
Настраиваем алерты для отслеживания упоминаний вашего бренда | Автор: Марина Погодина
Когда я впервые услышала запрос «n8n мониторинг упоминаний по-быстрому и без геморроя», я уже догадывалась, чем всё кончится: серверы за пределами РФ, какие-то рандомные боты из непонятных панелей и полное игнорирование 152-ФЗ. Поэтому в этом тексте я разложу по полочкам, как выглядит рабочая настройка алертов в n8n в России, когда тебе одновременно нужно и мониторить, и спать спокойно. Мы пройдемся по тому, как шаг за шагом собрать процесс, где n8n настройка не сводится к «лишь бы работало», а учитывает локализацию данных, понятные журналы обработки и нормальную фильтрацию, чтобы тебя не заваливало спамом. Статья подойдёт тем, кто уже автоматизирует задачи через n8n или Make, присматривается к ИИ-агентам, а теперь хочет, чтобы репутационный мониторинг бренда, личного имени или проекта жил в одном сценарии и не конфликтовал с российскими реалиями. И да, здесь будет живой разбор, а не магия «одной кнопкой».
Время чтения: примерно 15 минут
- Зачем вообще настраивать n8n для мониторинга упоминаний в России
- Как спланировать мониторинг и не нарушить 152-ФЗ
- Какие инструменты и интеграции выбрать для n8n мониторинга
- Как настроить алерты в n8n для мониторинга упоминаний за 5 шагов
- Какие результаты можно получить и как ими управлять
- Какие подводные камни чаще всего ломают автоматизацию
- Практические формулы, которые экономят часы
- Что ещё полезно помнить про такой мониторинг
Зачем вообще настраивать n8n для мониторинга упоминаний в России
Иногда кажется, что мониторинг упоминаний — это история про большие бренды и отделы PR, но в российской реальности все куда прозаичнее: сегодня ты просто ведешь Telegram-канал и собираешь отзывы в VK, а завтра Роскомнадзор интересуется, где хранятся персональные данные пользователей, которые мелькнули в этих самых отзывах. Я заметила, что большинство ко мне приходят с одинаковой точкой старта: «мы что-то подключили, вроде летит, но не уверены, что по 152-ФЗ это хотя бы наполовину адекватно». И вот здесь n8n оказывается удобным компромиссом — он даёт гибкость, которая позволяет собрать аккуратный процесс обработки, журналировать действия и при этом не уходить в бесконечные кастомные разработки. При этом сам n8n — всего лишь движок, а вся ответственность за локализацию, выбор источников и настройки фильтрации всё равно на нас с тобой, как на людях, которые это запускают.
Если смотреть с позиции закона, любой мониторинг, где ты собираешь и сохраняешь упоминания, где есть имя, ник, ссылка на профиль или даже комбинация контекста, уже превращается в обработку персональных данных. Это критично, потому что в России с 2025 года усилили фокус не только на больших IT-компаниях, но и на вполне себе средних бизнесах, которые используют готовые SaaS-сервисы для анализа репутации. Получается, что классический бренд-мониторинг через зарубежные платформы часто не вписывается в требования локализации и защиту ПДн, если данные сразу улетают на чужие сервера. А вот собственный сценарий на n8n, развернутый на российском хостинге, да ещё и с понятными правилами фильтрации и хранения логов, помогает остаться в белой зоне и не бегать в панике при слове «проверка».
Чтобы показать, что речь не про абстракции, я собрала отдельный визуальный пример типового процесса, когда n8n настройка агента мониторит упоминания, фильтрует лишнее и отправляет алерты только по важным срабатываниям. На таком скелете уже можно потом наращивать ИИ-часть, дополнительные ветки, интеграцию с CRM и всё остальное. Ниже как раз схематично видно, как это выглядит, когда узлов шесть, а не шестьдесят.
Когда начинаю проект по автоматизации, первый разговор почти всегда не про «какие источники подключим», а про то, как компания сейчас хранит данные, есть ли отдельный текст согласия, где лежат логи и кто к ним имеет доступ. Это означает, что n8n мониторинг в России нельзя рассматривать отдельно от управленческой кухни компании: если внутри хаос, никакой идеально собранный workflow ситуацию не спасет. Зато когда есть хотя бы минимальный порядок — осознанные цели мониторинга, понятные роли и примерно описанный процесс обработки ПДн — мы можем собрать цепочку в n8n так, чтобы она не жила отдельной жизнью, а подстраивалась под существующую политику безопасности. В итоге выходит не только автоматизация ради скорости, а система, которая просто снижает количество ручных ошибок и разговоров в стиле «ой, этот лог утерян, этот файл забрали в личный Telegram, а кто-то базу на флешке унес».
Я поняла, что хороший мониторинг упоминаний через n8n — это не про красоту дашбордов и даже не про количество источников, а про три тихих критерия: законность, прозрачность и предсказуемость. Если любой сотрудник, который прикоснётся к этим данным, может открыть понятную схему, посмотреть журнал и быстро ответить, что и куда уходит — система работает. Если же всё держится на одном «священном администраторе», который единственный знает, где там спрятан фильтр или токен, значит это кандидат на выгорание и возможные штрафы. Поэтому мне ближе подход, когда мы изначально проектируем сценарий как часть архитектуры, а не как личный эксперимент одного энтузиаста.
Получается, что первый шаг к настройке алертов в n8n для мониторинга упоминаний — вообще честно признать, что это уже не игрушка для технаря, а нормальный бизнес-процесс с юридическими последствиями. Как только эта мысль садится в голову, многие решения по выбору хостинга, сервисов и логики внутри сценария принимаются проще и спокойнее, без попыток «обхитрить» закон или «потом как-нибудь оформить согласия». Ну и да, дальше будет уже совсем практическая часть — где мы поговорим, как именно спланировать объём данных и не собрать всего лишнего.
