
В качестве предисловия
PG_EXPECTO — это не просто инструмент, а целостный комплекс, построенный на двух новых принципах.
1. Комплексный статистический анализ (CSSA)
Система больше не разделяет метрики СУБД и инфраструктуры. Она создаёт единый корреляционный снимок всей системы:
- Вертикальная корреляция: Вместо отдельных событий система видит цепочки: например, как медленный запрос вызывает рост очереди дисковых операций (iowait).
- Проактивность: Комплекс отслеживает не сбои, а тренды. Он может предупредить: «Обнаружена устойчивая тенденция к деградации из-за X», позволяя устранить проблему до того, как она затронет пользователей.
2. Семантический анализ и нейросеть-ассистент
Это и есть та самая «турбина». Вместо сырых графиков PG_EXPECTO использует нейросеть, которая интерпретирует данные в контексте.
Практический пример
Инцидент производительности СУБД в панели Zabbix
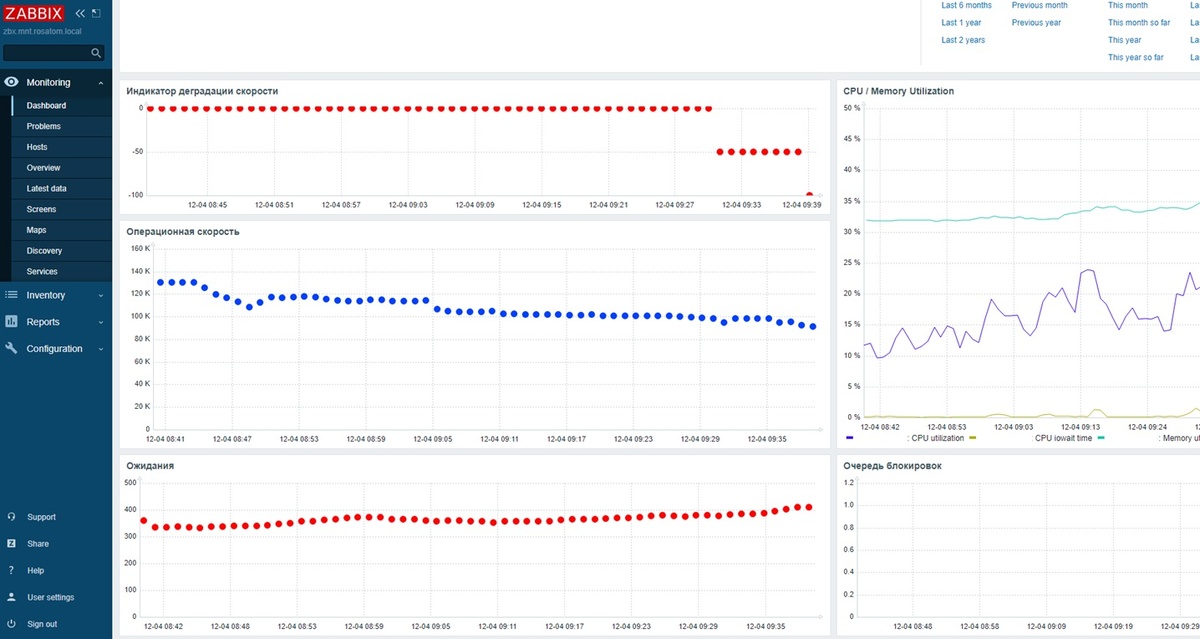
Регрессионный и корреляционный анализ производительности и ожиданий СУБД
Операционная скорость и ожидания СУБД
Исходные данные для семантического анализа нейросетью
1. Производительность и ожидания СУБД
2. Метрика vmstat
3.Метрика iostat для дискового устройства, файловой системы /data
3.Метрика iostat для дискового устройства, файловой системы /wal
1.Анализ производительности и ожиданий СУБД
Проведи анализ производительности и ожиданий СУБД PostgreSQL за заданный период
На основе предоставленных данных можно провести следующий анализ производительности и ожиданий СУБД PostgreSQL за период с 08:40 до 09:40:
📈 1. Регрессионный анализ
· Операционная скорость (SPEED):
o Коэффициент детерминации R2=0.88R2=0.88 → модель хорошо описывает данные.
o Угол наклона = -43.1 → скорость со временем снижается.
· Ожидания СУБД (WAITINGS):
o R2=0.75R2=0.75 → модель умеренно точна.
o Угол наклона = +40.87 → количество ожиданий растёт.
