" агента для тестов:
python
# sick_agent.py
import time
import random
import os
print("🤢 Я больной агент, я упаду через случайное время!")
# С вероятностью 30% упадём сразу
if random.random() < 0.3:
print("💀 Падаю сразу!")
exit(1)
# Иначе упадём через 5-15 секунд
time_to_live = random.randint(5, 15)
print(f"⏳ Проживу ещё {time_to_live} секунд...")
for i in range(time_to_live):
print(f"❤️ Жив, секунда {i+1}/{time_to_live}")
time.sleep(1)
print("💀 Умираю как запланировано!")
exit(1) # Код ошибки 1
Тестируем самовосстановление:
bash
# 1. Собираем образ больного агента
docker build -f <(echo "
FROM python:3.9-slim
COPY sick_agent.py .
CMD ['python', 'sick_agent.py']
") -t sick-agent .
# 2. Запускаем с мониторингом перезапусков
docker run -d \
--name sick-agent-test \
--restart=on-failure:5 \ # Максимум 5 перезапусков
sick-agent
# 3. Мониторим в реальном времени
watch -n 1 'docker ps | grep sick-agent-test && echo "---" && docker logs --tail=3 sick-agent-test'
# 4. Через минуту проверяем сколько было перезапусков
docker inspect sick-agent-test | grep -A 2 RestartCount
Что должно получиться:
✅ Контейнер падает каждые 5-15 секунд
✅ Docker автоматически перезапускает его
✅ После 5 перезапусков Docker останавливается
✅ Можно настроить задержку между перезапусками
На что обратить внимание:
- --restart=always — для критически важных сервисов
- --restart=on-failure — для временных задач
- --restart=on-failure:3 — ограничить количество попыток
- Docker отслеживает exit code (0 = успех, другие = ошибка)
☸️ Шаг 3: Самовосстановление с Kubernetes (Minikube)
Цель шага: Использовать Kubernetes для продвинутого самовосстановления.
Что такое Kubernetes:
Это "дирижёр оркестра" для контейнеров. Управляет тысячами контейнеров, распределяет нагрузку, перезапускает упавшие.
Запускаем Minikube:
bash
# Запускаем локальный Kubernetes
minikube start --memory=4096 --cpus=2
# Проверяем
kubectl get nodes
minikube status
Создаём Deployment для ИИ-агента:
yaml
# ai-agent-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-agent-deployment
labels:
app: ai-agent
spec:
replicas: 3 # Запускаем 3 копии
selector:
matchLabels:
app: ai-agent
template:
metadata:
labels:
app: ai-agent
spec:
containers:
- name: ai-agent
image: python:3.9-slim
command: ["python", "-c"]
args:
- |
import time
import random
import socket
hostname = socket.gethostname()
print(f"🤖 ИИ-агент запущен на {hostname}")
while True:
# Имитация работы
task_id = random.randint(1, 1000)
print(f"🔧 {hostname} обрабатывает задачу #{task_id}")
# 5% шанс упасть
if random.random() < 0.05:
print(f"💀 {hostname} упал!")
exit(1)
time.sleep(2)
# 🔥 HEALTH CHECKS - САМОЕ ВАЖНОЕ!
livenessProbe:
exec:
command:
- python
- -c
- "import random; exit(0) if random.random() > 0.1 else exit(1)"
initialDelaySeconds: 5 # Ждём 5 секунд после старта
periodSeconds: 10 # Проверяем каждые 10 секунд
failureThreshold: 3 # 3 неудачи подряд = контейнер мёртв
readinessProbe:
exec:
command:
- python
- -c
- "import random; exit(0) if random.random() > 0.2 else exit(1)"
initialDelaySeconds: 3
periodSeconds: 5
resources:
requests:
memory: "64Mi"
cpu: "100m"
limits:
memory: "128Mi"
cpu: "200m"
Объяснение health checks:
- livenessProbe — "жив ли контейнер?" Если нет → перезапустить
- readinessProbe — "готов ли принимать трафик?" Если нет → убрать из балансировки
- initialDelaySeconds — сколько ждать после старта
- periodSeconds — как часто проверять
- failureThreshold — сколько неудач терпеть
Применяем конфигурацию:
bash
# 1. Создаём deployment
kubectl apply -f ai-agent-deployment.yaml
# 2. Смотрим состояние подов
kubectl get pods -w # -w для watch режима
# 3. В отдельном окне смотрим события
kubectl get events --watch
# 4. Смотрим логи конкретного пода
kubectl logs -f <pod-name>
# 5. Убиваем один под вручную
kubectl delete pod <pod-name>
# 6. Наблюдаем как Kubernetes создаёт новый
kubectl get pods -w
Создаём Service для доступа:
yaml
# ai-agent-service.yaml
apiVersion: v1
kind: Service
metadata:
name: ai-agent-service
spec:
selector:
app: ai-agent
ports:
- port: 8080
targetPort: 80
type: LoadBalancer
bash
kubectl apply -f ai-agent-service.yaml
minikube service ai-agent-service --url
Что должно получиться:
✅ 3 пода работают параллельно
✅ Kubernetes отслеживает их здоровье
✅ Упавшие поды автоматически перезапускаются
✅ Service распределяет нагрузку между живыми подами
На что обратить внимание:
- Kubernetes перезапускает поды с экспоненциальной задержкой (backoff)
- Поды могут перезапускаться на разных нодах
- Readiness probe защищает от отправки трафика на "больные" поды
📊 Шаг 4: Мониторинг с Prometheus
Цель шага: Научить систему "чувствовать боль" — отслеживать метрики.