Как меняется контекст мониторинга в РФ после усиления контроля
Я все чаще вижу одну и ту же картинку: компания уже пробовала один-два зарубежных сервиса для мониторинга, устала от ограничений бесплатных тарифов, посчитала стоимость платных, и в какой-то момент параллельно прилетает напоминание от юристов, что локализация данных — это не пожелание, а обязанность. И тут n8n вдруг оказывается вполне рабочим отвечиком: можно поднять его в российском облаке, подключить нужные источники (от VK и Telegram до локальных форумов) и хранить всё в том периметре, который контролирует сама организация. На практике это помогает совместить две реальности: потребность маркетинга или PR в актуальных данных и потребность службы безопасности в том, чтобы Роскомнадзор не задавал лишних вопросов. Да, на старте такой подход требует чуть больше энергии, чем «подключили сервис за 10 минут и забыли», но через месяц-два благодарность к себе прошлой становится очень осязаемой.
Чтобы добавить немного структурности, я иногда сравниваю готовые западные платформы и n8n как конструктор. Первые дают «всё включено», но по своим правилам и на своих серверах, второе требует настроек, но зато позволяет собрать ровно тот уровень прозрачности, который нужен для российских проверок. В одном из разборов я как раз сводила эти различия в сравнительную схему, и многим стало проще принять решение, когда наглядно видно, где у кого сильные и слабые стороны. Ниже как раз тот самый случай, когда картинка лучше тысячи слов по теме «агрегатор vs собственный сценарий».
Когда я первый раз столкнулась с такими проектами в российском контексте, меня удивило не то, сколько данных компании собирают, а то, как мало они думают про то, что будет через полгода. Файлы с выгрузками лежат в личных облаках, сотрудники меняются, документы по согласиям обновляются, а сценарии и интеграции остаются в старой логике, как брошенные кораблики. Это означает, что через какое-то время даже формально законный стартовый процесс превращается в «серую зону», где никто уже точно не знает, всё ли ок. Если же изначально привязать n8n к понятной архитектуре — отдельное хранилище логов, регламент доступа, регулярный аудит — то поддерживать такое решение становится не сложнее, чем включить свет и проверить, не перегорела ли лампочка. В этом есть приятный бытовой плюс: автоматизация перестает быть чем-то хрупким, чего все боятся коснуться.
В повседневной жизни это выглядит забавно просто: утром ты наливаешь себе кофе, открываешь папку с логами и видишь не хаотичные файлы «новое_новое_итоговое2», а аккуратные записи с понятными временными метками, источниками и результатами фильтрации. n8n в этом плане даёт возможность не только дергать API и шлеть уведомления в Telegram, но и строить дисциплину обработки данных без тяжеловесных корпоративных систем. Мне нравится думать про это как про аккуратный минимализм: никаких лишних панелей, только ясные процессы и честные метрики. Скорее всего, именно за этим большинство и приходит — за возможностью вернуть себе время, не закапываясь в рутину поиска и ручной сортировки упоминаний каждый день.
Как спланировать мониторинг и не нарушить 152-ФЗ
Перед тем как кидаться в н8n настройка интеграций, я почти всегда задаю один и тот же скучный, но полезный вопрос: что именно вы хотите мониторить и зачем. На бумаге он выглядит банальным, но именно здесь чаще всего всё и спотыкается, потому что «всё подряд» — не цель, а гарантированный путь к перегрузу и потенциальным проблемам с ПДн. При грамотном подходе мы сначала выписываем сущности: бренд, отдельные продукты, имена спикеров, возможно, географические метки или хештеги, а потом аккуратно проверяем, в каких комбинациях появляются персональные данные. Это критично, потому что объём и детализация мониторинга напрямую влияют на то, какие согласия нужны, как мы будем обезличивать данные и какие данные вообще нельзя тянуть в систему, даже если технически очень хочется. Обычно на этом этапе исчезает иллюзия, что достаточно просто «подключить Telegram-бота и парсер», а на их место приходит понимание, что мы проектируем полноценный процесс.
Я заметила, что проще всего начинать с карты целей: отдельно репутационный мониторинг бренда, отдельно мониторинг конкретных лиц (например, собственника или публичных экспертов), отдельно отслеживание пользовательских историй, где люди сами оставляют отзывы и согласие уже встроено в форму. Это помогает разделить потоки данных и не мешать в одной базе то, что можно хранить в просто агрегированном виде, и то, что требует личного согласия. Для России это не теоретическая роскошь, а вполне прагматичная штука: когда приходит проверка или внутренний аудит, гораздо легче показать, что вы заранее разделили обработки и используете понятные правовые основания. В n8n это потом выражается в разветвленной логике маршрутизации: одни данные идут в обезличенную аналитику, другие — в карточку клиента, третьи — только в алерт без сохранения исходного текста.
Чтобы это не звучало слишком академично, я собрала простой образ: представь себе, что у тебя есть три коробки — «общественные упоминания», «отзывы по согласию» и «чувствительные данные». n8n в этом случае выступает курьером, который должен разложить каждую новую запись в нужную коробку, причём без права покидать границы склада в России. Ниже на инфографике это показано чуть более системно — как потоки двигаются от источников к хранилищам и алертам, когда мониторинг строится с нуля под наши реалии, а не через адаптацию чужой западной схемы.
На практике после определения целей мы переходим к описанию правовых оснований: где у нас есть отдельное согласие, а где мы работаем с обезличиванием или ограниченным хранением. Здесь работает простая логика: чем более точные и «человекоузнаваемые» данные ты хочешь сохранить, тем сильнее должна быть юридическая опора. Если речь про общую аналитику упоминаний бренда без привязки к конкретным личностям, достаточно агрегации с минимизацией ПДн. Если же ты строишь сценарий, где для каждого пользователя создается карточка с историей отзывов, то без отдельного понятного согласия после 1 сентября 2025 года уже никуда. Это означает, что в n8n полезно заранее закладывать шаги, которые проверяют, есть ли нужное согласие в базе, и только после этого двигают данные дальше по воронке обработки.
Чтобы не запутаться, я часто использую простую подсказку, которая укладывается в голове не только у юристов, но и у маркетологов: обработка в мониторинге допустима, если у нас одновременно есть конкретная цель, понятный вид данных, способ их защиты и ответственный за процесс. Без ответственного мониторинг неминуемо превращается в «ничейный сундук с данными», а именно это и любят проверяющие органы. Ответственный не обязан руками ковыряться в n8n, но он должен понимать, как устроен сценарий и какие риски несет каждая его ветка. В небольших командах эту роль часто совмещают с ИТ- или операционным руководителем, и это нормально, пока объем данных не разросся до гигантских масштабов.