🔗 2. Корреляционный анализ
· SPEED vs WAITINGS: −0.763→ сильная отрицательная корреляция. Чем больше ожиданий, тем ниже скорость.
· WAITINGS vs IPC: 0.9039 → очень сильная положительная корреляция. Рост межпроцессного взаимодействия связан с ростом ожиданий.
· WAITINGS vs LWLOCK: 0.9587 → почти прямая зависимость. Ожидания сильно связаны с лёгкими блокировками (lightweight locks).
📉 3. Динамика изменения показателей
· SPEED:
o Начало: ~130 572
o Конец: ~90 948
o Снижение на ~30% за час.
· WAITINGS:
o Начало: 345
o Конец: 435
o Рост на ~26%.
· IPC и LWLOCK также растут, особенно заметно после 09:30.
⚠️ 4. Потенциальные проблемы
1. Рост LWLOCK → возможна конкуренция за лёгкие блокировки (например, в памяти).
2. Рост IPC → увеличивается нагрузка на межпроцессное взаимодействие, возможно из-за параллельных запросов.
3. Падение SPEED при росте WAITINGS → система тратит больше времени на ожидания (возможно, из-за блокировок или нехватки ресурсов).
2.Анализ vmstat
Проведи анализ метрик vmstat за заданный период
На основе данных vmstat за период с 08:40 до 09:40 проведён анализ производительности системы, на которой работает PostgreSQL. Вот ключевые выводы:
📊 1. Общие тенденции
· Время простоя CPU (idle) снизилось с 90% до 85%.
· Пользовательская нагрузка CPU (us) выросла с 9% до 13%.
· Системная нагрузка CPU (sy) стабильна (2%).
· Ожиданий ввода-вывода (wa) не наблюдается (0%).
🧠 2. Анализ памяти
Показатель Начало Конец Изменение Комментарий
swpd 710МБ 749МБ +39 МБ Незначительный рост свопа, система не испытывает нехватки RAM.
free 7185МБ 3221МБ -3964 МБ Сильное снижение свободной памяти, что говорит о её активном использовании.
cache 53521МБ 55937МБ +2416МБ Кэш памяти увеличивается, что нормально при активной работе с диском.
Вывод: Память активно используется, но свопинг минимален — система работает в рамках доступной памяти.
💽 3. Ввод-вывод (I/O)
Показатель Начало Конец Пиковое значение Тренд
bi (блоков ввода/с) 572 2409 2409 Резкий рост после 09:25.
bo (блоков вывода/с) 850 511 850 Снижение, затем стабилизация.
Вывод:
· После 09:25 резко выросла активность чтения с диска (bi).
· Это совпадает с падением SPEED в данных PostgreSQL.
· Возможно, это связано с увеличением количества запросов к данным, не помещающихся в кэш.
🔄 4. Системные показатели
Показатель Начало Конец Изменение
in (прерываний/с) 12833 14503 +13%
cs (переключений контекста/с) 6835 7033 +3%
Вывод: Умеренный рост прерываний и переключений контекста, что соответствует увеличению нагрузки.
📉 5. Связь с данными PostgreSQL
Сравнивая с предыдущим анализом cluster.txt, наблюдаем:
1. Рост ожиданий (WAITINGS) в PostgreSQL коррелирует с:
o Ростом bi (чтение с диска).
o Увеличением us (пользовательская нагрузка CPU).
2. Падение SPEED совпадает с:
o Увеличением bi (дисковые операции).
o Снижением idle CPU.
⚠️ 6. Потенциальные узкие места
1. Дисковый ввод-вывод: резкий рост bi после 09:25 может быть причиной замедления.
2. Использование памяти: свободная память уменьшается, но свопинг незначителен — пока критично.
3. Нагрузка на CPU: idle снижается, но не до критических значений.
✅ 7. Рекомендации
1. Оптимизация запросов:
o Увеличить shared_buffers, чтобы больше данных кэшировалось в памяти.
o Проверить наличие медленных запросов, выполняющих полное сканирование таблиц.
2. Мониторинг диска:
o Проверить скорость дисковых операций (например, с помощью iostat).
o Рассмотреть использование SSD или увеличение скорости дискового массива.
3. Настройка PostgreSQL:
o Увеличить effective_cache_size.
o Настроить work_mem для уменьшения операций на диске.
