
Что случится с моими AI-агентами, если завтра OpenRouter перестанет быть доступным в РФ? Не «если вдруг когда-нибудь», а вполне конкретное завтра. Я потратил несколько недель на то, чтобы собрать примерный план на подобный сценарий и делюсь результатами.
Почему я вообще об этом думаю
Месяц назад я проснулся и увидел, что мой основной workflow в n8n лежит. OpenRouter словил какие-то проблемы то ли с биллингом, то ли с сетью. Это была не блокировка, просто технический сбой. Чинили часов шесть. За это время я потерял около десятка обработанных цепочек. Не сказать, что там было что-то прям очень важное, но я задумался, а что если там вместо 30 упавших вызовов было 3000 и, например, вместо парсинга/автоматизации там был вполне работающий MVP, за который уже платили бы клиенты...
В целом жить можно, но я такой тип личности, который любит накручивать и следующая мысль, меня добила: «а что если это не на шесть часов, а навсегда?»
Не то чтобы я параноик. Но когда твой бизнес зависит от сервиса, который в любой момент может сказать «извините, ваш регион больше не поддерживается» – не паранойя, это risk management.
Я начал копать. Смотрел, что делают крупные компании, что пишут в профильных чатах, какие альтернативы реально работают. Собрал всё в кучу и вот что получилось.
Локальные модели в российских облаках
Моя ставка это open-source модели (Qwen, DeepSeek, GLM), развёрнутые на российских облачных платформах.
Почему именно так:
Qwen3 и DeepSeek-V3 – это не какие-то второсортные альтернативы. DeepSeek-V3 реально конкурирует с GPT-4 на задачах кодинга и логики. Qwen3 сносно работает с русским языком – лучше, чем многие западные модели старого поколения.
Помимо этих двух ребят, ещё присматриваюсь к этим:
Про GigaChat и YandexGPT
Тут всё неоднозначно, и я не буду делать вид, что это идеальные решения.
Что реально хорошо:
Обе модели полностью адаптированы под русский язык. Серверы на территории РФ, можно закрепить SLA в договоре.
GigaChat от Сбера активно развивается. В декабре 2025-го они выложили в open-source модель на 702 миллиарда параметров – крупнейшую русскоязычную LLM. Лидирует в бенчмарке MERA для русского языка, превосходит GigaChat Max 2 и Gemini 2.0 Flash на русском.
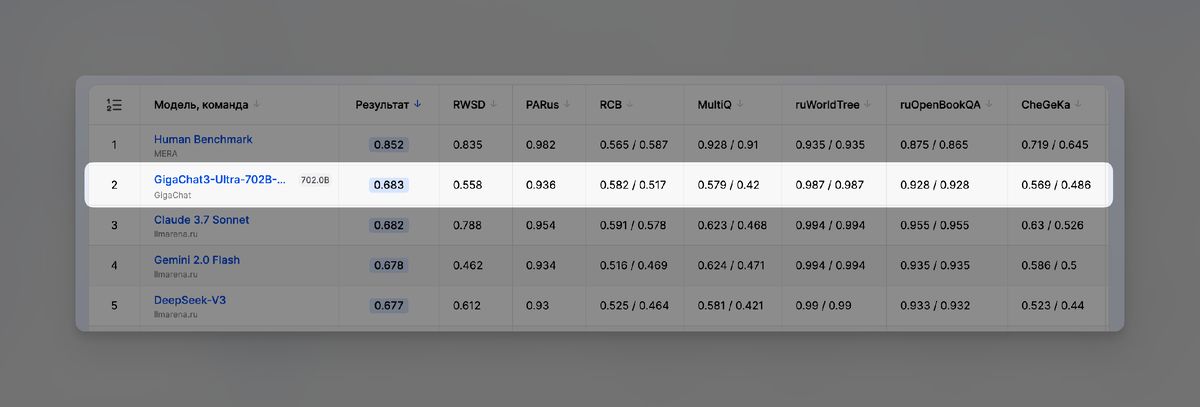
Что напрягает:
Тарифы выше, чем у локальных решений при массовом использовании. Требуется интернет и API-ключи — то есть это не полная автономность. Для этого материала я не смог найти в открытых источниках их итоговый предоставленный SLO за 2025 год. Будем верить, что ребята поддерживают высокий уровень стабильности.
И главное: я пока не уверен в стабильности работы с инструментами (function calling). А для моих AI-агентов это критично – 80% полезной работы агента это именно адекватное использование тулзов. Бенчмарки красивые, а вот как модель поведёт себя в реальном workflow с десятком интеграций – большой вопрос.
Ещё один важный момент: у всех моих AI-агентов системные промпты, инструкции и подсказки — на английском. Сделал это для экономии токенов и потому, что изначально вся архитектура была заточена именно под зарубежные LLM. На практике замечал, что отечественные реализации из-за этого начинают работать не так эффективно.
Мой вердикт: использовать как резервный уровень для критичных задач, а не как основу. Основа – open-source развёрнутый в облачном сервисе.
Guardrails: защита данных уже сейчас
Независимо от того, какой провайдер я использую, есть одна штука, которую я делаю уже сейчас – очистка данных перед отправкой.
Писал об этом в блоге: в n8n появился нативный узел Guardrails. Настраивается без кода, умеет ловить персональные данные, секретные ключи, URL, поддерживает кастомные regex-правила.
Зачем это нужно:
- Минимизация рисков – даже если OpenRouter никуда не денется, отправлять чужие паспортные данные во внешний API это так себе идея. Вот просто поверьте, порой в чат-бот шлют и не такое... А кто потом виноват будет? Правильно, создатель бота.