В какой-то момент к этому разговору всё равно подключается история про хранение и срок жизни данных. Я поняла, что удобнее всего давать себе честный ответ: сколько реально нам нужно хранить каждое упоминание, чтобы оно приносило пользу, а не валялось мертвым грузом. Часто реальность такая: оперативные алерты полезны в течение недели-двух, агрегированная статистика — несколько месяцев, а всё остальное можно либо обезличивать, либо архивировать с ограниченным доступом. Для n8n это означает, что в сценарий логично добавить блоки, которые через определённый период либо обрезают лишнее, либо отправляют данные в более холодное хранилище. В итоге мониторинг перестает быть «черной дырой», в которую всё падает и никогда не удаляется, а превращается в аккуратный поток, где у каждого кусочка информации есть жизненный цикл.
Как описать цели и объём данных так, чтобы потом не переделывать
Когда я сажусь с командой и мы начинаем описывать цели мониторинга, нас неизбежно тянет в сторону всех возможных сценариев: а давайте ещё собирать упоминания конкурентов, а ещё общий фон по рынку, а ещё все вопросы клиентов по теме. Здесь работает простой приём: сначала мы фиксируем минимальный набор задач, которые точно принесут пользу в ближайшие три месяца, и только под них формируем первый сценарий в n8n. Я замечала, что если сразу пытаться охватить всё, в итоге не запускается ничего, или запускается, но через месяц от объёма шума все просто выключают алерты. Именно поэтому я за поэтапный рост: сначала бренд и ключевые спикеры, потом топовые площадки, потом уже более экзотические источники и продвинутый разбор тональности.
Чтобы командам было проще формализовать свои хотелки, я предлагаю разложить всё по трём уровням: must have, nice to have и «на будущее, когда будет ресурс». В must have попадают источники и метрики, без которых мониторинг не считается полезным: например, упоминания в Telegram и VK, отзывы на крупнейших площадках и ключевые тематические каналы. В nice to have идут менее частотные, но потенциально ценные источники, которые можно добавить после стабилизации процесса. А вот всё, что относится к глубоким ИИ-анализам, продвинутой кластеризации и многомерным дашбордам, честно уезжает в «на будущее». Это снижает риск того, что ты прямо сейчас зашьёшь в n8n сложную логику, которой никто не будет пользоваться из-за нехватки людей или времени. Лучше рабочий минимализм, чем нереализованный идеал из презентации.
Следующий шаг — зафиксировать, какие поля в каждом типе записи нам реально нужны. Здесь я немного занудная и прошу команды подписать список: источник, дата, текст упоминания, ссылка, контекстные теги, «флаг» тональности, а далее уже по вкусу. Чем точнее на этом этапе мы ограничим набор полей, тем меньше соблазна будет тянуть в систему лишние персональные данные просто «на всякий случай». В n8n это потом отражается в виде понятных схем маппинга: какие поля приходят из источника, какие мы храним, какие сразу выбрасываем или обезличиваем. По опыту, чем проще схема в голове, тем меньше шанс, что её потом сломают невинные изменения какого-нибудь нового интегратора.
Когда базовая структура целей и данных готова, н8n настройка сценария становится уже не творческой импровизацией, а реализацией конкретного проекта. На этом этапе я всегда советую всё еще раз прогнать через фильтр 152-ФЗ: локализация, согласия, защита, доступы. Если хотя бы по одному пункту появляются сомнения, лучше их закрыть сейчас, чем через год объяснять проверяющему, почему часть данных оказалась на иностранном сервере или в открытой таблице без контроля доступа. В итоге спланированный таким способом мониторинг становится не только инструментом для маркетинга и репутации, но и аргументом «в плюс» для службы безопасности и внутренних аудиторов, которым приятно видеть, что о рисках подумали заранее.
Какие инструменты и интеграции выбрать для n8n мониторинга
После того как мы разобрались с целями и объёмом данных, начинается самое интересное для технарей — выбор источников и интеграций под российскую реальность. Я заметила, что первый рефлекс у многих — потянуть в n8n всё подряд через любые доступные API, парсеры и ботов, а потом уже как-нибудь разгрести. К сожалению, такая стратегия в России быстро упирается в две стены: юридическую (где данные физически обрабатываются и кто их видит) и техническую (насколько стабильно работают неофициальные интеграции). Поэтому я начинаю с инвентаризации: какие площадки точно нужно подключить, есть ли у них официальное API, какие существуют российские или сертифицированные прокси-сервисы, и что из этого реально удержать в белой зоне по 152-ФЗ. Иногда на этом этапе планы заметно трезвеют, но это полезная честность.
На практике для мониторинга в России чаще всего фигурируют VK, Telegram, Яндекс.Кью, Дзен, разные форумы и локальные площадки с отзывами. Часть из них имеет нормальное API, часть — нет, а кое-где приходится идти обходными путями через RSS, email-уведомления или интеграцию с внутренними формами. В n8n есть базовые коннекторы, но нередко приходится подключать собственного бота или сторонний сервис, который будет по-честному развернут на сервере в РФ. Здесь работает простое правило: если сервис непонятно где хостится, сложно получить информацию о локализации данных или любом упоминании ПДн, лучше изначально искать другой вариант. n8n в этой истории всего лишь помогает связать кусочки, но качество каждого из них всё равно определяет результат.
Чтобы не утонуть в вариантах, я обычно делю интеграции на три слоёв: прямые источники (те самые соцсети и площадки), промежуточные сервисы (боты, коннекторы, парсеры) и хранилище/аналитику (БД, дашборды, отчёты). Важный нюанс: на каждом слое мы проверяем, где лежат данные и кто имеет к ним доступ. В результате получается архитектурная схема, по которой можно пройтись пальцем и на каждый элемент ответить: «да, это сервер в РФ, да, вот договор обработки, да, вот уровень защиты». Чтобы не быть голословной, я часто показываю такую схему командам в наглядном виде — как всё связано и куда какие потоки идут. Одну из таких схем я вынесла в отдельное изображение, потому что она неплохо передает дух «ничего лишнего, только рабочие элементы».