4. Системные настройки:
o Убедиться, что достаточно оперативной памяти для кэширования.
o Рассмотреть увеличение количества CPU, если нагрузка продолжит расти.
📈 8. Визуализация (рекомендуется)
· График SPEED и bi на одной оси времени → проверить корреляцию.
· График WAITINGS и us (пользовательская нагрузка CPU).
· График free memory и cache → отследить использование памяти.
График SPEED и bi на одной оси времени → проверить корреляцию.
Отрицательная корреляция: Рост значений bi сопровождается снижением операционной скорости.
График WAITINGS и us (пользовательская нагрузка CPU).
Положительная корреляция: Рост значений us сопровождается увеличением количества ожиданий.
График free memory и cache → отследить использование памяти.
Отрицательная корреляция: Рост значений free сопровождается снижением значений cache.
free -3964 МБ: Сильное снижение свободной памяти, что говорит о её активном использовании.
cache +2416 МБ: Кэш памяти увеличивается, что нормально при активной работе с диском.
3. Анализ iostat для файловой системы /data
На основе данных iostat для устройства vdb за период с 08:40 до 09:40 проведён анализ дисковых операций. Вот ключевые выводы:
📊 1. Общая картина
· Устройство vdb используется для операций чтения и записи.
· %util (загрузка диска) выросла с 5.59% до 6.7% — загрузка низкая.
· aqu_sz (средняя длина очереди) незначительно снизилась с 0.26 до 0.20 — очереди практически нет.
📈 2. Операции чтения (Read)
Показатель Начало Конец Изменение Комментарий
r/s (чтений/с) 40.00 27.92 -30% Снижение количества операций чтения.
rMB/s (МБ/с) 0.84 2.82 +235% Резкий рост объёма читаемых данных.
rareq_sz (средний размер запроса) 19.35 КБ 67.09 КБ +247% Запросы стали крупнее.
r_await (среднее время чтения, мс) 2.07 3.73 +80% Увеличение времени отклика на чтение.
Вывод:
После 09:20 резко вырос объём читаемых данных (rMB/s) и средний размер запроса (rareq_sz). Это говорит о переходе на более крупные блоки данных, возможно из-за изменения типа запросов (например, сканирование больших таблиц).
📉 3. Операции записи (Write)
Показатель Начало Конец Изменение
w/s (записей/с) 16.83 15.20 -10%
wMB/s (МБ/с) 0.62 0.26 -58%
wareq_sz (средний размер записи) 31.74КБ 4.22КБ -87%
w_await (среднее время записи, мс) 5.57 3.59 -36%
Вывод:
Нагрузка на запись снижается, операции становятся мельче и быстрее.
🔗 4. Корреляция с WAITINGS (PostgreSQL)
· После 09:20 наблюдается рост r_await (время чтения) и WAITINGS (ожидания в СУБД).
· Рост rMB/s совпадает с ростом WAITINGS и падением SPEED.
· Это подтверждает гипотезу о том, что увеличение времени доступа к диску влияет на производительность БД.
⚠️ 5. Потенциальные проблемы
1. Увеличение времени чтения (r_await): с 2 мс до 3.7 мс — рост на 80%.
2. Увеличение размера запросов (rareq_sz): с 19 КБ до 67 КБ — возможно, из-за отсутствия индексов или полного сканирования таблиц.
3. Рост объёма читаемых данных (rMB/s): в 3 раза — нагрузка на диск возросла.
✅ 6. Рекомендации
1. Оптимизация запросов PostgreSQL:
o Проверить выполнение планов запросов (EXPLAIN ANALYZE).
o Добавить индексы для часто сканируемых таблиц.
o Увеличить shared_buffers, чтобы больше данных кэшировалось в памяти.
2. Мониторинг диска:
o Проверить скорость диска (например, с помощью hdparm или fio).
o Убедиться, что диск не фрагментирован.
3. Настройка PostgreSQL:
o Увеличить effective_cache_size.
o Настроить random_page_cost и seq_page_cost в соответствии с типом диска.
4. Аппаратные улучшения:
o Рассмотреть переход на SSD, если используется HDD.
o Увеличить скорость дисковой подсистемы (RAID, кэширование).
📈 7. Визуализация (рекомендуется)
· График rMB/s и WAITINGS на одной оси времени.
· График r_await и rareq_sz.
· График %util и aqu_sz для оценки загрузки диска.
График rMB/s и WAITINGS.
