
Представьте: понедельник, 9 утра. В регистратуру московской медклиники выстроилась очередь из 20 человек. Все записаны на приём. Но администратор не может их принять — система 1С не работает. База пациентов недоступна. Записи потеряны.
Колл-центр разрывается от звонков — люди не могут дозвониться, потому что IP-телефония легла. Сайт клиники тоже не открывается — а это 30+ онлайн-записей в день, которые просто теряются.
Директор звонит IT-подрядчику. Тот обещает "посмотреть в течение дня". Через два часа перезванивает: "Сервер перегружен, сейчас перезагрузим". Ещё через час: "Всё работает, но мы не знаем, почему это произошло".
Это не выдумка. Это реальная ситуация сети из трёх медицинских клиник в Москве, с которой они жили три года. До тех пор, пока не посчитали реальные потери. Цифра — 300 000 рублей в месяц. Каждый. Месяц.
Сейчас расскажу, как мы за три месяца превратили их хаотичную IT-инфраструктуру в отказоустойчивую систему — с конкретными решениями, сроками и результатами.
Что было: инфраструктура на грани коллапса
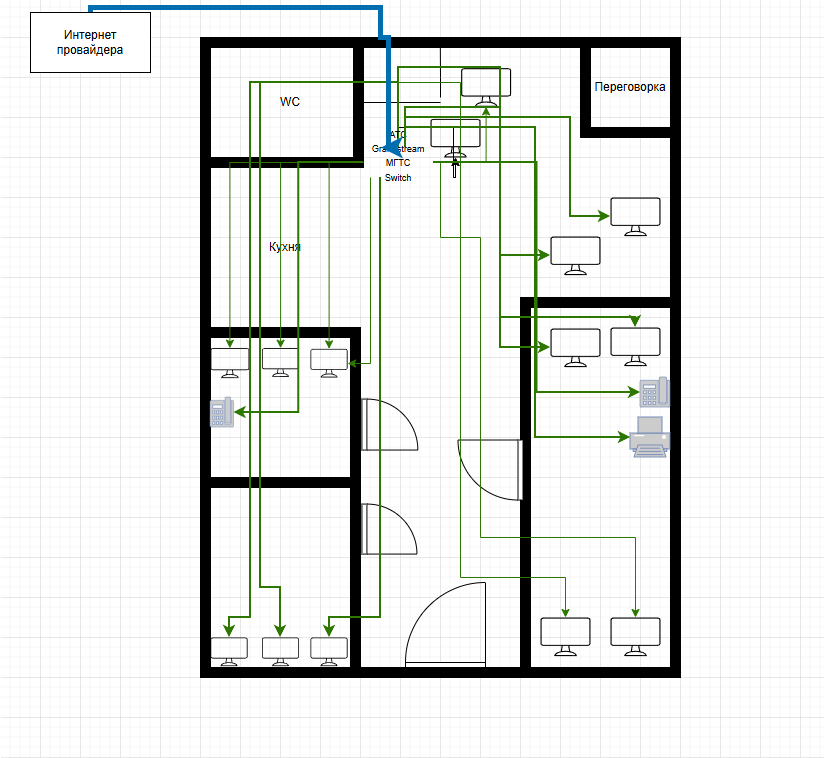
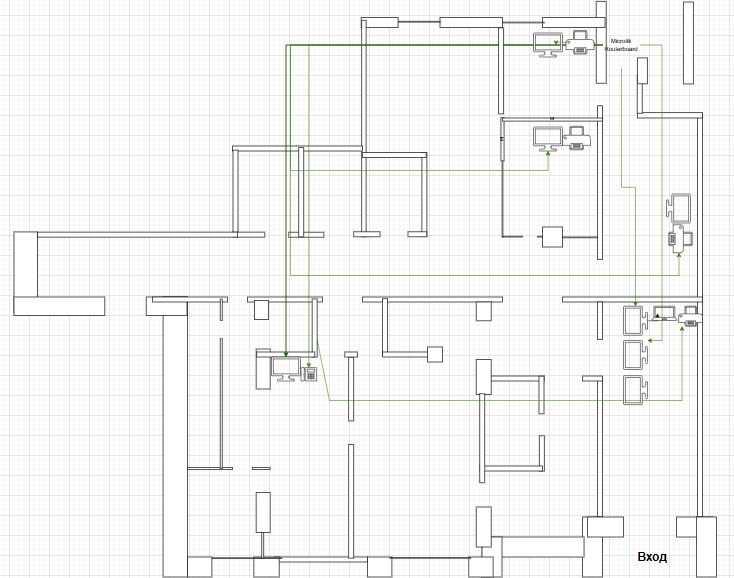
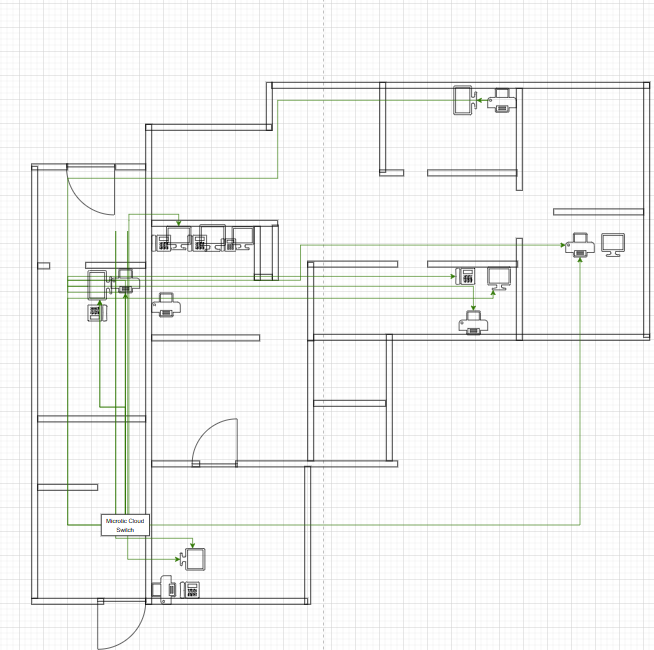
Сеть медицинских клиник — это не шутки. Три филиала в Москве, колл-центр, офис, дата-центр. 35 рабочих станций, 14 виртуальных серверов на одном физическом сервере Proxmox VE, сетевое хранилище, 8 единиц сетевого оборудования (Ubiquiti, Cisco, MikroTik), сайт клиники.
На первый взгляд — всё прилично. Но когда мы начали разбираться, вскрылся кошмар.
Проблема 1: Аварийные простои критичных систем
1С зависала 12+ часов в месяц. Это значит — пациентов не могут принять, записи теряются, финансовые операции не проводятся. Хаос в регистратуре, недовольные клиенты, потеря репутации.
Сайт клиники падал на 8+ часов в месяц. А это 30+ онлайн-записей каждый день, которые уходят к конкурентам. Умножаем на средний чек приёма — получаем прямые финансовые потери.
Колл-центр не работал 10+ часов в месяц. IP-телефония лежала, 200+ звонков от пациентов пропадали. Люди не дозванивались, злились, шли в другие клиники.
Итого: более 30 часов простоя критичных систем каждый месяц.
Проблема 2: Неэффективный IT-аутсорсинг