Когда я первый раз столкнулась с задачей подружить n8n и Telegram по белым правилам, честно надеялась, что всё решится за вечер. На деле все заняло несколько итераций: поднять бота на российском сервере, аккуратно настроить вебхуки, продумать, какие данные бот вообще видит и что он пересылает в n8n. Это отличный пример того, как телегам n8n настройки превращаются из «там токен, тут URL» в полноценный мини-проект по безопасности. Здесь хорошо помогает привычка всё документировать: какие токены используются, где хранятся, кто отвечает за их ротацию, какие логи ведутся на стороне бота и n8n. В итоге если что-то ломается (а что-нибудь рано или поздно ломается почти всегда), восстановить картину не так сложно, как когда всё держится на памяти одного разработчика.
На стороне n8n нам нужно не только принимать события от источников, но и грамотно отправлять алерты туда, где их точно увидят, не превратившись в фоновый шум. Чаще всего это Telegram, корпоративные мессенджеры или почта, иногда — внутренняя панель. Я поняла, что идеальный алерт — это тот, на который можно ответить действием в течение одной минуты: посмотреть, откуда пришло упоминание, понять, критично ли оно, и при необходимости передать дальше. Поэтому настройка n8n tool часто включает не только базовые ноды получения и отправки, но и ноды по формированию «человеческого» текста уведомления, чтобы людям не приходилось разбираться в сыром JSON каждое утро. Это вроде мелочь, но именно она отделяет удобную автоматизацию от раздражающего бота, которого первым делом ставят на mute.
Как выбрать инфраструктуру и не выстрелить себе в ногу
Когда заходит речь про сервера, у многих включается легкая прокрастинация: «давайте пока поднимем на том, что есть, а потом уже перенесем в РФ, если понадобится». Я очень мягко, но настойчиво предлагаю не играть в эту игру именно с мониторингом упоминаний, где гарантированно будут ПДн. Для n8n есть несколько адекватных вариантов: аренда виртуального сервера в российском дата-центре, использование сертифицированных облаков или собственные мощности компании, если они есть. Я за то, чтобы сразу выбрать инфраструктуру, которая выдержит рост нагрузки и при этом не вызовет вопросов у юристов. Да, это чуть дольше на старте, но зато не придется потом перекраивать всё ради локализации. Кофе остынет, зато сценарий потом не придется переносить в пожарном режиме.
Еще один вопрос, который часто всплывает: где хранить сами данные мониторинга. Тут спектр широкий — от PostgreSQL и ClickHouse до простых файловых хранилищ и интеграций с существующими системами. Критерии довольно приземленные: устойчивость, резервное копирование, контроль доступа, понятные логи. Я заметила, что небольшой команде не всегда нужен сложный data-стек, иногда достаточно аккуратной БД плюс отчеты, которые n8n собирает раз в сутки и отправляет ответственным. Для более продвинутых историй, где участвуют ИИ-модели, dwh и сложная аналитика, инфраструктура, конечно, будет масштабнее, но это уже отдельный этап зрелости. Главное на старте — не складывать данные «как придется», а относиться к выбору хранилища так же внимательно, как к выбору банка для расчётного счета.
Я поняла, что лучший фильтр для инфраструктурных решений звучит так: «если я завтра уйду в отпуск, сможет ли кто-то без паники разобраться в этой схеме». Если ответ «нет», значит, она слишком сложна или недостаточно документирована. Для n8n это особенно больно, потому что визуально workflow всегда кажется простым: ноды связаны, стрелочки есть, что могло пойти не так. На деле половина магии прячется в настройках, environment-переменных, внешних сервисах и политике доступа. Поэтому при выборе инструментов и интеграций я за комбо: простота структуры плюс подробная документация. Тогда даже через год можно будет открыть схему и без долгих ритуалов понять, как именно работает мониторинг и где искать возможный сбой.
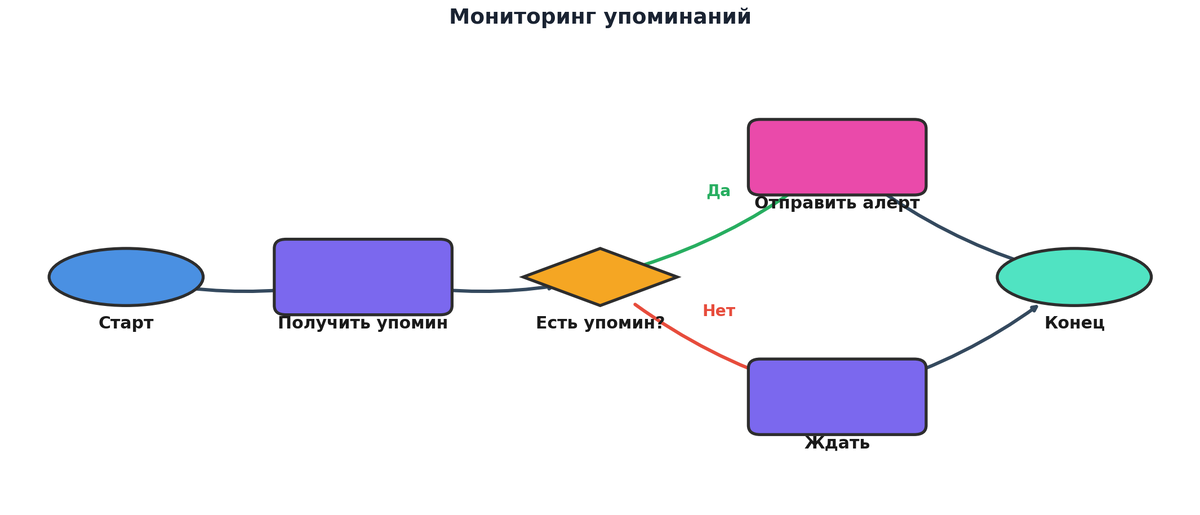
Как настроить алерты в n8n для мониторинга упоминаний за 5 шагов
Когда мы дошли до самого приятного — настройки конкретного сценария, — становится заметно, кто что недодумал на предыдущих этапах. Если цели расплывчаты, источники не ясны, а инфраструктура собрана на «авось», то шаги превращаются в бесконечную серию правок. Если же предварительная работа проделана, тогда n8n настройка выглядит как спокойное выкладывание заранее продуманного пазла. В упрощенном виде процесс настройки алертов в n8n для мониторинга упоминаний укладывается в пять шагов: 1) задать триггеры по источникам, 2) нормализовать входящие данные, 3) отфильтровать шум и лишние ПДн, 4) сформировать алерты и маршруты, 5) сохранить и журналировать всё, что произошло по пути. Теперь давай по-честному разберем, как это выглядит «на земле», а не в идеальной методичке.
