Введение
Искусственный интеллект (ИИ) повсюду. Машинное обучение и глубокое обучение также часто упоминаются в разговоре о технологиях. А теперь генеративный ИИ, похоже, стал доминировать в большинстве разговоров о технологиях.
Для многих специалистов за пределами области ИИ эта терминология может быть запутанной. Эти термины часто используются взаимозаменяемо, иногда смешиваются и иногда представляются как конкурирующие технологии.
Если вы когда-либо задавались вопросами:
- Что на самом деле такое ИИ?
- Как связаны машинное обучение и глубокое обучение?
- Чем генеративный ИИ отличается от других?
Эта статья для вас.
Ключевая идея: матрёшка
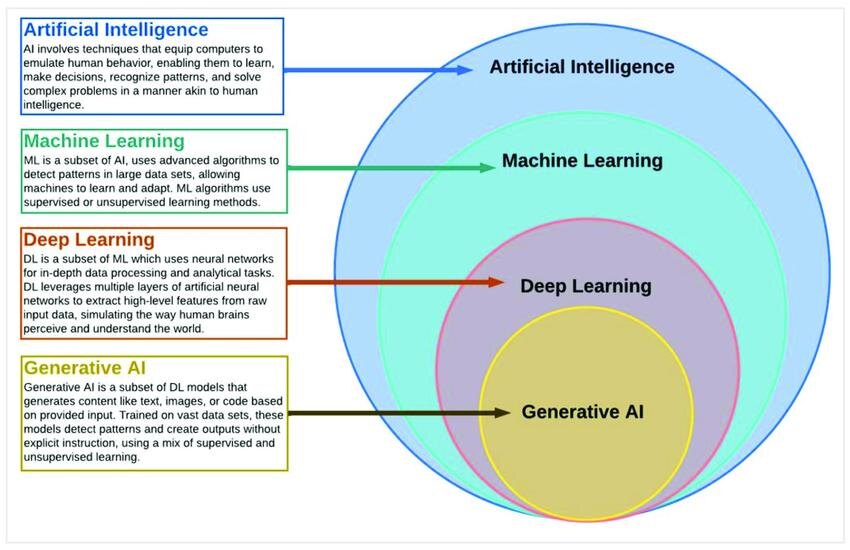
Полезный способ понять отношения между искусственным интеллектом, машинным обучением, глубоким обучением и генеративным ИИ — представить матрёшку. Каждый концепт содержит следующий внутри себя:
- Ничто не заменяет то, что было ранее,
- Каждый уровень строится на предыдущем.
Давайте откроем их поочередно.
Искусственный интеллект: внешняя оболочка
Искусственный интеллект (ИИ) представляет собой самое широкое определение. В своей основе ИИ относится к системам, созданным для выполнения задач, которые обычно требуют человеческого интеллекта. На практике ИИ включает системы, которые могут:
- Принимать решения. Пример: навигационная система выбирает самый быстрый маршрут на основании условий движения в реальном времени.
- Делать выводы. Пример: система принимает решение о том, одобрить или отклонить заявку на кредит на основании множества факторов.
- Распознавать шаблоны. Пример: выявление мошеннических транзакций с кредитными картами путем идентификации необычного поведения расходов.
- Предсказывать результаты. Пример: оценка будущего потребления энергии или спроса на продукт.
Правила основанного ИИ: интеллект, записанный людьми
В ранние десятилетия развития ИИ, особенно в 1970-х и 1980-х годах, системы в основном были основаны на правилах. Это означает, что люди четко писали логику. Компьютер не учился — он выполнял предопределенные инструкции.
Правило выглядело бы вот так: "Если дом имеет как минимум три спальни и расположен в хорошем районе, то его цена должна составлять около €500,000".
В терминах программирования логика схожая, но записана на коде: IF bedrooms ≥ 3 AND neighborhood = "good" THEN price ≈ 500000.