- Проще миграция – когда данные уже очищены на входе, мне всё равно, через какой провайдер они идут дальше
- Compliance – если завтра придёт аудит, у меня есть ответ на вопрос «как вы защищаете ПДн»
Работает в двух режимах:
- Без LLM (Sanitize Text) – быстрая очистка по паттернам, ловит стандартные форматы
- С LLM (Check Text for Violations) – глубокая проверка на jailbreak, nsfw, topical alignment. Вот тут как раз и пригодятся небольшие open-source LLM модели на РФ серверах.
Я использую первый режим на входе всех агентов, которые работают с клиентскими данными. Накладные расходы минимальны, а головной боли сильно меньше.
Evaluation: как я тестирую резервные модели
Окей, у меня есть три-четыре потенциальные замены для текущего провайдера. Как понять, какая из них реально сработает для моих задач?
Ответ: n8n Evaluation. Встроенная система для тестирования AI-цепочек.
Механика простая:
- Готовишь табличку с тестовыми примерами: входные данные и эталонный ответ
- Настраиваешь ветку с логикой оценки
- Запускаешь прогон и смотришь score
У меня сейчас несколько десятков проверочных кейсов для основных workflow. Раньше на ручную проверку уходили дни. Теперь меняю модель, жму кнопку, через 20-30 минут вижу результат.
Что я тестирую:
- Качество ответов на русском языке
- Работу с function calling
- Скорость обработки
- Стабильность при повторных запросах
Мой совет: не верьте чужим бенчмаркам. Соберите свои тесты под свои задачи. То, что модель хорошо пишет стихи и посты для продаж, не значит, что она правильно вызовет ваш API.
Если вдруг есть свой домашний сервер
Если облачные провайдеры – это план Б, то локальный запуск – план В. На случай, если вообще всё ляжет.
Ollama – Простой, лёгкий, OpenAI-совместимый API из коробки. Запускается одной командой, работает даже на MacBook M1. Писал даже подробную инструкцию, как всё это у себя организовать.
vLLM – пропускная способность выше, чем у Ollama. Но раскрывается на полную только тогда, когда у вас планируется кластер GPU.
Квантизация – это то, что делает локальный запуск реальным на обычном железе:
- 4-битная квантизация GGUF сокращает модель примерно в 7-8 раз
- Потеря качества обычно минимальна (но зависит конечно от рук того, кто проводил квантизацию)
- Энергопотребление в среднем падает более чем на 50%
Мой текущий стек и план миграции
Вот как это выглядит у меня сейчас:
• Основной провайдер: OpenRouter (GPT-4, Claude)
• Резерв первого уровня: Отечественное облако №1, где развернуты локальные LLM (Qwen / GigaChat)
• Резерв второго уровня: Отечественное облако №2 с автоматическим fallback (если ляжет облако 1)
• Локальный резерв: Нет, ищу подходящее железо. Если вдруг у вас есть в этом опыт – буду рад услышать ваше мнение в комментариях! A100 / H100 не предлагать.
План миграции:
• Шаг 1 (сделано): Все агенты используют абстракцию над провайдером. Смена endpoint – одна строка конфига.
• Шаг 2 (сделано): Guardrails на входе всех workflow с клиентскими данными.
• Шаг 3 (в процессе): Еженедельное тестирование резервных моделей через Evaluation. Слежу за качеством, чтобы при переключении не было сюрпризов.
• Шаг 4 (планируется): Добавить в агенты автоматическое переключение при ошибках провайдера.
Чего я не знаю и что может пойти не так
Производительность под нагрузкой. Я тестировал резервные модели на своих объёмах. Но что будет, если весь ру-рынок одновременно побежит на сервисы, которые я выбрал – не знаю. Могут быть очереди, задержки, проблемы со стабильностью.
Function calling. Скорее всего этот риск сработает. Open-source модели догоняют по качеству текста, но работа с инструментами – всё ещё не самое стабильное место. Сложные цепочки вызовов могут ломаться.
Долгосрочная поддержка. Отечественные облака сегодня активно развиваются. Но что будет через год? Не изменят ли тарифы в 10 раз? Будет ли и дальше сходиться та же юнит-экономика?
Скрытые ограничения. Сейчас многие сервисы дают бесплатный доступ или низкие тарифы, чтобы привлечь пользователей. Это не будет длиться вечно.
Мой главный takeaway: нет идеального решения. Есть только диверсификация. Несколько провайдеров, несколько уровней резерва, регулярное тестирование. Паранойя? Может быть. Но лучше потратить время на подготовку, чем потом в панике искать решение.
Выводы и чек-лист для таких же как я
Локальные и отечественные LLM могут закрыть 70-80% потребностей при правильной архитектуре. Это не полная замена GPT и Claude – творческие задачи, сложные рассуждения, edge cases всё ещё лучше у западных моделей. Но для автоматизации рутины, обработки текстов, работы с русским контентом – вполне достаточно.
Чек-лист подготовки:
- Абстрагировать код от конкретного провайдера (один конфиг для смены endpoint)
- Настроить Guardrails для очистки данных перед отправкой
- Собрать тестовый датасет под свои задачи (минимум 50 кейсов)
- Выбрать минимум два отечественных облака и убедиться, что серверы в РФ
- Прогнать свои workflow через резервные модели
- (Опционально) Настроить локальный Ollama для критичных задач
- Документировать процедуру переключения
А вы уже думали о плане Б? Или пока живёте по принципу «авось пронесёт»? Интересно послушать, какие варианты рассматриваете – пишите в комментарии.