Для OLAP-нагрузки (аналитические запросы, отчеты, агрегации больших объемов данных) приоритеты метрик vmstat кардинально меняются. Здесь на первый план выходит пропускная способность (throughput) и эффективность использования ресурсов, а не низкая задержка отдельных операций. Группа 1: Критические индикаторы ограничений (Bottleneck) 1. wa (I/O wait time) Почему критично для OLAP: OLAP-запросы часто являются последовательными сканерами (sequential scan) больших таблиц. Они создают высокую нагрузку на пропускную способность хранилища (MB/s, IOPS). Высокий wa указывает, что процессоры простаивают в ожидании данных с диска, что является главным ограничением скорости выполнения запросов. Что смотреть: Значения выше 30-50% — явный признак того, что хранилище не успевает за запросами, и производительность упирается в диск. Это может быть как из-за медленных дисков, так и из-за конкуренции за I/O с другими процессами. 2. bi (blocks in) Почему критично для OLAP: Это прямая мера интенсивности
Для OLAP-нагрузки (аналитические запросы, отчеты, агрегации больших объемов данных) приоритеты метрик vmstat кардинально меняются. Здесь на первый план выходит пропускная способность (throughput) и эффективность использования ресурсов, а не низкая задержка отдельных операций.
Группа 1: Критические индикаторы ограничений (Bottleneck)
1. wa (I/O wait time)
- Почему критично для OLAP: OLAP-запросы часто являются последовательными сканерами (sequential scan) больших таблиц. Они создают высокую нагрузку на пропускную способность хранилища (MB/s, IOPS). Высокий wa указывает, что процессоры простаивают в ожидании данных с диска, что является главным ограничением скорости выполнения запросов.
- Что смотреть: Значения выше 30-50% — явный признак того, что хранилище не успевает за запросами, и производительность упирается в диск. Это может быть как из-за медленных дисков, так и из-за конкуренции за I/O с другими процессами.
2. bi (blocks in)
- Почему критично для OLAP: Это прямая мера интенсивности чтения данных с диска. Для OLAP высокий bi — это норма, но его величина и стабильность показывают, насколько эффективно система может "загружать" данные для обработки.
- Что смотреть: Стабильно высокое значение (десятки-сотни тысяч блоков в секунду) — признак активной работы. Если bi высокое, но wa низкий — система хорошо справляется с чтением. Если bi низкое при высокой wa — возможны проблемы с планировщиком I/O или фрагментацией.
3. r (runnable processes)
- Почему критично для OLAP: Аналитические запросы часто распараллеливаются (parallel sequential scan, parallel hash). Если r постоянно и значительно превышает количество ядер — это указывает на высокую конкуренцию за процессорное время и формирование очереди. Однако для коротких всплесков это может быть нормой.
- Что смотреть: Устойчивое состояние, где r > (число ядер * 1.5). Это значит, что система не успевает обрабатывать запросы в реальном времени, и они накапливаются в очереди.
Группа 2: Ключевые метрики утилизации ресурсов
4. us (user time)
- Почему важно для OLAP: Основная метрика загрузки CPU. Для OLAP высокий us (60-90%) — это хороший знак. Он означает, что процессоры заняты полезной работой: фильтрацией строк, вычислением агрегатных функций (SUM, AVG), выполнением hash- или merge-joins. Низкий us при активных запросах — тревожный сигнал об узком месте (чаще всего, высокий wa).
- Что смотреть: Стремимся к высоким значениям. Низкий us + высокий wa = упираемся в диск.
5. free / cache (память)
- Почему важно для OLAP:
Кэш (cache): Чрезвычайно важен. Если рабочий набор данных (часто используемые таблицы, индексы) помещается в кэш ОС, bi падает до нуля, а производительность взлетает. Большой объем cache — цель для OLAP-сервера.
Свободная память (free): Должна быть минимальной (но не нулевой). Система должна использовать всю доступную память для кэширования. Резкое падение free и рост cache — норма при первом прогоне большого запроса. - Что смотреть: Тренд на уменьшение free и рост cache при запуске запросов — норма. После — стабильность.
6. sy (system time)
- Почему важно для OLAP: Может быть повышен из-за:
Системных вызовов для I/O (часто при последовательном чтении).
Нагрузки от планировщика процессов (при высокой конкуренции, высоком r).
Работы механизмов межпроцессного взаимодействия при параллельных запросах. - Что смотреть: Значение выше 20-30% может указывать на накладные расходы ОС. В сочетании с высоким bi это ожидаемо. Но если sy аномально высок при низкой полезной нагрузке (us) — это повод для исследования.