Сначала мы создаем триггеры для каждого источника: вебхуки, периодические запросы к API, проверки RSS-лент или разбор входящих писем. На этом шаге наша задача — максимально стандартизировать формат входящих данных, чтобы дальше сценарий не разрастался в чудовище из сотни веток. Обычно я завожу отдельный нод-нормализатор, который приводит всё к общим полям: текст, источник, ссылка, время, автор, дополнительные теги. Это позволяет дальше писать единую логику обработки, а не сотню подправленных условий для каждого канала. Да, иногда ради этого приходится чуть дольше посидеть над маппингом полей, но потом это окупается экономией времени на каждом новом источнике.
Следующий шаг — фильтрация. Здесь мы разруливаем сразу две задачи: отсечь банальный спам и технический шум, а также не притянуть в обработку больше ПДн, чем нужно. Я заметила, что многие начинают с грубой фильтрации по ключевым словам, а потом удивляются, почему тональность упоминаний считается криво. Гораздо разумнее строить фильтры по нескольким уровням: ключевые слова, характеристики источника, наличие или отсутствие определенных полей, возможно, простая ML-модель для определения релевантности, если есть ресурс. Здесь же мы можем вшить микро-правила по защите ПДн: например, если упоминание содержит слишком много идентификаторов конкретного человека и при этом у нас нет согласия, то мы либо не сохраняем полный текст, либо сразу его обезличиваем, оставляя только агрегированные сигналы.
Чтобы не расписывать это слишком сухо, я привожу визуализацию базового workflow, где видно, как шаги триггера, нормализации, фильтрации и алертов ложатся в единый контур. Это не единственно возможный вариант, но хорошая точка ориентира для тех, кто только начинает собирать свой первый сценарий мониторинга в n8n и хочет опереться на что-то более осмысленное, чем хаотичные эксперименты в интерфейсе.
После фильтрации мы подходим к сердцу всей истории — формированию алертов. Здесь многое зависит от внутренних процессов: кому и как должны приходить уведомления, какие поля нужны в быстром просмотре, что считается «критичным» событием, а что — просто фоном для аналитики. Я поняла, что лучший формат алерта — это небольшой, но содержательный пакет информации: источник, короткий текст, ссылка, флаг тональности или важности и предлагаемое действие («ответить», «эскалировать», «внести в отчёт»). В n8n это реализуется через ноды форматирования текста, иногда — с использованием шаблонов, если уведомления уходят в несколько каналов. Пара лишних минут на этой стадии потом экономят десятки часов на разборе «а что автор вообще хотел сказать этим сообщением от бота».
Финальный шаг — журналирование и аудит. Я заметила, что многие игнорируют его на старте, а потом возвращаются, когда нужно восстановить ход событий или показать следы обработки данных для проверки. Самый простой подход — сохранять в отдельную таблицу или лог-хранилище метаданные обо всех срабатываниях: когда пришло упоминание, какие ноды сработали, какие фильтры прошли, какие алерты отправлены. При этом не обязательно сохранять полный текст, особенно если речь про чувствительные данные. n8n позволяет довольно гибко настраивать уровни логирования, и этим можно пользоваться, чтобы не хранить больше, чем нужно. В итоге у нас получается аккуратная цепочка: входные события — фильтрация — алерты — записи в журнал, и всё это живёт внутри одной прозрачной архитектуры, не расползаясь по непонятным Excel и скриншотам в личных чатах.
Как выглядят 5 шагов настройки алертов в живом рабочем процессе
Мне проще всего описывать такие вещи через конкретную ситуацию. Представь, что у тебя небольшой сетевой проект — например, онлайн-школа или кафе с сильным присутствием в соцсетях, — и ты хочешь, чтобы критичные отзывы и упоминания приходили в рабочий Telegram-чат. Мы поднимаем n8n на российском сервере, подключаем бота, настраиваем интеграции с VK, Telegram и формами обратной связи на сайте. Далее создаём workflow, который раз в несколько минут опрашивает источники или принимает вебхуки, приводит данные к единому формату, фильтрует упоминания по названию бренда и ключевым словам и отправляет алерт, если условие совпало. При этом в логи попадает только минимально необходимый набор полей, а подробный текст хранится столько, сколько мы заранее определили в политике.
Чтобы удобнее было использовать этот подход многократно, я часто описываю его в виде простой последовательности действий. Она помогает и разработчикам, и владельцам процессов, которые не собираются глубоко погружаться в внутренности n8n, но хотят понимать, за счёт чего всё работает. Я свожу это в небольшую карту-шаги, где за каждым пунктом стоит конкретное действие в интерфейсе n8n и краткая проверка на соответствие 152-ФЗ. Такое «дерево решений» удобно и как чек-лист, и как основа для внутренней документации.
- Определить источники и создать триггеры в n8n с учётом формата данных.
- Настроить ноды нормализации, приведя разные входные потоки к общим полям.
- Добавить многоуровневую фильтрацию: ключевые слова, тип источника, ограничения по ПДн.
- Сконструировать формат алерта и маршруты доставки уведомлений для разных ролей.
- Включить журналирование: сохранить метаданные, предусмотреть ротацию и защиту логов.
По мере того как такой сценарий обкатывается в боевом режиме, заведомо появляются доработки: нужно изменить частоту опроса, добавить новые ключевые слова, прикрутить ИИ-оценку тональности, сделать отдельные алерты для разных команд. Здесь красота n8n в том, что изменения можно вносить итеративно, не разрушая базовую архитектуру. Сначала мы делаем простую, но устойчивую основу, а затем, если есть желание и ресурс, наращиваем вокруг неё более умные механизмы, сохраняя при этом белый контур по законодательству. И в какой-то момент ты ловишь себя на мысли, что уже неделя прошла без ручного мониторинга поисковой выдачи, а количество пропущенных негативных отзывов резко снизилось.
