В машинном обучении мы давно привыкли к хаосу: случайная инициализация, разнообразные датасеты, шум в градиентах, разные архитектуры и режимы обучения. Логично ожидать, что модели, обученные в таких условиях, окажутся настолько разными, что объединить их можно будет разве что на уровне API — но не на уровне весов. Однако новое исследование от Johns Hopkins University демонстрирует противоположное: сотни нейросетей независимо приходят к одним и тем же “направлениям смысла” в пространстве параметров.
И это не метафора — это строгая спектральная картина, подтверждённая анализом более 1100 моделей: GPT-2, LLaMA-8B, Mistral-7B LoRA, Vision Transformers и даже классических CNN вроде ResNet-50.
Идея звучит почти философски:
нейросети, несмотря на все различия, живут в одном и том же низкоразмерном мире.
🌀 Как это работает: техническое погружение
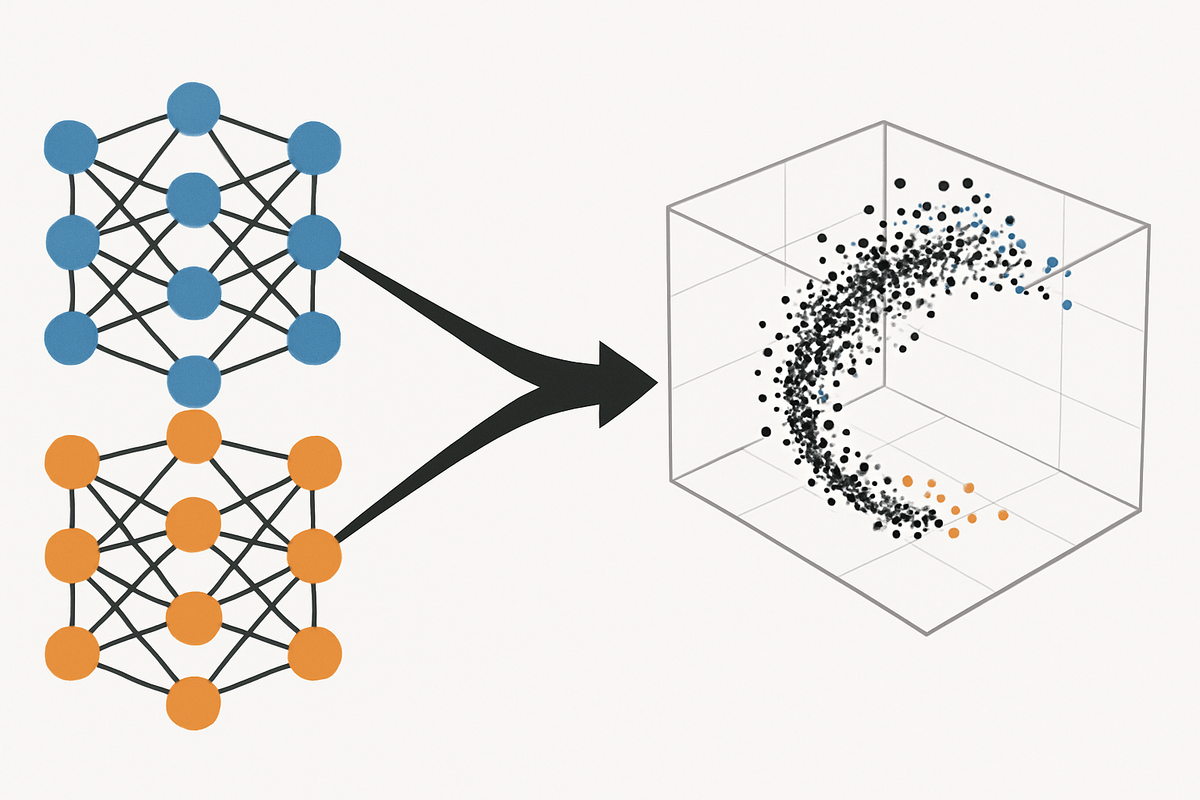
Обычно веса нейросети — это огромные матрицы, и мы думаем о них как о миллионах независимых параметров. Но если разложить их с помощью SVD или HOSVD, то обнаруживается резкое падение спектра:
🌄 всего несколько главных компонент объясняют большую часть вариации.