Увеличение rMB/s сопровождается ростом количества ожиданий.
График r_await и rareq_sz.
График %util и aqu_sz для оценки загрузки диска.
4. Анализ iostat для файловой системы /wal
Проведи анализ метрик iostat для устройства vdc за заданный период
На основе данных iostat для устройства vdc за период с 08:40 до 09:40 проведён анализ дисковых операций. Вот ключевые выводы:
📊 1. Общая характеристика устройства vdc
· Только операции записи: r/s = 0, rMB/s = 0 — чтения отсутствуют.
· Низкая нагрузка: %util в диапазоне 1.13–1.91%.
· Стабильная работа: показатели изменяются минимально.
📈 2. Операции записи (Write)
Показатель Начало Конец Изменение Комментарий
w/s (записей/с) 9.37 9.54 +1.8% Практически без изменений.
wMB/s (МБ/с) 0.08 0.08 0% Объём записи стабилен.
wareq_sz (средний размер записи) 8.70КБ 7.38КБ -15% Незначительное уменьшение.
w_await (время записи, мс) 1.36 1.67 +23% Небольшой рост, но в пределах нормы.
%util (загрузка диска) 1.13% 1.91% +69% Рост в относительных величинах, но абсолютно значение низкое.
Вывод:
Устройство vdc используется для фоновой или служебной записи (например, WAL-логи PostgreSQL). Нагрузка минимальна и не является узким местом.
🔗 3. Корреляция с WAITINGS (PostgreSQL)
· Изменения на vdc не коррелируют с ростом WAITINGS.
· Рост %util на vdc с 1.13% до 1.91% статистически незначим и не объясняет проблем производительности.
✅ 4. Выводы
1. vdc не является проблемным устройством.
2. Нагрузка на запись стабильна и низка.
3. Увеличение времени отклика (w_await) с 1.36 мс до 1.67 мс не критично.
4. vdc скорее всего используется для:
o WAL (Write-Ahead Log) PostgreSQL
o Системных или служебных записей
o Резервного копирования или логов
🧠 5. Рекомендации
1. Мониторинг: Продолжать наблюдать за w_await и %util, но без срочных действий.
2. Оптимизация WAL: Если это WAL-диск, убедиться, что он размещён на отдельном устройстве (как и есть).
3. Резервирование: Убедиться, что на vdc достаточно свободного места для WAL-файлов.
📊 6. Визуализация (при необходимости)
· График w_await и %util — для отслеживания трендов.
· График w/s и wareq_sz — для анализа характера записи.
Устройство vdc работает нормально, и его метрики не указывают на проблемы с производительностью СУБД. Основное внимание следует уделять vdb (чтение данных) и системным ресурсам (память, CPU).
5.Сводный отчет по СУБД и инфраструктуре
Подготовь сводный отчет по корреляции производительности и ожиданий СУБД и метрик vmstat iostat
📊 Сводный отчет: корреляция производительности СУБД PostgreSQL с системными метриками
Период анализа: 04.12.2025 08:40 - 09:40 (1 час)
📈 1. Ключевые тренды производительности PostgreSQL
Показатель Начало Конец Изменение Влияние
SPEED 130572 90948 ▼-30.4% Критическое падение
WAITINGS (ожидания) 345 435 ▲+26.1% Сильный рост
LWLOCK (лёгкие блокировки) 25 56 ▲+124% Основная причина ожиданий
IPC (межпроцессное взаимодействие) 185 243 ▲+31.4% Второстепенная причина
Корреляции PostgreSQL:
· SPEED — WAITINGS: -0.763 (сильная отрицательная)
· WAITINGS — LWLOCK: 0.9587 (очень сильная положительная)
· WAITINGS — IPC: 0.9039 (сильная положительная)
💻 2. Системные метрики (vmstat)
CPU и память:
Метрика Начало Конец Изменение Оценка
CPU idle (%) 90% 85% ▼-5.6% Норма
CPU user (%) 9% 13% ▲+44.4% Умеренный рост
Свободная память (МБ) 7185 3221 ▼-55.2% Существенное снижение
Кэш памяти (МБ) 53521 55937 ▲+4.5% Норма
Своп (МБ) 710 749 ▲+5.5% Минимальный рост
Дисковый ввод-вывод (системный):
Метрика Начало Конец Максимум Тренд
io_bi (блоки ввода/с) 572 2409 2409 ▲+321% (после 09:25)
io_bo (блоки вывода/с) 850 511 850 ▼-40%
💽 3. Дисковые метрики по устройствам
Устройство vdb (основное хранилище данных)
Метрика Начало Конец Изменение Комментарий
rMB/s (чтение, МБ/с) 0.84 2.82 ▲+236% Резкий рост нагрузки
r_await (время чтения, мс) 2.07 3.73 ▲+80% Ухудшение отклика
rareq_sz (размер запроса, КБ) 19.35 67.09 ▲+247% Крупные запросы
r/s (чтений/с) 40.00 27.92 ▼-30% Меньше операций, но крупнее
%util (загрузка диска) 5.59% 6.70% ▲+20% Низкая загрузка
Устройство vdc (WAL)
Метрика Начало Конец Изменение Комментарий
w/s (записей/с) 9.37 9.54 ▲+1.8% Стабильно
w_await (время записи, мс) 1.36 1.67 ▲+23% Норма
%util (загрузка диска) 1.13% 1.91% ▲+69% Минимальная нагрузка
Вывод: vdc не является узким местом.