Какие результаты можно получить и как ими управлять
После запуска сценария мониторинга с алертами на n8n наступает любопытный момент: технически всё уже работает, уведомления приходят, но жизнь команды только начинается. Я заметила, что именно на этом этапе особенно важно договориться о правилах реакции: кто отвечает за какой тип алертов, в какие сроки стоит реагировать, что считается критичным инцидентом. Без этого даже идеально собранный сценарий превращается в фоновую помеху, потому что люди не понимают, что делать с потоком сигналов. В России к этому добавляется ещё один контекст — необходимость не только отвечать клиентам и аудитории, но и демонстрировать проверяющим органам, что у вас не просто есть мониторинг, а что вы осознанно им управляете.
Когда я смотрю на результат такого внедрения через месяц, хорошим признаком считаю не количество алертов, а стабильность их обработки. Если в отчётах видно, что большая часть уведомлений была просмотрена и по ним предприняты разумные действия (ответ, эскалация, фиксация в базе), значит, сценарий вписался в жизнь команды. Если же алерты висят непрочитанными или обрабатываются хаотично, это звоночек: либо фильтрация слишком грубая, либо процесс на стороне людей не продуман. Хороший мониторинг упоминаний в n8n работает как аккуратная система раннего предупреждения: вы не узнаете о репутационном пожаре из новостей, потому что поймали искру на уровне одного сообщения, да и то без лишней паники.
Чтобы удобнее было визуально отслеживать, что именно даёт такой сценарий, я использую разные формы представления данных: от простых сводок в Telegram до дашбордов и схем потоков. Одну из таких иллюстраций с собранными элементами мониторинга я отдельно выделяла в блог, потому что по ней удобно объяснять, какие ноды за какие эффекты отвечают, и где именно возникает экономия времени команды. Ниже как раз такой пример, где видно, как несколько простых шагов в n8n соединяются в понятный результат.
Я поняла, что один из ключевых бонусов от хорошо настроенного мониторинга — это не только скорость реакции, но и появление честных метрик. Мы наконец можем ответить на очень приземлённые вопросы: сколько упоминаний появляется в неделю, как меняется тональность, откуда прилетает больше всего негатива, какие темы чаще всего всплывают. Это позволяет не только тушить пожары, но и перестраивать продукты, поддержку и коммуникации в более системном ключе. Например, если за месяц накопилась пачка жалоб на один и тот же этап онбординга, это сигнал не только для саппорта, но и для продуктовой команды. В этом смысле n8n выступает тихим сборщиком фактологии, который делает невидимое видимым.
Управление результатами мониторинга в России ещё и про документируемость. Когда в компании есть описанный процесс: как берутся данные, как обрабатываются, как используются для решения задач, это снижает риски в глазах проверяющих. Если вдруг придётся объяснять, почему те или иные персональные данные оказались в базе, наличие прозрачного сценария в n8n станет хорошим аргументом, что это не стихийная обработка, а осознанный контролируемый процесс. В паре с политикой по ПДн и журналами обработки это формирует ту самую «white-data-зону», в которой можно не нервничать каждый раз, когда в новостях всплывают слова «штраф», «утечка» или «проверка».
Как встроить результаты мониторинга в повседневную работу команды
Чтобы мониторинг не жил отдельной жизнью, я обычно предлагаю сразу привязать его к регулярным ритуалам команды. Например, раз в неделю собирать короткий обзор по всем алертам, которые были за период, и обсуждать, какие из них привели к изменениям: исправлению багов, обновлению скриптов поддержки, исправлению информации на сайте. Это помогает людям увидеть, что алерты — не просто «ещё одно уведомление», а источник реальных улучшений. С течением времени такие обзоры становятся хорошей базой для ретроспектив и планирования, особенно если команда работает с ИИ-агентами и автоматизациями в нескольких зонах сразу. Мониторинг упоминаний здесь просто вплетается в общую логику «мы собираем данные, чтобы принимать решения, а не ради красивой статистики».
Ещё один практичный ход — связать мониторинг с задачами в трекере: когда приходит критичный алерт, n8n сразу создаёт задачу в выбранной системе (Jira, YouTrack, отечественные аналоги) с понятным описанием и ссылками. Это не только экономит время, но и убирает человеческий фактор «ой, я видел сообщение, но забыл завести задачу». На таком стыке технической и организационной автоматизации открывается главный потенциал n8n: он становится клеем между источниками данных, людьми и управленческими инструментами. В идеале человек вообще не должен вручную перенабивать ничего из бота в таск-менеджер — всё это должна делать автоматика, а люди уже принимают решения.
Чтобы держать в поле зрения, как вся эта конструкция работает, я иногда показываю более высокоуровневые схемы архитектур, где n8n — лишь один из элементов, но видно, как он связан с другими системами компании. Одну из таких схем я оформила как blueprint-решение под мониторинг бренда и алертов, и она хорошо заходит тем, кто мыслит категориями «система в целом», а не только «один скрипт». Визуально это помогает увидеть, что грамотный мониторинг — не набор разрозненных костылей, а продуманное решение с понятными точками входа и выхода.
В какой-то момент жизнь с таким мониторингом становится новой нормой: утренний обзор алертов заменяет бессистемный скроллинг соцсетей, а редкие сложные случаи помогают компании обсудить важные вопросы репутации, продукта и сервиса. Я люблю момент, когда команда понимает, что автоматизация перестала быть «игрушкой технарей» и стала частью общей культуры «мы измеряем и осознанно реагируем». И если в этот момент кто-то аккуратно обновит внутреннюю документацию или добавит пару строк в политику обработки ПДн — это уже высший пилотаж, когда техника и управление идут в одной связке.
Какие подводные камни чаще всего ломают автоматизацию
Когда ко мне приходят с фразой «мы пробовали мониторинг упоминаний через n8n, но что-то пошло не так», я почти всегда мысленно открываю один и тот же чек-лист типичных ошибок. На первом месте, как ни странно, не технические баги, а переоценка своих сил: команда строит слишком сложный сценарий сразу, а потом не может его поддерживать. На втором — игнорирование юридической части: данные бегают между зарубежными сервисами, хранятся непонятно где, согласия оформлены как-то вскользь в общем пользовательском соглашении. И только потом уже идёт классика жанра: нестабильные интеграции, неучтённые лимиты API, отсутствие нормального логирования. Всё это в сумме превращает изначально хорошую идею в источник хронического раздражения.