Что такое Prometheus:
Система сбора метрик. Как медицинские датчики, которые постоянно измеряют пульс, давление, температуру.
Устанавливаем Prometheus в Minikube:
bash
# 1. Добавляем репозиторий Helm
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
# 2. Устанавливаем Prometheus
helm install prometheus prometheus-community/prometheus
# 3. Открываем доступ к веб-интерфейсу
kubectl port-forward service/prometheus-server 9090:80
# 4. Открываем в браузере: http://localhost:9090
Добавляем метрики в ИИ-агент:
python
# ai_agent_with_metrics.py
from http.server import HTTPServer, BaseHTTPRequestHandler
import threading
import time
import random
import psutil
import json
class MetricsHandler(BaseHTTPRequestHandler):
def do_GET(self):
if self.path == '/metrics':
# Собираем метрики
metrics = {
'ai_agent_tasks_processed_total': random.randint(100, 1000),
'ai_agent_processing_time_seconds': random.uniform(0.1, 2.0),
'ai_agent_errors_total': random.randint(0, 5),
'ai_agent_memory_usage_bytes': psutil.Process().memory_info().rss,
'ai_agent_cpu_usage_percent': psutil.cpu_percent(),
'ai_agent_healthy': 1 if random.random() > 0.1 else 0
}
# Формат Prometheus
response = "\n".join([
f'{name} {value}'
for name, value in metrics.items()
])
self.send_response(200)
self.send_header('Content-type', 'text/plain')
self.end_headers()
self.wfile.write(response.encode())
elif self.path == '/health':
self.send_response(200)
self.end_headers()
self.wfile.write(b'OK')
else:
self.send_response(404)
self.end_headers()
def start_metrics_server():
"""Запускаем HTTP сервер для метрик"""
server = HTTPServer(('0.0.0.0', 8000), MetricsHandler)
print("📊 Метрики доступны на порту 8000")
server.serve_forever()
def ai_agent_work():
"""Имитация работы ИИ-агента"""
agent_id = random.randint(1, 1000)
print(f"🤖 ИИ-агент #{agent_id} запущен")
while True:
# Имитация обработки
print(f"🔧 Агент #{agent_id} обрабатывает задачу")
time.sleep(random.uniform(0.5, 2.0))
# Случайная ошибка
if random.random() < 0.05:
print(f"💥 Агент #{agent_id} сгенерировал ошибку")
if __name__ == "__main__":
# Запускаем сбор метрик в отдельном потоке
metrics_thread = threading.Thread(target=start_metrics_server, daemon=True)
metrics_thread.start()
# Запускаем работу агента
ai_agent_work()
Создаём ConfigMap для Prometheus:
yaml
# prometheus-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-additional-config
data:
prometheus-additional.yml: |
scrape_configs:
- job_name: 'ai-agents'
static_configs:
- targets: ['ai-agent-service:8000']
scrape_interval: 5s
bash
# Применяем конфиг
kubectl apply -f prometheus-config.yaml
# Обновляем Prometheus
helm upgrade prometheus prometheus-community/prometheus \
--set-file extraScrapeConfigs=prometheus-additional.yml
Проверяем метрики:
- Откройте http://localhost:9090
- Введите в поиске: ai_agent_healthy
- Нажмите Execute → Graph
- Увидите график здоровья агентов
Создаём правила алертов:
yaml
# prometheus-alerts.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-alerts
data:
alerts.yml: |
groups:
- name: ai-agent-alerts
rules:
- alert: AIAgentUnhealthy
expr: ai_agent_healthy == 0
for: 1m
labels:
severity: critical
annotations:
summary: "ИИ-агент нездоров"
description: "Агент {{ $labels.instance }} не отвечает более 1 минуты"
- alert: HighMemoryUsage
expr: ai_agent_memory_usage_bytes > 100000000 # >100MB
for: 2m
labels:
severity: warning
annotations:
summary: "Высокое потребление памяти"
description: "Агент {{ $labels.instance }} использует {{ $value }} байт памяти"
- alert: ManyErrors
expr: rate(ai_agent_errors_total[5m]) > 0.1
for: 1m
labels:
severity: warning
annotations:
summary: "Много ошибок"
