Для OLTP-нагрузки приоритеты меняются, так как этот тип работы предъявляет специфические требования: множество коротких транзакций, высокий параллелизм, критически важна низкая задержка (latency) и согласованность данных. Группа 1: Критические индикаторы (производительность падает "здесь и сейчас") 1. wa (I/O wait time) Почему критично для OLTP: Высокий wa означает, что процессы (в том числе backend-процессы Postgres) простаивают в ожидании операций с диском. Для OLTP с его короткими транзакциями это смертельно: задержка каждой транзакции растет, пропускная способность (TPS) падает. Основные причины: медленные random reads (индексы, данные), запись WAL, интенсивная работа checkpoint. Что смотреть: Значение выше 10-15% — тревожный сигнал. Выше 20-30% — серьезная проблема. Нужно смотреть в связке с bi, bo и b. 2. b (blocked processes / processes sleeping) Почему критично для OLTP: Прямой индикатор того, что процессы не могут выполняться, потому что ждут ресурс (чаще всего — завершения

Для OLTP-нагрузки приоритеты меняются, так как этот тип работы предъявляет специфические требования: множество коротких транзакций, высокий параллелизм, критически важна низкая задержка (latency) и согласованность данных.
Группа 1: Критические индикаторы (производительность падает "здесь и сейчас")
1. wa (I/O wait time)
- Почему критично для OLTP: Высокий wa означает, что процессы (в том числе backend-процессы Postgres) простаивают в ожидании операций с диском. Для OLTP с его короткими транзакциями это смертельно: задержка каждой транзакции растет, пропускная способность (TPS) падает. Основные причины: медленные random reads (индексы, данные), запись WAL, интенсивная работа checkpoint.
- Что смотреть: Значение выше 10-15% — тревожный сигнал. Выше 20-30% — серьезная проблема. Нужно смотреть в связке с bi, bo и b.
2. b (blocked processes / processes sleeping)
- Почему критично для OLTP: Прямой индикатор того, что процессы не могут выполняться, потому что ждут ресурс (чаще всего — завершения операции ввода-вывода). Для OLTP, где важна высокая параллельность, даже 1-2 постоянно заблокированных процесса указывают на узкое место, которое заставляет все последующие запросы становиться в очередь.
- Что смотреть: Любое постоянное ненулевое значение, особенно в пиковое время. b > 0 + высокий wa = подтверждение проблемы с подсистемой хранения.
3. si (swap in)
- Почему критично для OLTP: Даже эпизодический свопинг рабочих страниц памяти, где расположены индексы или часто используемые таблицы, приводит к катастрофическому росту задержек (с микросекунд до миллисекунд). OLTP-система рассчитана на работу данных в памяти. si > 0 — это авария.
- Что смотреть: Абсолютный ноль — цель. Даже si = 1 — это повод для немедленного расследования.
Группа 2: Важные индикаторы нагрузки и насыщения ресурсов
4. r (runnable processes)
- Почему важно для OLTP: Показывает конкурентную нагрузку на CPU. Если r постоянно превышает количество физических ядер сервера в 2-3 раза, это указывает на очередь выполнения и рост времени отклика. Для OLTP с большим числом одновременных подключений (max_connections) это ключевой метрикой насыщения CPU.
- Что смотреть: r > (число ядер * 2) — признак высокой загрузки CPU и потенциального роста latency.
5. us (user time) и sy (system time)
- Почему важно для OLTP: Высокий us может быть нормой для CPU-интенсивных OLTP-запросов (сложные WHERE, агрегации). Однако в связке с высоким r это указывает на недостаток CPU-мощности.
- Особый акцент на sy: Неожиданно высокий sy для OLTP может указывать на:
Очень большое количество подключений -> высокие накладные расходы на планировщик ОС.
Частые системные вызовы (например, из-за неправильной настройки fsync, commit_delay).
Проблемы с блокировками (latch, spinlock) внутри ядра ОС. - Что смотреть: us+sy > 70-80% при наличии r >> ядер — признак ограничения по CPU.