Я заметила, что одну из главных ловушек создаёт соблазн «заодно» подключить ещё пару-тройку сервисов, которые нравятся конкретному разработчику. В итоге в схему попадает, например, зарубежный парсер или облачная аналитика, которая по-тихому тянет к себе все данные для дополнительной обработки. В российской реальности это прямой риск, потому что локализация по 152-ФЗ не заканчивается на фразе «основная база у нас в РФ». Если хотя бы один элемент цепочки обрабатывает персональные данные за пределами страны без понятной правовой опоры, именно он становится слабым звеном. Поэтому я за то, чтобы регулярно пересматривать архитектуру мониторинга и безжалостно выкидывать из неё всё, что не вписывается в белый контур.
Чтобы не звучать голословно, я собрала небольшой набор типичных провалов, которые вижу в проектах чаще всего. Это не полный список, но он помогает быстро свериться: не идете ли вы сейчас по знакомой дорожке, которая уже ломала чужие сценарии. Каждый пункт тут — не теория, а живой кейс, который однажды привел к ночным правкам или неприятным разговорам с безопасностью.
Самые частые проблемы в проектах мониторинга — это не «падает n8n», а отсутствие процессов вокруг него: никто не владеет рисками, не читает логи и не думает, куда в реальности текут данные из интеграций.
Ещё одна тонкая зона — человеческий фактор. Даже если всё настроено идеально, всегда есть риск, что кто-то из сотрудников решит «облегчить себе жизнь» и начнёт выгружать упоминания в личные Google-таблицы или перекидывать фрагменты из алертов в незащищённые чаты. Формально это уже отдельный риск утечки, и никакой красивый сценарий в n8n его не перекроет. Поэтому я за то, чтобы параллельно с технической настройкой уделять время внутреннему просвещению: объяснять, что можно делать с данными мониторинга, а что нельзя, как долго их хранить локально и кому передавать. Когда люди понимают, зачем все эти ограничения, сопротивление падает, и система начинает работать как единое целое, а не набор взаимоисключающих практик.
Какие ошибки в настройке n8n особенно болезненны для российских проектов
Когда я разбираю неудачные кейсы по n8n настройке агента мониторинга, чаще всего вылезают четыре категории проблем. Первая — сценарий слишком монолитный: один огромный workflow на все случаи жизни, внутри которого десятки веток слабо документированы. Любое изменение превращается в операцию на открытом сердце, и все боятся нажать лишнюю кнопку. Вторая — жёсткая завязка на нестабильные внешние сервисы без fallback-логики: если один из источников или посредников падает, рушится вся цепочка, а не только часть. Третья — отсутствие разделения окружений: тесты идут сразу в бою, и любое экспериментальное изменение сразу сказывается на реальных данных. Четвертая — недооценка логирования: когда что-то идёт не так, понять, в какой именно точке случился сбой, почти нереально.
Я поняла, что особенно болезненно это бьет по российским компаниям, потому что к техническим сбоям добавляются юридические последствия. Например, если из-за сбоя часть данных ушла не туда, где мы их обязались хранить, или не была удалена в условленный срок, это уже не просто «ой, интеграция подвисла», а повод для официальных претензий. Поэтому в российских проектах с ПДн я всегда настаиваю на том, чтобы уделить внимание «скучным» вещам: разносить конфигурации по окружениям, использовать резервные маршруты, чётко описывать и проверять сценарии удаления или обезличивания данных. В каком-то смысле это та самая невидимая часть айсберга, без которой вся сияющая верхушка в виде красивых алертов не имеет особого значения.
Хорошая новость в том, что большинство этих ошибок исправляются, если один раз сесть и честно разобрать текущую схему. Иногда это занимает пару вечеров и несколько чашек кофе, иногда — полноценный мини-проект по рефакторингу, но в итоге n8n превращается из «сложного монстра» в аккуратный, предсказуемый инструмент. И мне приятно, когда после таких разборов команда говорит не «мы боимся трогать этот рабочий процесс», а «мы знаем, как он устроен и где его можно спокойно улучшать». Это и есть признак зрелости — когда автоматизация служит людям, а не наоборот.
Практические формулы, которые экономят часы
На этом этапе обычно хочется спросить: ну хорошо, а как всё это приземлить в простые правила, по которым можно строить свои сценарии без бесконечных консультаций с юристами и архитекторами. Я заметила, что большинству команд помогают не абстрактные принципы, а короткие рабочие формулы вида «если А и Б, значит, делаем В». Поэтому в проектах мониторинга упоминаний я вывела несколько таких конструкций, которые покрывают 80% типичных решений. Они не отменяют здравый смысл, но дают базовую сетку, в которую удобно вкладывать конкретную задачу. И да, это касается и юридической части 152-ФЗ, и чисто технических вопросов по n8n, и организационной рутины вокруг всего этого.
Первая формула касается законности обработки: можно обрабатывать, если у нас есть конкретная цель, конкретные данные, локализация в РФ и адекватная защита. Нет хотя бы одного элемента — значит, нужно либо доработать процесс, либо данные вообще не трогать. Вторая — про полезность алертов: уведомление считается полезным, если по нему можно предпринять осмысленное действие в течение одной минуты. Если это не так, сценарий нужно перепроектировать: пересмотреть правила фильтрации, канал доставки или формат сообщения. Третья — про прозрачность: процесс считается прозрачным, если новый человек в команде может за час понять, как устроен сценарий мониторинга и кто за что отвечает. Если требуется неделя и подсказки «того самого разработчика», ситуация неустойчива.
Чтобы эти формулы не остались абстракцией, я иногда свожу их в более наглядный формат мини-чек-листа, который удобно держать под рукой при проектировании или ревью сценария. Он охватывает и вопросы права, и архитектуры, и качества самих алертов. Ниже как раз тот самый набор, который я чаще всего использую в проектах, где сочетаются n8n, ИИ-агенты и живая команда поддержки или маркетинга.
- Правило: цель + данные + локализация + защита — обязательный минимум для любой обработки ПДн.