Группа 3: Вторичные и контекстные метрики
7. bo (blocks out)
- Почему менее критично для OLAP: Запись в OLAP в основном — это временные файлы (work_mem переполнение, сортировки во внешней памяти), запись промежуточных результатов материализованных представлений или ETL-процессы. Всплески возможны, но обычно не являются основным узким местом.
- Что смотреть: Резкие всплески могут замедлять запросы, если они конкурируют за I/O с операциями чтения (bi).
8. b (blocked processes)
- Почему менее критично для OLAP: Запросы часто выполняются поодиночке или небольшими группами. Блокировка одного аналитического запроса на I/O — это не катастрофа для системы в целом (в отличие от OLTP). Однако постоянное наличие b > 0 может указывать на проблемы с хранилищем или на то, что запросы слишком интенсивно используют временные файлы.
9. si (swap in)
- Почему важно, но по-другому: Для OLAP свопинг данных процесса postgres так же губителен, как и для OLTP. Однако свопинг фоновых процессов или кэша ОС менее критичен. Цель по-прежнему — si = 0. Если OLAP-запрос вызывает свопинг, ему не хватает памяти (work_mem, maintenance_work_mem).
10. cs (context switches)
- Почему важно: Чрезмерно высокие значения могут указывать на неоптимальную работу с параллельными запросами или слишком большое количество одновременных сессий, выполняющих тяжелые запросы. Это увеличивает накладные расходы.
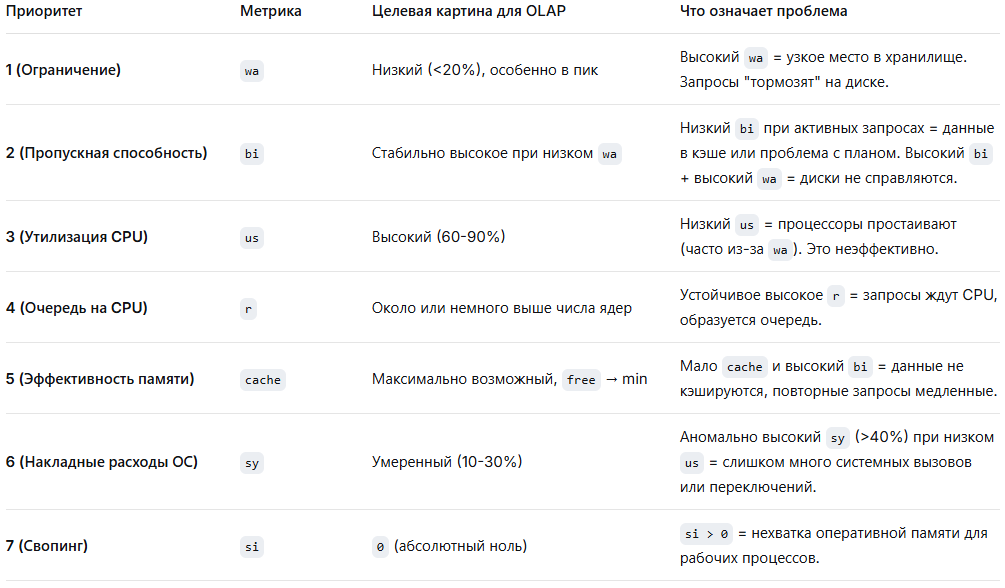
Итоговая таблица приоритетов для OLAP-диагностики
Типичные сценарии проблем OLAP в связке метрик:
- «Дисковое узкое место»: wa ↑↑, bi ↑, us ↓, r может быть высоким (процессы ждут I/O). Решение: Ускорить хранилище (SSD/NVMe, RAID), увеличить кэш (RAM), оптимизировать запросы на чтение (индексы для фильтрации, партиционирование).
- «Идеальная работа (CPU-bound)»: us ↑↑ (близко к 100%), wa низкий, bi умеренный или низкий (данные в кэше), r на уровне ядер. Это хорошая картина: система упирается в процессорные вычисления.
- «Нехватка оперативной памяти для кэша»: После перезагрузки или на новых данных: bi ↑↑, cache растет медленно, free падает. Последующие запуски того же запроса: bi падает, us растет. Решение: Увеличить RAM для кэширования общих наборов данных.
- «Слишком высокая параллельность»: r ↑↑ (>> ядер), us высокий, sy высокий, cs очень высокий. Общая пропускная способность системы падает из-за накладных расходов на переключение контекста. Решение: Ограничить количество одновременно выполняемых тяжелых запросов (через пулы соединений, max_parallel_workers, resource queues).