Это считалось искусственным интеллектом, потому что человеческое мышление было закодировано и выполнялось полностью машиной.
Почему правила ИИ ограничены
Системы, основанные на правилах, хорошо работали только в управляемых условиях. Реальные условия не контролируемые. Если взять наш пример с недвижимостью:
- рынки эволюционируют,
- контексты меняются,
- исключения множатся.
Система не может адаптироваться, пока человек не перепишет правила. Это ограничение привело к следующему слою.
Машинное обучение: данными на языке
Машинное обучение (МЛ) является подмножеством искусственного интеллекта. Ключевое изменение здесь простое, но глубокое:
Вместо того чтобы говорить компьютеру, какие правила нужно применять, мы позволяем системе изучить их напрямую из примеров.
Вернемся к примеру с ценой дома. Вместо написания правил мы собираем данные:
- площадь,
- количество комнат,
- местоположение,
- исторические цены на продажу.
Тысячи, иногда миллионы, прошлых примеров.
Эти данные предоставляются в качестве обучающих данных для модели машинного обучения.
Обучение модели: что это значит?
Обучение — это не черный ящик. Мы начинаем с выбора математической модели, которая могла бы описать связь между входами (площадь, местоположение и т. д.) и выходом (ценой). Мы не тестируем одно уравнение. Мы тестируем много (мы называем их моделями). Одним из очень упрощенных примеров могло бы быть: price = 2 × surface + 3 × location.
Как мы знаем, работает ли модель?
Перед принятием модели — то есть уравнения, которое наилучшим образом отображает изучаемый феномен — мы ее оцениваем. Часть данных намеренно скрыта. Это известно как тестовые данные. Модель:
- никогда не видит эти данные во время обучения,
- должна делать предсказания на них позже.
Предсказания затем сравниваются с реальностью.
Если производительность хороша на невидимых данных, модель полезна. Если нет, она отклоняется, и пробуется другая модель. Этот шаг оценки имеет важное значение.
Машинное обучение в действии
Машинное обучение превосходит в задачах, с которыми люди сталкиваются:
- Анализ больших объемов данных,
- Выявление тонких шаблонов,
- Обобщение на основе прошлых примеров.
Примеры применения:
- Здравоохранение → предсказание рисков заболеваний, анализ медицинских изображений.
- Промышленность → предсказание сбоев оборудования, оптимизация производственных процессов.
- Потребительские продукты → рекомендательные системы, выявление мошенничества.
Ограничения традиционного машинного обучения
Тем не менее, традиционное машинное обучение имеет важные ограничения. Оно хорошо работает со структурированными данными:
- таблицы,
- числовые значения,
- четко определенные переменные.
Однако оно сталкивается с трудностями при работе с типами данных, с которыми люди умеют работать естественным образом, такими как:
- изображения,
- аудио,
- текст.
Причина этого ограничения фундаментальна — "компьютеры понимают только числа".
Компьютеры не понимают изображения, звуки или слова так, как это делают люди.
При работе с изображениями, текстом или аудио эти данные должны сначала быть трансформированы в числовые представления.
Например, изображение преобразуется в матрицу чисел, где каждое значение соответствует информации о пикселях, такой как интенсивность цвета. Только после этой конверсии модель машинного обучения может обрабатывать данные.
Извлечение признаков: традиционный подход
Перед появлением глубокого обучения эта трансформация зависела в значительной степени от мануального извлечения признаков.
Инженеры должны были заранее определить, какие характеристики могут быть полезны:
- края или формы для изображений,
- ключевые слова или частоты слов для текста,
- спектральные компоненты для аудио.
Этот процесс, известный как извлечение признаков, был:
- времязатратным,
- ломким,
- сильно зависел от человеческой интуиции.
Небольшие изменения в данных часто требовали пересмотра признаков с нуля.