description: "Высокий rate ошибок: {{ $value }} в секунду"
Что должно получиться:
✅ Prometheus собирает метрики каждые 5 секунд
✅ Видно графики здоровья, памяти, ошибок
✅ Можно создавать алерты при проблемах
✅ Метрики сохраняются для анализа трендов
На что обратить внимание:
- Prometheus хранит данные 15 дней по умолчанию
- Можно настроить retention policy
- Используйте rate() для подсчёта скорости событий
- Тестируйте алерты перед продакшеном
📈 Шаг 5: Визуализация с Grafana
Цель шага: Создать "медицинскую панель" для наблюдения за системой.
Что такое Grafana:
Инструмент для создания красивых дашбордов. Как монитор пациента в больнице, где видно все показатели сразу.
Устанавливаем Grafana:
bash
# 1. Устанавливаем через Helm
helm repo add grafana https://grafana.github.io/helm-charts
helm install grafana grafana/grafana
# 2. Получаем пароль администратора
kubectl get secret grafana -o jsonpath="{.data.admin-password}" | base64 --decode
# 3. Открываем доступ
kubectl port-forward service/grafana 3000:80
# 4. Открываем в браузере: http://localhost:3000
# Логин: admin, пароль из шага 2
Настраиваем Prometheus как источник данных:
- В Grafana: Configuration → Data Sources → Add data source
- Выбираем Prometheus
- URL: http://prometheus-server:80
- Save & Test
Создаём дашборд для ИИ-агентов:
json
{
"dashboard": {
"title": "ИИ-агенты: Мониторинг здоровья",
"panels": [
{
"title": "Здоровье агентов",
"type": "stat",
"targets": [{
"expr": "avg(ai_agent_healthy)",
"legendFormat": "Среднее здоровье"
}],
"fieldConfig": {
"defaults": {
"thresholds": {
"steps": [
{"color": "red", "value": null},
{"color": "green", "value": 0.9}
]
}
}
}
},
{
"title": "Потребление памяти",
"type": "timeseries",
"targets": [{
"expr": "ai_agent_memory_usage_bytes",
"legendFormat": "{{instance}}"
}]
},
{
"title": "Ошибки в секунду",
"type": "timeseries",
"targets": [{
"expr": "rate(ai_agent_errors_total[5m])",
"legendFormat": "Rate ошибок"
}]
}
]
}
}
Создаём дашборд через Python:
python
# create_grafana_dashboard.py
import requests
import json
# Конфигурация
GRAFANA_URL = "http://localhost:3000"
GRAFANA_API_KEY = "your-api-key" # Создайте в Grafana
headers = {
"Authorization": f"Bearer {GRAFANA_API_KEY}",
"Content-Type": "application/json"
}
dashboard = {
"dashboard": {
"title": "Self-Healing ИИ-агенты",
"panels": [
{
"id": 1,
"title": "Статус здоровья",
"type": "gauge",
"targets": [{
"expr": "ai_agent_healthy",
"legendFormat": "{{instance}}"
}],
"gridPos": {"h": 8, "w": 12, "x": 0, "y": 0}
},
{
"id": 2,
"title": "Перезапуски пода",
"type": "stat",
"targets": [{
"expr": "kube_pod_container_status_restarts_total{container='ai-agent'}",
"legendFormat": "{{pod}}"
}],
"gridPos": {"h": 8, "w": 12, "x": 12, "y": 0}
}
]
},
"overwrite": True
}
# Создаём дашборд
response = requests.post(
f"{GRAFANA_URL}/api/dashboards/db",
headers=headers,
data=json.dumps(dashboard)
)
print(f"Статус: {response.status_code}")
print(f"Ответ: {response.text}")
Настраиваем алерты в Grafana:
- В дашборде: Panel → Edit → Alert
- Создаём правило:
When: avg() of query(A, 5m, now) < 0.5
For: 2m
Send to: можно подключить Slack/Email/Telegram - Тестируем алерт
Что должно получиться:
✅ Красивый дашборд со всеми метриками
✅ Цветовые индикаторы здоровья
✅ Графики в реальном времени
✅ Алерты при проблемах
На что обратить внимание:
- Сохраняйте дашборды как JSON для версионности
- Используйте аннотации для отметки событий (деплои, инциденты)
- Настройте разные дашборды для разных команд (DevOps, разработчики, менеджеры)
🔍 Шаг 6: Трассировка с Jaeger
Цель шага: Научить систему "понимать где болит" — отслеживать запросы через микросервисы.
