Нормализация адреса — это обязательный этап предобработки исходных данных для прямого геокодирования, т.к. они могут содержать ошибки, опечатки и нестандартные сокращения. Перед поиском нужного объекта в эталонной базе, адресную строку нужно привести к каноническому виду. Это сложный, многоэтапный процесс, который включает в себя и лингвистический анализ, и работу с большими данными.
В этой статье мы постараемся рассмотреть процесс в общем виде, хотя предобработка данных, последовательность процессов, их количество для сервисов разных поставщиков может несколько отличаться.
Приведение адреса к понятному для сервиса виду
После того как пользователь ввел адрес, эту запись нужно очистить от лишних элементов. На этом этапе могут удаляться лишние пробелы, ошибочные символы, которых не должно быть в адресе (например, % или $).
Далее запускается процесс стандартизации адреса. Все сокращения расшифровываются, а синонимы заменяются на стандартные значения. Это может быть сделано с помощью справочника синонимов, который должен быть создан заранее. Так, «ул.» превращается в «улица», «г. Москва» — просто «Москва», «СПб» — «Санкт-Петербург» и т.д. В зависимости от алгоритма работы сервис может учитывать регистр букв (заглавные/строчные) или же пренебрегать им. Цель этого этапа— максимально привести адрес к тому виду, в котором он хранится в адресной базе, которая подключена к сервису, т.е. в эталонной базе.
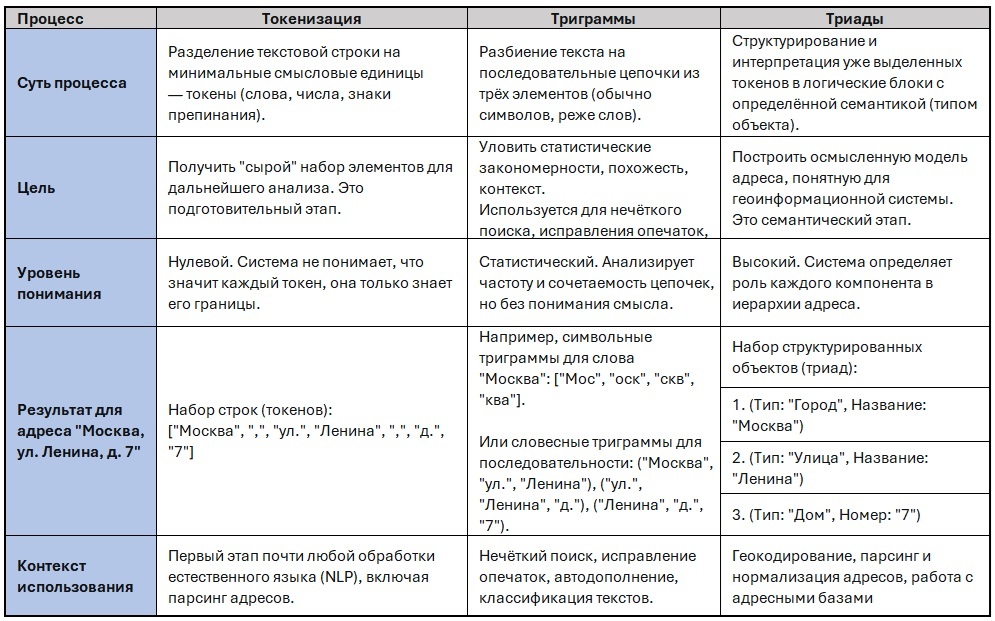
Токенизация
Затем происходит разделение адреса на блоки. Для удобства будем рассматривать конкретный адрес, например, «Москва, ул. Донская, д. 5 ». На этом этапе сервис будет анализировать наличие пробелов, запятых, ключевых слов, дефисов и т.п. Такое разбиение адреса на отдельные осмысленные единицы ("Москва", ",", "ул.", "Донская", ",", "д.", "5") называется токенизацией.
Триады
После токенизации может быть осуществлено разделение адреса на триады. В этом случае каждый компонент адреса будет описываться тройкой атрибутов (полей). В зависимости от конкретного алгоритма и от уровня объекта триадам может назначаться разный вес. Так, в алгоритмах ранжирования совпадение на уровне региона (первые триады) может иметь больший вес, чем совпадение на уровне улицы (последние триады), так как ошибка в регионе сделает нерелевантным всё, что находится ниже.