У клиники был подрядчик. Формально — договор с SLA 30 минут на реакцию. Реально — среднее время реакции 2+ часа. А часто и больше.
Конкретный пример: перенос серверов на Proxmox VE. Задача на 2-3 месяца максимум. Тянулась 7 месяцев. Семь!
Поддержки в выходные не было вообще. Если что-то ломалось в субботу — ждите до понедельника. А клиника работает 7 дней в неделю.
Проблема 3: Безопасность на уровне "а что это?"
Когда мы попросили доступы — нам прислали Excel-файл. Обычный, незащищённый Excel с паролями от всех серверов, роутеров, доменов. Лежал на рабочем столе у секретаря.
Резервные копии? Да, делались. Хранились на том же сервере, где крутились виртуальные машины. То есть если сервер сгорит — копии сгорят вместе с ним.
Документация сети? Её не было. Вообще. Никто не знал, как всё устроено. Бывший админ ушёл год назад, унеся знания с собой.
Что это стоило
Давайте посчитаем:
- Упущенная выгода: 30 потерянных записей в день × средний чек 3000 рублей × 30 дней = 2,7 млн рублей в год
- Переплата за неиспользуемые ресурсы: VDS-сервер, который никто не использовал — 33 000 рублей в год
- Расходы на неэффективного подрядчика: высокая стоимость при низком качестве
Итого: около 300 000 рублей ежемесячных потерь.
Что мы сделали: три этапа за три месяца
Этап 1. Аудит и переходный период (первый месяц)
Первым делом — взяли под контроль весь хаос.
Приняли все доступы. Собрали пароли от всех серверов, роутеров MikroTik, IP-телефонов, доменов. Проверили каждый. Занесли в защищённое хранилище паролей Passwork — никаких Excel-файлов на рабочем столе.
Провели аудит инфраструктуры. Обследовали все 14 виртуальных машин на гипервизоре Proxmox. Обнаружили, что половина из них не используется — просто висят мёртвым грузом, жрут ресурсы и тормозят остальные.
Отключили ненужное. Выключили неиспользуемые серверы, освободили ресурсы. Сервер сразу начал работать быстрее.
Этап 2. Оптимизация инфраструктуры (второй месяц)
Когда разобрались, что есть, начали чинить.
Резервное копирование — с нуля:
Развернули Proxmox Backup Server на отдельном хранилище. Настроили ежедневное резервное копирование всех критичных виртуальных машин. Еженедельное — полное. Теперь, если сервер сгорит — восстановим данные за 15 минут.