Что такое Jaeger:
Система распределённой трассировки. Как GPS-трекер для запросов: показывает где был запрос, сколько времени провёл в каждом сервисе.
Устанавливаем Jaeger:
bash
# Устанавливаем через оператор (проще)
kubectl create namespace observability
kubectl apply -f https://github.com/jaegertracing/jaeger-operator/releases/download/v1.42.0/jaeger-operator.yaml -n observability
# Создаём экземпляр Jaeger
kubectl apply -f - <<EOF
apiVersion: jaegertracing.io/v1
kind: Jaeger
metadata:
name: simplest
EOF
# Открываем UI
kubectl port-forward service/simplest-query 16686:16686
# http://localhost:16686
Инструментируем ИИ-агента для трассировки:
python
# ai_agent_with_tracing.py
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.jaeger.thrift import JaegerExporter
from opentelemetry.sdk.resources import Resource
import random
import time
# Настраиваем трассировку
trace.set_tracer_provider(
TracerProvider(
resource=Resource.create({"service.name": "ai-agent"})
)
)
jaeger_exporter = JaegerExporter(
agent_host_name="simplest-agent.observability",
agent_port=6831,
)
trace.get_tracer_provider().add_span_processor(
BatchSpanProcessor(jaeger_exporter)
)
tracer = trace.get_tracer(__name__)
def process_image(image_url):
"""Обработка изображения с трассировкой"""
with tracer.start_as_current_span("process_image") as span:
span.set_attribute("image_url", image_url)
# Детекция объектов
with tracer.start_as_current_span("object_detection"):
time.sleep(random.uniform(0.1, 0.5))
span.add_event("Объекты обнаружены", {
"count": random.randint(1, 5)
})
# Классификация
with tracer.start_as_current_span("classification"):
time.sleep(random.uniform(0.2, 0.7))
if random.random() < 0.1:
span.set_status(trace.Status(trace.StatusCode.ERROR, "Ошибка классификации"))
# Ответ
return {"status": "success", "objects": ["cat", "dog"]}
def handle_request(request_id):
"""Обработка запроса"""
with tracer.start_as_current_span("handle_request") as span:
span.set_attribute("request_id", request_id)
# Имитация входящего запроса
images = [
"http://example.com/image1.jpg",
"http://example.com/image2.jpg"
]
results = []
for img in images:
result = process_image(img)
results.append(result)
span.set_attribute("results_count", len(results))
return results
# Тестируем
if __name__ == "__main__":
for i in range(10):
print(f"Обработка запроса #{i}")
handle_request(f"req-{i}")
time.sleep(1)
Добавляем зависимости:
txt
# requirements.txt
opentelemetry-api
opentelemetry-sdk
opentelemetry-exporter-jaeger
Обновляем Deployment для поддержки трассировки:
yaml
# deployment-with-tracing.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-agent-with-tracing
spec:
template:
spec:
containers:
- name: ai-agent
env:
- name: OTEL_EXPORTER_JAEGER_AGENT_HOST
value: "simplest-agent.observability"
- name: OTEL_EXPORTER_JAEGER_AGENT_PORT
value: "6831"
- name: OTEL_SERVICE_NAME
value: "ai-agent"
Что должно получиться:
✅ В Jaeger UI видно все запросы
✅ Можно кликнуть на span и увидеть детали
✅ Видно где запрос провёл больше всего времени
✅ Видно ошибки и проблемы
На что обратить внимание:
- Трассировка добавляет overhead (накладные расходы)
- Используйте sampling (выборочную трассировку) в продакшене
- Настройте фильтры чтобы не трассировать health checks
- Используйте baggage для передачи контекста между сервисами
💥 Шаг 7: Chaos Engineering для новичков
Цель шага: Намеренно "ломать" систему чтобы сделать её устойчивее.