Исследователи сделали следующее:
🧩 Собрали tensor-стек весов
Каждая модель представляется как набор матриц весов (например, Attention Q/K/V, MLP проекции, LoRA-матрицы и т.д.).
🔍 Выполнили усечённое SVD / HOSVD
Для каждого слоя, через десятки и сотни моделей, вычислялись общие направления максимальной дисперсии.
🎯 Получили универсальное подпространство
Оказалось, что:
- для ViT — достаточно ~16 ортонормированных направлений;
- для LoRA-адаптеров Mistral-7B — также около 16;
- для LLaMA-8B — примерно так же;
- даже случайно инициализированные ViT, обученные на разных данных (!), сходятся в одно подпространство.
То есть, если бы веса были огромным облаком точек в N-мерности, то все модели лежат на одном и том же тонком «плато» — как если бы все художники рисовали по-разному, но всегда одними и теми же базовыми мазками.
🔧 Что это открывает на практике
Эта работа — не просто теоретический фейерверк. Она меняет правила игры.
✨ Возможности, которые даёт универсальное подпространство:
🗜️ Супер-компрессия моделей
Хранить можно не сами веса, а коэффициенты проекции в общее пространство.
В исследовании ViT-модели сжимались в 100 раз без потери качества для OOD задач.
🧪 Мгновенный перенос на новые задачи
Вместо fine-tuning → обучаем только коэффициенты подпространства.
Количество обучаемых параметров падает с 86M → 10k.
🔗 Корректное объединение моделей (model merging)
В отличие от TIES, DARE, RegMean —
здесь нет никаких эвристик:
модели геометрически совместимы по определению.
🎨 Улучшение стилевых LoRA для SDXL
Универсальное подпространство для 300+ LoRA стилей не только сохраняло стили, но и иногда повышало CLIP-оценку, вероятно за счёт подавления шумовых компонент.
💡 Можно заменить сотни моделей одной, где каждая индивидуальная модель — это просто набор чисел в общем базисе.
🧩 Но почему так происходит?
Моё видение — это естественное следствие:
- архитектурных симметрий (матрицы внимания имеют одинаковую типологию во всех задачах),
- ограничений оптимизации через backprop (градиентный спуск движется вдоль тех же «наиболее полезных» осей),
- универсальных статистических свойств реальных данных (плотность информации ниже, чем кажется),
- спектрального смещения в нейросетях (bias к низкочастотным решениям).
Иными словами, пространство всех возможных весов огромно, но пространство всех полезных решений — очень маленькое и компактное.
Это объясняет массу давно наблюдаемых феноменов:
🎯 почему разные инициализации сходятся в похожие решения
🔧 почему LoRA так хорошо работает почти на всех задачах
🧬 почему transfer learning настолько эффективен
🪢 почему между минимумами есть «связность минимумов»
🔥 почему 7B модели умудряются держать мощность, сравнимую с 70B
Мы медленно подбираемся к идее о том, что архитектура важнее данных, а обучение — это не поиск произвольного минимума, а «падение» в один общий спектральный каньон.
⚠️ Философский (и опасный) вопрос
Если все модели обучаются в один и тот же подпространственный шаблон, то:
❓ Получается, что у всех нейросетей примерно одинаковые:
- предпочтения
- ошибки
- слепые зоны
- культурные и информационные искажения
То есть универсальность может быть не только преимуществом, но и ограничением.
И, возможно, следующим шагом в ИИ станет не поиск лучшего оптимизатора, а создание архитектур, способных выходить из этого подпространства, нарушать «законы жанра» и осваивать новые спектральные регионы.
🔗 Источники
📄 Оригинальная научная статья:
https://arxiv.org/abs/2512.05117
🌐 Проект и визуализации:
https://toshi2k2.github.io/unisub/