- Формула: полезный алерт = возможность реакции ≤ 1 минута + понятный текст уведомления.
- Вариант А: если сомневаетесь в законности, обезличьте данные или сократите их набор.
- Правило: один ответственный за процесс мониторинга, даже если исполнителей несколько.
- Формула: прозрачный сценарий = документация + логи + предсказуемое поведение при сбоях.
На практике эти простые конструкции часто спасают от избыточной сложности. Вместо того чтобы строить ещё один уровень условных веток или встраивать очередной сервис, команда задает себе вопрос: улучшает ли это время реакции, повышает ли прозрачность, вписывается ли в белый контур по 152-ФЗ. Если ответ «нет» хотя бы по одному пункту, имеет смысл притормозить и поискать более аккуратное решение. Иногда итогом такого размышления становится не новый нод в n8n, а изменение бизнес-процесса или внутренней инструкции — и это нормально. Автоматизация не должна маскировать кривые процессы, она лучше работает там, где основа уже выпрямлена.
Если ты дочитал(а) до этого места и ловишь себя на мысли, что хочется собрать свой сценарий мониторинга под российские реалии, но не очень понятно, с какой стороны подступиться, это абсолютно нормальное состояние. Я тоже не всё придумала за один вечер и многим обязана тем проектам, где мы вместе с командами проходили путь от «ноль мониторинга» до устойчивой системы. Часть таких разборов я уже начала систематизировать на сайте про автоматизацию через n8n и управление данными, а более живые рабочие кейсы разбираю в Telegram-канале про практику автоматизации и ИИ-инструменты. Там как раз много той самой «кухни», которая не попадает в сухие регламенты, но сильно упрощает жизнь, когда дело доходит до реальных запусков.
Что ещё полезно помнить про такой мониторинг
Я часто ловлю себя на желании закончить рассказы про мониторинг упоминаний чем-то вдохновляющим, но честно признаю: большая часть успеха здесь держится не на вдохновении, а на скучной дисциплине. Регулярные проверки логов, обновление ключевых слов, ревизия источников, корректировка сроков хранения данных — всё это рутинные шаги, без которых даже самая красивая архитектура n8n начнет рассыпаться. В российском контексте к этому добавляются периодические обновления законодательства, методичек Роскомнадзора и требований к локализации. Это не повод бояться, но хороший аргумент за то, чтобы держать процесс живым, а не рассматривать его как «сделали один раз и забыли».
Меня радует, что всё больше команд перестают воспринимать 152-ФЗ как препятствие и начинают видеть в нём рамку, которая помогает не утонуть в хаосе с данными. Когда ты изначально проектируешь мониторинг с учётом требований к согласию, защите и локализации, это прямым образом влияет на качество автоматизации. n8n в этом случае становится не просто инструментом интеграций, а способом перевести юридические и управленческие требования в работающий код: описать, кто что может видеть, где что хранится, какие действия автоматически запрещены. И в какой-то момент становится очевидно, что «white-data-зона» — это не пафосная вывеска, а очень прагматичный способ экономить нервы и деньги.
Если попробовать собрать всё сказанное в один образ, мониторинг упоминаний через n8n в России — это аккуратный домашний шкаф с полками, а не бесконечная свалка на балконе. Мы заранее решаем, какие вещи вообще имеет смысл хранить, на каких полках им место, как часто мы будем перебирать содержимое и кто имеет доступ к каким ящикам. Да, иногда в шкафу всё равно накапливается немного лишнего, но это уже история про периодические ревизии, а не про полную потерю контроля. И именно в этом месте автоматизация перестаёт быть модным словом, а превращается в очень земной инструмент: на одну чашку холодного кофе меньше, на десяток ручных проверок поисковой выдачи меньше, на пару нервных разговоров с проверяющими тоже.
Что ещё важно знать
Как запустить простой мониторинг в n8n, если я вообще не разработчик?
Начни с одного-двух источников и готовых нод n8n, например, вебхука и отправки уведомлений в Telegram. Сформулируй пару ключевых слов, сделай простую фильтрацию и проверь, что алерты действительно полезны. Со временем можно добавлять сложность, но лучше, если базовый сценарий будет понятен тебе без погружения в код.
Можно ли использовать n8n вместе с ИИ-моделью для анализа тональности отзывов?
Да, можно, если модель доступна из инфраструктуры в РФ и не нарушает требования к локализации данных. Ты можешь передавать в модель только фрагменты текста или обезличенные данные, а результат использовать как дополнительный признак для фильтрации алертов. Главное — не отправлять туда лишние персональные данные без необходимости.
Что делать, если источники не дают официальное API, но мне нужны оттуда упоминания?
В таком случае сначала оцени юридические риски и стабильность любых обходных решений. Иногда разумнее опираться на email-уведомления, RSS или официальные экспортные механизмы, чем городить парсеры сомнительного происхождения. Если всё-таки используешь парсинг, позаботься о хранении данных в РФ и минимизации ПДн.
Как понять, что алертов стало слишком много и система требует пересборки?
Если команда начинает игнорировать уведомления или массово ставит бота на mute, значит, фильтрация и пороги срабатывания подобраны неправильно. Отследи, сколько алертов реально приводят к действиям за неделю, и сократи или углуби правила, которые порождают «пустые» сигналы. Хороший ориентир — когда большинство алертов полезны и обработаны в разумный срок.
Можно ли обойтись без отдельного согласия на обработку персональных данных в мониторинге?
Иногда можно, если ты работаешь только с обезличенными данными или собираешь сугубо агрегированную статистику. Но если хранишь и используешь идентифицируемую информацию о людях, особенно для персонализированных действий, с 2025 года лучше иметь отдельное, чётко оформленное согласие. Это снижает риски споров и делает позицию компании более защищённой.
Что делать, если уже настроенный мониторинг оказался частично за пределами РФ?
Первым шагом останови или ограничь обработку тех данных, которые уходят за рубеж, и зафиксируй текущую архитектуру в виде схемы. Затем перенеси критичные части инфраструктуры в РФ, пересмотри договоры с поставщиками и обнови документы по ПДн. После этого можно адаптировать сценарий n8n под новую схему, постепенно убирая лишние иностранные элементы.