6. bo (blocks out)
- Почему важно для OLTP: Отражает интенсивность записи на диск. Для OLTP с его частыми COMMIT это в первую очередь запись WAL. Также высокий bo может быть вызван активной работой фоновых писателей (bgwriter, checkpointer) при контрольных точках. Резкие всплески bo, совпадающие с ростом wa и b — признак проблемы с настройкой контрольных точек (checkpoint_completion_target, max_wal_size) или медленным хранилищем.
7. bi (blocks in)
- Почему важно для OLTP: В идеале должен быть низким, так как часто используемые данные (индексы, "горячие" таблицы) должны находиться в shared_buffers и OS cache. Постоянно высокий или скачкообразный bi указывает на то, что рабочее множество данных не помещается в оперативную память, и PostgreSQL вынужден постоянно подчитывать данные с диска, что убивает производительность OLTP.
Группа 3: Контекстные метрики (помогают понять причину)
8. cs (context switches)
- Почему важно для OLTP: Чрезмерно высокие значения (сотни тысяч в секунду) указывают на большое количество активных процессов, что приводит к высоким накладным расходам. Может быть симптомом слишком большого max_connections или неэффективной работы с пулом соединений на стороне приложения.
9. free / buff / cache (память)
- Для OLTP акцент смещается: Абсолютное значение free не так важно. Ключевое — отсутствие свопинга (si) и низкий bi. Если free мало, но cache велик, а si и bi равны нулю — это нормальная картина для системы, где память эффективно используется для кэширования.
10. so (swap out)
- Редко актуально: Может быть ненулевым при старте системы или вытеснении неактивных фоновых процессов. Сам по себе не так критичен, как si, но является предупреждающим знаком.
Итоговая таблица приоритетов для OLTP-диагностики
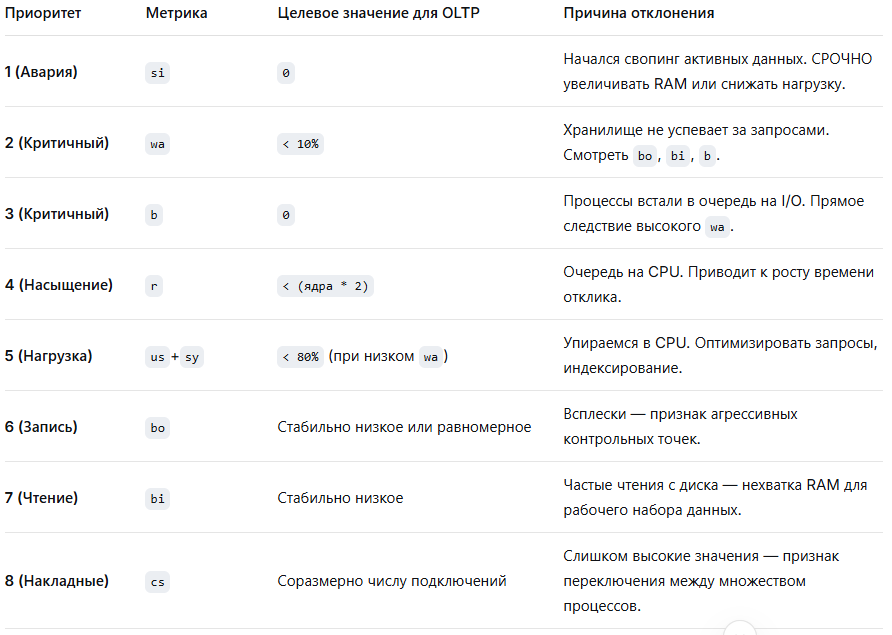
Типичные сценарии проблем OLTP в связке метрик:
- «Медленный диск / проблема с контрольными точками»: wa ↑, b ↑, bo ↑ (всплесками). si=0.
- «Нехватка оперативной памяти для рабочего набора»: bi ↑ (постоянно), wa ↑, r может быть высоким из-за ожиданий. Позже может появиться si.
- «Нехватка CPU из-за плохих запросов»: us ↑, r ↑, wa низкий, si=0.
- «Слишком много одновременных подключений»: sy ↑, cs ↑, r ↑, общая производительность падает при росте нагрузки.