Автоматизировали бэкапы сайта через ISPmanager: и файлы, и базу данных. Каждые 3 часа — инкрементальная копия, раз в день — полная. Сайт теперь можно восстановить с точностью до часа.
Сеть и безопасность:
Настроили VPN-туннели между всеми филиалами на роутерах MikroTik через L2TP. Теперь данные между клиниками передаются по защищённому каналу.
Внедрили регламент проверки SSL-сертификатов. Сайт работает на Let's Encrypt, сертификаты обновляются автоматически. Но мы контролируем процесс — чтобы не случилось ситуации "сертификат истёк, сайт показывает ошибку".
Серверы:
Перенесли сайт клиники на новый сервер с Ubuntu 24. Старый был на древней версии, тормозил и падал. Сейчас — быстро, стабильно, защищено.
Создали тестовую среду для 1С. Раньше любое обновление накатывали сразу на продакшн — и часто что-то ломалось. Теперь сначала тестируем на копии, потом обновляем боевую систему.
Изолировали виртуальную машину для интернет-банкинга. Это критичная система — финансы, доступ к счетам. Теперь она в отдельной сети, с жёстким контролем доступа.
Этап 3. Документирование и мониторинг (третий месяц)
Когда всё заработало стабильно, начали документировать.
Схемы сетей: нарисовали подробные схемы для всех трёх филиалов, офиса, дата-центра. Где какое оборудование, какие IP-адреса, как всё связано. Теперь любой специалист может зайти и понять, как устроена инфраструктура.
Регламенты: создали 15 регламентов обслуживания. Проверка доменов и хостинга раз в две недели. Проверка работоспособности колл-центра. Проверка резервных копий. Всё по расписанию, ничего не забывается.
Система оповещений: настроили мониторинг всех критичных сервисов. Если 1С тормозит, сайт не отвечает или колл-центр падает — система сразу отправляет уведомление. Мы узнаём о проблеме раньше, чем клиника.
Результаты: цифры, которые говорят сами за себя
Прошло три месяца. Что изменилось?
Поддержка 24/7 с реакцией ≤ 15 минут. Не 2 часа, как было. 15 минут. В любое время, включая выходные. Критичный сервис упал — мы уже чиним.
100% доступность критичных сервисов за три месяца. Ноль простоев 1С. Ноль простоев сайта. Ноль простоев колл-центра. Клиника работает как часы.
Экономия 40% на IT-обслуживании. Удалили неиспользуемый VDS (32 976 рублей в год), оптимизировали процессы, сократили расходы.
Резервное копирование 100% систем. От критичных (1С — каждые 3 часа) до некритичных (раз в день). Если что-то сломается — восстановим за 15 минут.
98% активов задокументированы. Пароли, сети, серверы — всё в базе знаний. Никакой зависимости от одного человека, который "всё помнит".
Главный показатель:
Было: 30+ часов простоя критичных систем в месяц
Стало: 10 минут простоя в месяц
Падение на 99,4%.
Технологии, которые мы использовали
Для тех, кому интересны детали:
- Виртуализация: Proxmox VE, VMware
- Сети: MikroTik RouterOS, VLAN, L2TP VPN
- Операционные системы: Windows Server 2012-2019, Ubuntu, CentOS
- Резервное копирование: Proxmox Backup Server, ISPmanager
- Безопасность: Passwork (хранилище паролей), Let's Encrypt (SSL-сертификаты), изолированные виртуальные машины
Что говорит клиент
"Раньше мы каждую неделю слышали от администраторов: '1С не работает, что делать?' Звонили подрядчику, ждали часами. Теряли записи, пациенты уходили недовольные.
Сейчас я забыл, когда последний раз слышал жалобы на IT. Всё просто работает. Если что-то случается — узнаю об этом последним, потому что проблему уже решили.
Мы перестали терять пациентов из-за технических сбоев. Это сразу отразилось на выручке."
Главный вывод
IT в медицине — это не просто "компьютеры и интернет". Это инфраструктура, от которой напрямую зависит работа клиники. Упала 1С — пациентов не принимаете. Не работает колл-центр — теряете записи. Сайт лежит — клиенты уходят к конкурентам.
300 000 рублей в месяц — это цена "экономии" на IT. Наём дешёвого подрядчика, который "вроде что-то делает", оборачивается миллионными потерями.
Профессиональное обслуживание, отказоустойчивая инфраструктура, резервное копирование, мониторинг 24/7 — это не расходы. Это инвестиция, которая окупается в первый же месяц.
У вас медицинская клиника, стоматология или другой бизнес, где простой систем = потеря денег? Пишите в комментариях, разберём вашу ситуацию!
P.S. Хотите такой же результат для своей инфраструктуры? Начните с бесплатного аудита — покажем все "узкие места" и просчитаем реальную стоимость простоев. Подписывайтесь на канал — здесь только реальные кейсы с цифрами.