Почему нужно было глубокое обучение
Ограничения ручного извлечения признаков в сложных условиях стали ключевой мотивацией для разработки глубокого обучения. Глубокое обучение не устраняет необходимость в числовых данных. Скорее, оно изменяет способ получения признаков.
Вместо того чтобы полагаться на вручную созданные признаки, глубокие обучающие модели учат полезные представления непосредственно из сырьевых данных.
Это означает структурный сдвиг.
Глубокое обучение: структурный сдвиг
Глубокое обучение по-прежнему работает как машинное обучение. Процесс обучения остается тем же:
- данные,
- обучение,
- оценка.
Что меняется, так это архитектура модели. Глубокое обучение основывается на нейронных сетях с множеством слоев.
Слои как прогрессивные представления
Каждый слой в модели глубокого обучения применяет математическую трансформацию к своему входу и передает результат следующему слою.
Эти слои можно понимать как прогрессивные представления данных.
В случае распознавания изображений:
- ранние слои выявляют простые шаблоны, такие как края и контрасты,
- промежуточные слои комбинируют эти шаблоны в формы и текстуры,
- поздние слои захватывают концепции более высокого уровня, такие как лица, объекты или животные.
Модель не "видит" изображения так, как это делают люди. Она учится иерархии числовых представлений, которые делают возможным точные предсказания.
Вместо того чтобы получать от нас указания, какие признаки использовать, модель изучает их прямо из данных.
Эта способность автоматически изучать представления делает глубокое обучение эффективным для сложных, неструктурированных данных.
Переход от анализа к созданию: генеративный ИИ
Генеративный ИИ не заменяет глубокое обучение. Он строится прямо на его основе.
Тем же глубоким нейронным сетям, которые научились распознавать шаблоны, теперь ставится другая задача: генерация.
Вместо того чтобы сосредоточиться только на классификации или предсказаниях, генерирующие модели учат, как данные производятся, шаг за шагом.
В результате они могут создавать новый контент, который является логичным и реалистичным.
Конкретный пример
Рассмотрим запрос:
"Опишите роскошную квартиру в Париже."
Модель не извлекает существующее описание.
Вместо этого:
- она начинает с запроса,
- предсказывает самое вероятное следующее слово,
- затем следующее,
- и продолжает этот процесс последовательно.
Каждое предсказание зависит от:
- того, что уже было сгенерировано,
- оригинального запроса,
- шаблонов, изученных на больших объемах данных.
Итоговый текст новый — он никогда не существовал прежде — но он кажется естественным, потому что следует той же структуре, что и аналогичные тексты, увиденные во время обучения.
Почему генеративный ИИ отличается сегодня
Искусственный интеллект, машинное обучение и глубокое обучение существуют много лет.
То, что делает генеративный ИИ важной вехой, не только улучшение производительности, но и то, как люди взаимодействуют с ИИ.
Ранее работа с современным ИИ требовала:
- технических интерфейсов,
- знания программирования,
- инфраструктуры и управления моделями.
Сегодня взаимодействие происходит в основном через:
- естственный язык,
- простой инструкции,
- разговор.
Пользователи больше не должны конкретизировать, как что-то сделать. Они могут просто описать, что хотят.
Подведение итогов
Эти концепты не являются конкурирующими технологиями. Они образуют согласованное развитие:
- Искусственный интеллект определяет цель: интеллектуальные системы.
- Машинное обучение позволяет системам учиться на данных.
- Глубокое обучение позволяет обучаться на сложной, неструктурированной информации.
- Генеративный ИИ использует это понимание для создания нового контента.
С этой точки зрения, генеративный ИИ не является резким разрывом с прошлым. Это естественное продолжение всего, что было ранее.
Надеюсь, эта статья была полезной. Теперь вы больше не потеряны в технологических беседах.
==> Хотите узнать про автоматизации на n8n? — Здесь основные курсы n8n, вы научитесь автоматизировать бизнес-процессы! <==