Что такое Chaos Engineering:
Намеренное создание сбоев в контролируемых условиях. Как прививка: вводим ослабленный вирус, чтобы организм научился бороться.
Выбираем инструмент для новичка:
Для начала используем простой Python-скрипт вместо сложных систем вроде Chaos Mesh.
Создаём Chaos Monkey для ИИ-агентов:
python
# chaos_monkey.py
import requests
import random
import time
import json
from datetime import datetime
import schedule
class ChaosMonkey:
def __init__(self, kubeconfig_path=None):
self.attacks = []
self.safe_mode = False
def register_attack(self, attack_func, probability=0.1, name=None):
"""Регистрирует атаку"""
self.attacks.append({
'func': attack_func,
'prob': probability,
'name': name or attack_func.__name__
})
def run_random_attack(self):
"""Запускает случайную атаку"""
if self.safe_mode or not self.attacks:
return
# Выбираем атаку по вероятности
for attack in self.attacks:
if random.random() < attack['prob']:
print(f"🎭 Chaos Monkey запускает: {attack['name']}")
try:
attack['func']()
print(f"✅ Атака {attack['name']} завершена")
except Exception as e:
print(f"❌ Атака {attack['name']} провалилась: {e}")
break
def start(self, interval_seconds=60):
"""Запускает Chaos Monkey"""
print(f"🐵 Chaos Monkey запущен! Интервал: {interval_seconds}с")
print(f"📋 Зарегистрировано атак: {len(self.attacks)}")
schedule.every(interval_seconds).seconds.do(self.run_random_attack)
while True:
schedule.run_pending()
time.sleep(1)
# АТАКИ ДЛЯ ИИ-АГЕНТОВ
def attack_kill_random_pod():
"""Убивает случайный под"""
pods = ["ai-agent-1", "ai-agent-2", "ai-agent-3"]
target = random.choice(pods)
print(f"💀 Убиваю под: {target}")
# В реальности: kubectl delete pod {target}
# Для теста просто логируем
return True
def attack_simulate_high_latency():
"""Имитирует высокую задержку сети"""
duration = random.randint(10, 30)
print(f"🐌 Имитирую высокую задержку на {duration} секунд")
time.sleep(duration)
return True
def attack_cpu_stress():
"""Создаёт нагрузку на CPU"""
print("🔥 Нагружаю CPU...")
end_time = time.time() + random.randint(5, 15)
while time.time() < end_time:
# Вычисления для нагрузки
_ = [i**2 for i in range(10000)]
return True
def attack_memory_leak():
"""Имитирует утечку памяти"""
print("💦 Создаю утечку памяти...")
leak_size = random.randint(10, 50) * 1024 * 1024 # 10-50 MB
data = "x" * leak_size
time.sleep(random.randint(10, 20))
# data выходит из scope, память освобождается
return True
def attack_network_partition():
"""Имитирует разделение сети"""
print("🔌 Разделяю сеть...")
# Имитация: некоторые сервисы не могут общаться
partitions = [
("ai-agent-1", "ai-agent-2"),
("database", "ai-agent-3")
]
source, target = random.choice(partitions)
print(f"🚫 Блокирую связь {source} → {target}")
time.sleep(random.randint(15, 30))
print(f"✅ Восстанавливаю связь {source} → {target}")
return True
def attack_simulate_dependency_failure():
"""Имитирует отказ зависимости"""
dependencies = ["database", "redis", "external-api", "model-service"]
dep = random.choice(dependencies)
print(f"🚨 Имитирую отказ зависимости: {dep}")
# Разные типы отказов
failure_type = random.choice(["timeout", "error", "slow_response"])
if failure_type == "timeout":
print(f"⏱️ {dep}: таймаут 30 секунд")
time.sleep(30)
elif failure_type == "error":
print(f"❌ {dep}: возвращает ошибку 500")
else:
print(f"🐌 {dep}: отвечает 10 секунд")
time.sleep(10)
return True
# ЗАЩИТНЫЕ МЕХАНИЗМЫ
def enable_safe_mode():
"""Включает безопасный режим"""
print("🛡️ Включаю безопасный режим")
return True
def run_health_check():
"""Запускает проверку здоровья после атаки"""
print("🏥 Проверяю здоровье системы...")