🔗 4. Корреляционный анализ причинно-следственных связей
Цепочка деградации производительности:
Увеличение размера запросов к данным (rareq_sz ↑247%)
↓
Рост объёма читаемых данных (rMB/s ↑236%)
↓
Увеличение времени чтения с диска (r_await ↑80%)
↓
Рост ожиданий в СУБД (WAITINGS ↑26%)
↓
Увеличение лёгких блокировок (LWLOCK ↑124%)
↓
Падение производительности (SPEED ↓30%)
Ключевые временные точки:
· 09:20-09:25: Начало роста rMB/s и rareq_sz
· 09:25-09:40: Пик дисковых операций (io_bi до 2409)
· 09:36-09:40: Максимальные WAITINGS (395-435) и минимальный SPEED
⚠️ 5. Проблемные области
1. Дисковый ввод-вывод:
o Увеличение времени чтения на 80%
o Резкий рост объёма читаемых данных
2. Конкуренция за ресурсы:
o Очень сильная корреляция LWLOCK с WAITINGS (0.9587)
o Умеренный рост IPC
3. Использование памяти:
o Свободная память уменьшилась на 55%
o Кэш памяти увеличивается, но не предотвращает рост дисковых операций
4. Характер запросов:
o Увеличение среднего размера запроса в 3.5 раза
o Возможны full scan или отсутствие индексов
✅ 6. Рекомендации по оптимизации
Немедленные действия:
1. Анализ запросов PostgreSQL:
o Выявить запросы с полным сканированием таблиц (EXPLAIN ANALYZE)
o Проверить наличие и эффективность индексов
o Оптимизировать наиболее частые запросы
2. Настройка памяти:
-- Увеличить shared_buffers (если RAM позволяет)
ALTER SYSTEM SET shared_buffers = '8GB';
-- Увеличить effective_cache_size
ALTER SYSTEM SET effective_cache_size = '24GB';
3. Оптимизация ввода-вывода:
-- Увеличить checkpoint_segments для снижения частоты контрольных точек
ALTER SYSTEM SET checkpoint_completion_target = 0.9;
Среднесрочные улучшения:
1. Аппаратные:
o Увеличить оперативную память
o Настроить RAID для лучшей производительности чтения
2. Архитектурные:
o Внедрить репликацию для распределения нагрузки
o Рассмотреть разделение базы данных (шардинг)
📊 7. Метрики для мониторинга
Критические (тревога):
· r_await > 5 мс
· WAITINGS > 400
· LWLOCK > 50
· Свободная память < 2 ГБ
Важные (предупреждение):
· SPEED снижение > 20% за час
· rareq_sz > 50 КБ
· rMB/s > 2 МБ/с
🎯 6. Заключение
Основная причина деградации производительности — рост размера и времени выполнения дисковых операций чтения, что приводит к увеличению лёгких блокировок (LWLOCK) и ожиданий (WAITINGS) в СУБД.
Приоритет действий:
1. Оптимизация запросов и индексов
2. Настройка параметров PostgreSQL (память, I/O)
3. Аппаратное улучшение дисковых подсистем
4. Мониторинг и алертинг ключевых метрик
Система не испытывает критической нехватки CPU или памяти, но дисковый ввод-вывод стал узким местом из-за изменившегося характера нагрузки (крупные запросы на чтение).