Триграммы
Если пользователь введет адрес с опечаткой, например "Данская", то сервис не найдет ее в базе, потому что токенизация даст всего один токен: "Данская". Сравнив его с "Донская", сервис увидит, что слова не совпадают. Такой подход может использоваться интерактивном поиске, когда поиск происходит во время набора адреса (по буквам, "на лету") – т.е. в режиме подсказок, когда пользователь сам может выбрать подходящий адрес из предложенных.
Но если поиск должен быть произведен после нажатия на кнопку «Найти», то нужно обработать опечатки. Для этого требуется разбиение на более мелкие блоки. Этот прием позволяет сравнивать не целые слова, а их части, триграммы ы (т.е. каждый блок состоит из трех символов).
Для примера с опечаткой ситуация будет выглядеть следующим образом:
- Данская -> ["Дан", "анс", "нск", "ска", "кая"]
- Донская -> ["Дон", "онс", "нск", "ска", "кая"]
Сервис определит, что у наборов есть много совпадений (нск, ска, кая). Это высокая степень схожести, поэтому сервис предложит исправленный вариант названия.
Построение адресной иерархии
Теперь сервис должен понять, что есть что в этом разобранном адресе и по заранее заданным правилам определяет роль каждого адресного элемента в общей адресной структуре.
На этом этапе выстраивается адрес в соответствии с иерархической моделью. В данном случае получается:
- Страна: (Россия, подразумевается)
- Регион: (Москва, город федерального значения)
- Город/Населенный пункт: Москва
- Улица: Донская
- Дом: 5
Сервис понимает, что «Москва» — это крупный административный объект, в котором нужно искать «улицу Донскую», и уже на этой улице — «дом 5».
Поиск в адресной базе
У каждого картографического сервиса есть своя адресная база данных (эталонная адресная базу). Процесс поиска часто происходит по каскадному принципу:
- Сначала находится объект «Москва» (или более крупная административная единица, если пользователь это указал).
- Внутри Москвы ищется улица с названием «Донская».
- Для найденной улицы определяется ее уникальный идентификатор.
- Затем, с учетом этого идентификатора, ищется здание с номером «5».
Откуда же берутся координаты?
Для того чтобы сервис мог получить координаты объекта, этот объект должен быть в картографической базе данных. Состав, наполнение и структура баз данных у разных поставщиков с одной стороны отличаются, с другой - имеют много общего. Сервис прямого геокодирования RuMap работает на основе базы данных RuMap, в которой каждый объект привязан к административному делению и совместим с прочими сервисами компании.
Координаты адресной точки (широта и долгота) могут браться из геометрии объекта в базе картографических данных. А вот для объектов других слоев: полигональных (в которых могут храниться границы регионов или областей) и линейных (например, слоя с улицами) для геокодера потребуются координаты центра (или середины) объекта, поэтому они должны быть предварительно вычислены и «уложены» в базу данных сервиса в виде специальных таблиц с координатами.
Далее нужно связать нормализованный ранее адрес и координаты из этой специальной таблицы. Это можно сделать разными способами, одним из которых является связыванием по идентификатору.
Формирование ответа
Когда все элементы адреса найдены и сопоставлены с координатами, сервис формирует ответ. Обычно это структурированный JSON-объект.
Как правило в ответ, обязательно выводится:
- найденный адрес;
- координаты;
- тип объекта;
- оценка релевантности – т.е. числовой показатель, который показывает, насколько сервис уверен в результате.
Для примера можно ознакомиться с результатом геокодирования RuMap-сервиса, который доступен пользователю в виде таблицы.

Подробнее о вариантах формирования результата (в простом виде, в структурированной форме, с указанием кодов ОКТМО, ОКСМ или ФИАС) и режимах работы сервиса прямого геокодирования RuMap можно прочитать на странице с его описанием. А прогеокодировать свои объекты можно на отдельной странице геокодера: загрузите таблицу из 50 адресов и получите результат в формате geojson, в виде таблицы и на карте.