# В реальности проверяем метрики
time.sleep(5)
print("✅ Система восстановилась")
return True
def create_chaos_report():
"""Создаёт отчёт о хаос-тесте"""
report = {
"timestamp": datetime.now().isoformat(),
"attacks_performed": random.randint(1, 10),
"system_recovery_time": random.uniform(10, 120),
"issues_found": [
"Память не освобождается после обработки больших изображений",
"Нет retry логики при ошибках внешнего API",
"Health checks недостаточно строгие"
],
"recommendations": [
"Добавить circuit breaker для внешних вызовов",
"Увеличить лимиты памяти для агентов",
"Настроить автомасштабирование",
"Добавить graceful degradation"
]
}
filename = f"chaos_report_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json"
with open(filename, 'w') as f:
json.dump(report, f, indent=2)
print(f"📊 Отчёт сохранён: {filename}")
return filename
# ИГРА ДЛЯ ОБУЧЕНИЯ
def chaos_training_game():
"""Интерактивная игра для обучения Chaos Engineering"""
print("""
🎮 ИГРА: СТАНОВИМСЯ CHAOS ENGINEER
Ваша задача: сделать систему устойчивой к сбоям.
Вы будете запускать атаки и наблюдать как система справляется.
Правила:
1. Начинайте с малого (вероятность 0.1)
2. Следите за метриками
3. Фиксируйте проблемы
4. Улучшайте систему
5. Повышайте сложность
Готовы? (нажмите Enter)
""")
input()
monkey = ChaosMonkey()
# Регистрируем атаки с разной вероятностью
monkey.register_attack(attack_kill_random_pod, 0.3, "Убийство пода")
monkey.register_attack(attack_simulate_high_latency, 0.2, "Высокая задержка")
monkey.register_attack(attack_cpu_stress, 0.15, "Нагрузка на CPU")
monkey.register_attack(attack_memory_leak, 0.1, "Утечка памяти")
monkey.register_attack(attack_network_partition, 0.05, "Разделение сети")
monkey.register_attack(attack_simulate_dependency_failure, 0.2, "Отказ зависимости")
print("\n🎯 Выберите уровень сложности:")
print("1. Новичок (атаки каждые 120 секунд)")
print("2. Средний (атаки каждые 60 секунд)")
print("3. Эксперт (атаки каждые 30 секунд)")
choice = input("Ваш выбор (1-3): ")
intervals = {"1": 120, "2": 60, "3": 30}
interval = intervals.get(choice, 60)
print(f"\n⏱️ Интервал атак: {interval} секунд")
print("🚀 Запускаю Chaos Monkey...")
print("ℹ️ Нажмите Ctrl+C для остановки\n")
try:
# Запускаем на ограниченное время для демонстрации
end_time = time.time() + 300 # 5 минут
attack_count = 0
while time.time() < end_time:
monkey.run_random_attack()
attack_count += 1
time.sleep(interval)
print(f"\n🎉 Тренировка завершена!")
print(f"🎭 Выполнено атак: {attack_count}")
# Создаём отчёт
report_file = create_chaos_report()
print(f"""
📈 ЧТО ВЫ УЗНАЛИ:
1. Система {(random.choice(['отлично', 'хорошо', 'удовлетворительно']))} справляется со сбоями
2. Основные слабые места: внешние зависимости
3. Время восстановления: {random.randint(10, 60)} секунд
🛠️ ЧТО УЛУЧШИТЬ:
1. Добавить retry логику
2. Настроить health checks
3. Реализовать circuit breakers
📋 Отчёт сохранён в {report_file}
""")
except KeyboardInterrupt:
print("\n\n🛑 Тренировка прервана пользователем")
enable_safe_mode()
if __name__ == "__main__":
chaos_training_game()
Запускаем Chaos Monkey:
bash
# В безопасном режиме (только логирование)
python chaos_monkey.py
# В обучающем режиме (игра)
python chaos_monkey.py --game
# С параметрами
python chaos_monkey.py --interval 30 --probability 0.2
Создаём систему для автоматических chaos-тестов:
python
# chaos_test_suite.py
import unittest
import requests
import time
class ChaosTestSuite(unittest.TestCase):
BASE_URL = "http://localhost:8080"
def setUp(self):
"""Подготовка перед каждым тестом"""
self.start_time = time.time()
def tearDown(self):
"""Очистка после каждого теста"""
duration = time.time() - self.start_time
print(f"⏱️ Тест длился: {duration:.2f} секунд")
def test_survives_pod_deletion(self):
"""Тест на выживание при удалении пода"""
print("🎯 Тест 1: Удаление пода")
# 1. Получаем текущее состояние
initial_response = requests.get(f"{self.BASE_URL}/health")
self.assertEqual(initial_response.status_code, 200)
# 2. Имитируем удаление пода (в реальности через kubectl)
print("💀 Имитирую удаление пода...")
