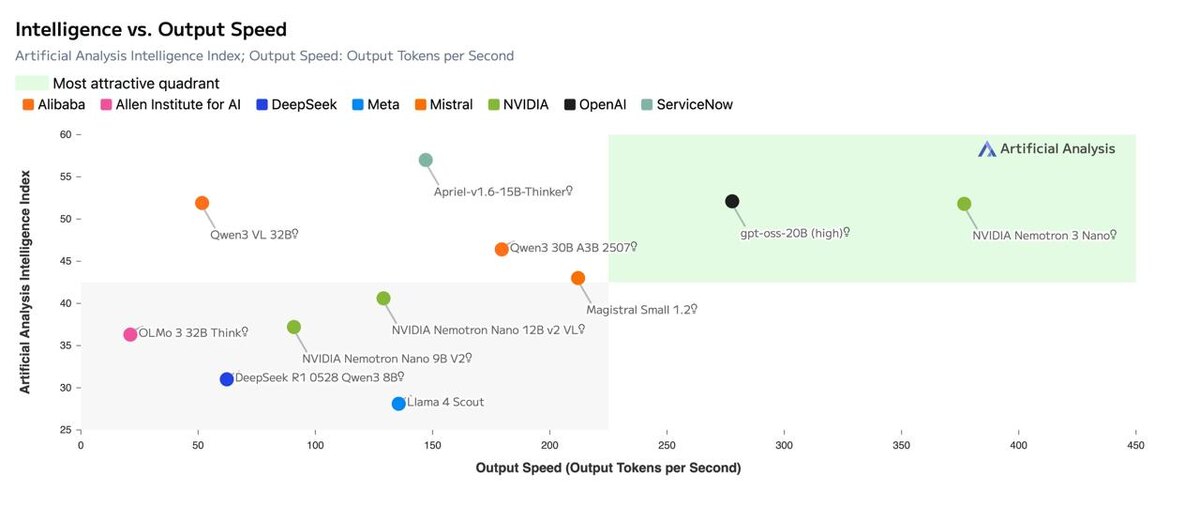
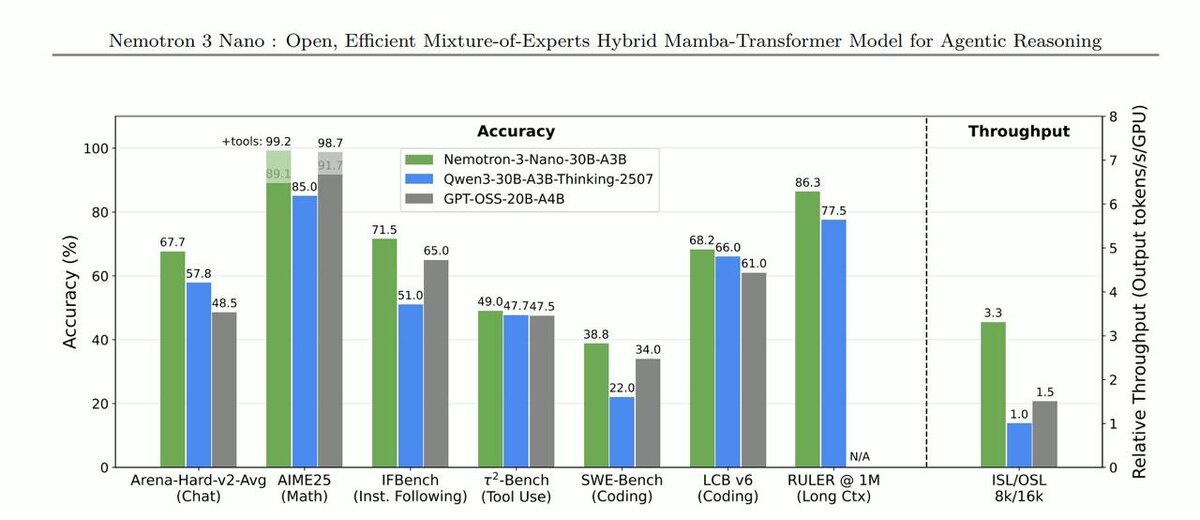
NVIDIA представила новое открытое семейство моделей Nemotron 3
Nemotron 3 Nano - это универсальная модель для рассуждений и чата, ориентированная на локальный запуск.
Ключевые характеристики:
- MoE-архитектура: 30B параметров всего, ~3.5B активных
- Контекст до 1 миллиона токенов
- Гибридная архитектура:
- 23 слоя Mamba-2 + MoE
- 6 attention-слоёв
- Баланс между скоростью и качеством рассуждений
Требования:
- необходимо около 24 ГБ видеопамяти для локального запуска
Модель хорошо подходит для длинных диалогов, анализа документов и reasoning-задач
Интересный пример того, как MoE и Mamba начинают реально снижать требования к железу, сохраняя масштаб контекста и качество.
Nemotron 3 Super и Nemotron 3 Ultra значительно превосходят Nano по масштабу - примерно в 4 раза и 16 раз соответственно. Но ключевой момент здесь не просто в размере моделей, а в том, как NVIDIA удалось увеличить мощность без пропорционального роста стоимости инференса.
Для обучения Super и Ultra используется NVFP4 и новая архитектура Latent Mixture of Experts. Она позволяет задействовать в четыре раза больше экспертов при той же стоимости инференса. По сути, модель становится «умнее» за счёт более гибкого выбора экспертов, а не за счёт постоянной активации всех параметров.
Дополнительно применяется Multi-Token Prediction, что ускоряет обучение и улучшает качество рассуждений на длинных последовательностях. Это особенно важно для agentic и multi-agent сценариев, где модели работают с длинным контекстом и сложными цепочками решений.
NVIDIA публикует не только веса, но и данные для предобучения и постобучения, а также технические детали, которые объясняют, почему эти модели одновременно быстрые и сильные.
Такой уровень открытости - редкость для моделей этого масштаба и хороший сигнал для индустрии.
Guide: https://docs.unsloth.ai/models/nemotron-3
GGUF: https://huggingface.co/unsloth/Nemotron-3-Nano-30B-A3B-GGUF
lmstudio: https://lmstudio.ai/models/nemotron-3
#AI #LLM #NVIDIA #Nemotron3 #OpenSource #MachineLearning