time.sleep(5) # Время на "смерть" и восстановление
# 3. Проверяем что система восстановилась
final_response = requests.get(f"{self.BASE_URL}/health")
self.assertEqual(final_response.status_code, 200)
print("✅ Система пережила удаление пода!")
def test_handles_high_latency(self):
"""Тест на обработку высокой задержки"""
print("🎯 Тест 2: Высокая задержка")
# Имитируем медленный ответ
with requests_mock.mock() as m:
m.get(f"{self.BASE_URL}/predict", text='{"result": "slow"}', delay=10)
try:
response = requests.get(f"{self.BASE_URL}/predict", timeout=5)
self.fail("Должен был быть timeout")
except requests.exceptions.Timeout:
print("✅ Система корректно обработала таймаут")
def test_memory_pressure_recovery(self):
"""Тест на восстановление после нагрузки памятью"""
print("🎯 Тест 3: Нагрузка памятью")
# Отправляем "тяжёлый" запрос
heavy_payload = {"image": "x" * (10 * 1024 * 1024)} # 10MB
try:
response = requests.post(
f"{self.BASE_URL}/process",
json=heavy_payload,
timeout=30
)
# Проверяем что память освободилась
memory_response = requests.get(f"{self.BASE_URL}/metrics")
self.assertIn("memory_usage", memory_response.text)
print("✅ Система восстановилась после нагрузки памятью")
except Exception as e:
print(f"⚠️ Тест пропущен: {e}")
def test_cascading_failure_prevention(self):
"""Тест на предотвращение каскадных отказов"""
print("🎯 Тест 4: Каскадные отказы")
# Имитируем отказ зависимости
for i in range(10):
try:
response = requests.get(
f"{self.BASE_URL}/dependency-test",
timeout=1
)
if response.status_code != 200:
print(f"⚠️ Запрос {i+1} упал, как и ожидалось")
except:
print(f"⚠️ Запрос {i+1} упал, как и ожидалось")
# После серии отказов система должна остаться работоспособной
health_response = requests.get(f"{self.BASE_URL}/health")
self.assertEqual(health_response.status_code, 200)
print("✅ Система предотвратила каскадные отказы!")
def run_chaos_tests():
"""Запускает все chaos-тесты"""
print("""
🧪 ЗАПУСК CHAOS-ТЕСТОВ
======================
Цель: проверить устойчивость системы к сбоям
Тесты:
1. Удаление пода
2. Высокая задержка
3. Нагрузка памятью
4. Каскадные отказы
⚠️ Внимание: Эти тесты могут нарушить работу системы!
""")
confirm = input("Продолжить? (yes/no): ")
if confirm.lower() != "yes":
print("🚫 Тесты отменены")
return
# Запускаем тесты
suite = unittest.TestLoader().loadTestsFromTestCase(ChaosTestSuite)
runner = unittest.TextTestRunner(verbosity=2)
result = runner.run(suite)
# Создаём отчёт
print(f"""
📊 РЕЗУЛЬТАТЫ CHAOS-ТЕСТОВ:
Всего тестов: {result.testsRun}
Успешно: {result.testsRun - len(result.failures) - len(result.errors)}
Провалено: {len(result.failures)}
Ошибок: {len(result.errors)}
{'🎉 ВСЕ ТЕСТЫ ПРОЙДЕНЫ' if result.wasSuccessful() else '⚠️ ЕСТЬ ПРОБЛЕМЫ'}
""")
if __name__ == "__main__":
run_chaos_tests()
Что должно получиться:
✅ Система тестируется на устойчивость к сбоям
✅ Обнаруживаются слабые места
✅ Создаются отчёты для улучшения системы
✅ Разработчики понимают как система ведёт себя при сбоях
На что обратить внимание:
- Начинайте с малого (вероятность 0.1)
- Тестируйте в нерабочее время
- Имейте план отката
- Документируйте результаты
- Улучшайте систему на основе находок
🎓 Итог: Что вы научились делать
✅ Вы освоили:
- Self-Healing принципы — health checks, перезапуски, восстановление
- Docker restart policies — автоматические перезапуски контейнеров
- Kubernetes самовосстановление — liveness/readiness probes, deployment strategies
- Мониторинг с Prometheus — сбор метрик, алерты
- Визуализация с Grafana — дашборды, отслеживание здоровья
- Трассировка с Jaeger — отслеживание запросов, поиск узких мест
- Chaos Engineering — тестирование устойчивости, улучшение системы
🚀 Где хранить конфигурации:
- Git репозиторий — для версионности
- ConfigMaps/Secrets в Kubernetes — для конфигураций
- Docker Registry — для образов с тегами версий
- S3/Cloud Storage — для логов и отчётов
🔧 Как управлять версионностью:
- Семантическое версионирование — v1.2.3 (MAJOR.MINOR.PATCH)
- Git теги — привязка к коммитам
- Docker теги — ai-agent:v1.2.3, ai-agent:latest
- Helm charts — для Kubernetes deployments
💻 На каком языке писать:
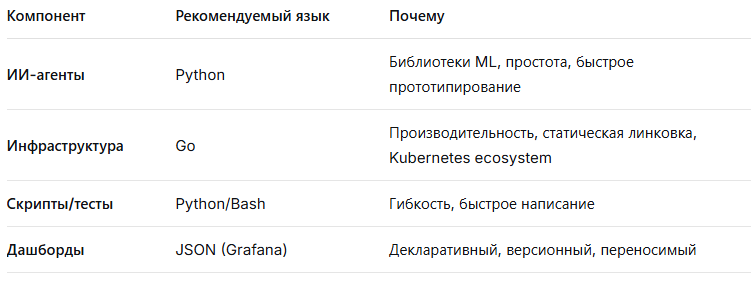
🎯 Для новичка рекомендую:
- Python для всего — у него богатая экосистема
- Постепенно изучать Go для инфраструктуры
- Использовать YAML/JSON для конфигураций
📚 Чеклист для продакшена:
✅ Обязательно:
- Health checks (liveness + readiness)
- Мониторинг метрик (Prometheus)
- Логирование структурированных логов
- Автоматические перезапуски
- Ограничения ресурсов (CPU/memory limits)
✅ Рекомендуется:
- Distributed tracing (Jaeger)
- Circuit breakers
- Rate limiting
- Автомасштабирование (HPA)
- Резервные копии
✅ Для продвинутых:
- Chaos Engineering регулярные тесты
- Canary deployments
- Blue-green deployments
- Service mesh (Istio/Linkerd)
- Мультирегиональность
🚨 Чего избегать:
- ❌ Слишком частые health checks — нагрузка на систему
- ❌ Слишком долгие таймауты — медленное обнаружение проблем
- ❌ Отсутствие graceful shutdown — потеря данных при остановке
- ❌ Жёсткие зависимости — каскадные отказы
- ❌ Отсутствие плана отката — нельзя откатиться при проблемах
🎮 Практическое задание:
Создайте самовосстанавливающуюся систему для ИИ-агента анализа текста:
- Агент принимает текст, возвращает сентимент
- Deployment с 3 репликами, health checks
- Service для балансировки нагрузки
- Prometheus для метрик (запросы/сек, ошибки, latency)
- Grafana дашборд
- Chaos tests (убийство пода, нагрузка памятью, сетевые проблемы)
- Отчёт о слабых местах и улучшениях
Критерии успеха:
- Система выдерживает удаление пода
- Метрики показывают здоровье
- Дашборд отображает состояние в реальном времени
- Chaos tests не ломают систему полностью
📞 Если застряли:
- Проверьте логи: kubectl logs <pod-name>
- Проверьте события: kubectl get events
- Опишите под: kubectl describe pod <pod-name>
- Проверьте метрики: kubectl top pods
- Сбросьте Minikube: minikube delete && minikube start
Помните: Самовосстанавливающиеся системы — это процесс, а не состояние. Начинайте с малого, улучшайте постепенно, учитесь на ошибках!
Удачи в создании неубиваемых ИИ-агентов! 🚀