
В статье представлены результаты эксперимента по проверке гипотезы о том, что использование агрегации через ARRAY для получения максимального значения может быть значительно эффективнее классического подхода с функцией MAX. С помощью инструмента нагрузочного тестирования pg_expecto сравнили производительность двух альтернативных запросов и зафиксировали впечатляющий результат.
ℹ️Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
Задача и постановка эксперимента
Экспериментальная проверка влияния на производительность запроса изменения паттерна MAX на паттерн ARRAY.
Экспериментальная проверка паттерна MAX vs ARRAY
Итак, немного проиграв в объеме SQL-кода, мы сделали запрос гораздо более понятным алгоритмически как для человека, так и для PostgreSQL. За это он нас вознаградил ускорением в 5 раз - с 4.587ms до 0.933ms.
Тестовая таблица
CREATE TABLE cli (
id integer PRIMARY KEY,
name text
);
CREATE TABLE doc (
cli integer,
dt date
);
CREATE INDEX ON doc(cli, dt);
INSERT INTO cli(id, name)
SELECT id.id, name
FROM generate_series(1, 1e4) id ,
LATERAL
(
SELECT
id, string_agg(chr(32 + (random() * 95)::integer), '') name
FROM
generate_series(1, (random() * 255)::integer)
) T;
INSERT INTO doc(cli, dt)
SELECT
(random() * 1e4)::integer cli,
'2025-01-01'::date + (random() * 365)::integer dt
FROM
generate_series(1, 1e6);
CREATE INDEX ON cli(name text_pattern_ops);
Тестовый запрос-1 : использование агрегатной функции max
SELECT
cli.id,
max(doc.dt) dt-- дата последнего документа
FROM
cli JOIN doc ON doc.cli = cli.id
WHERE
cli.name LIKE '!%' -- клиенты с "именем", начинающимся на !
GROUP BY
cli.id
HAVING
count(*) > 1;
Тестовый запрос-2 : использование array
SELECT
cli.id,
doc.dts[1] dt -- вместо max
FROM
cli,
LATERAL
(
SELECT
ARRAY
(
SELECT
dt
FROM
doc
WHERE
cli = cli.id
ORDER BY
dt DESC -- не забыли отсортировать
LIMIT 2 -- ограничили чтение
) dts
) doc
WHERE
cli.name LIKE '!%' AND
array_length(doc.dts, 1) > 1; -- вместо count
План выполнения тестового запроса-1 :
использование агрегатной функции max
HashAggregate (cost=583.35..584.60 rows=33 width=8) (actual time=6.079..6.102 rows=104 loops=1)
Group Key: cli.id
Filter: (count(*) > 1)
Batches: 1 Memory Usage: 32kB
-> Nested Loop (cost=4.06..508.35 rows=9999 width=8) (actual time=0.153..4.112 rows=10554 loops=1)
-> Bitmap Heap Scan on cli (cost=3.64..81.95 rows=100 width=4) (actual time=0.133..0.376 rows=104 loops=1)
Filter: (name ~~ '!%'::text)
Heap Blocks: exact=80
-> Bitmap Index Scan on cli_name_idx (cost=0.00..3.61 rows=100 width=0) (actual time=0.101..0.102 rows=104 loops=1)
Index Cond: ((name ~>=~ '!'::text) AND (name ~<~ '"'::text))
-> Index Only Scan using doc_cli_dt_idx on doc (cost=0.42..3.26 rows=100 width=8) (actual time=0.011..0.024 rows=101 loops=104)
Index Cond: (cli = cli.id)
Heap Fetches: 0
План выполнения тестового запроса-2 :
использование array
Bitmap Heap Scan on cli (cost=3.62..146.54 rows=33 width=8) (actual time=0.136..2.492 rows=104 loops=1)
Filter: ((name ~~ '!%'::text) AND (array_length(ARRAY(SubPlan 2), 1) > 1))
Heap Blocks: exact=80
-> Bitmap Index Scan on cli_name_idx (cost=0.00..3.61 rows=100 width=0) (actual time=0.054..0.055 rows=104 loops=1)
Index Cond: ((name ~>=~ '!'::text) AND (name ~<~ '"'::text))
SubPlan 1
-> Limit (cost=0.42..0.48 rows=2 width=4) (actual time=0.007..0.007 rows=2 loops=104)
-> Index Only Scan Backward using doc_cli_dt_idx on doc (cost=0.42..3.28 rows=100 width=4) (actual time=0.007..0.007 rows=2 loops=104)
Index Cond: (cli = cli.id)
Heap Fetches: 0
SubPlan 2
-> Limit (cost=0.42..0.48 rows=2 width=4) (actual time=0.012..0.012 rows=2 loops=104)
-> Index Only Scan Backward using doc_cli_dt_idx on doc doc_1 (cost=0.42..3.28 rows=100 width=4) (actual time=0.011..0.012 rows=2 loops=104)
Index Cond: (cli = cli.id)
Heap Fetches: 0
Результаты нагрузочного тестирования
Паттерн MAX
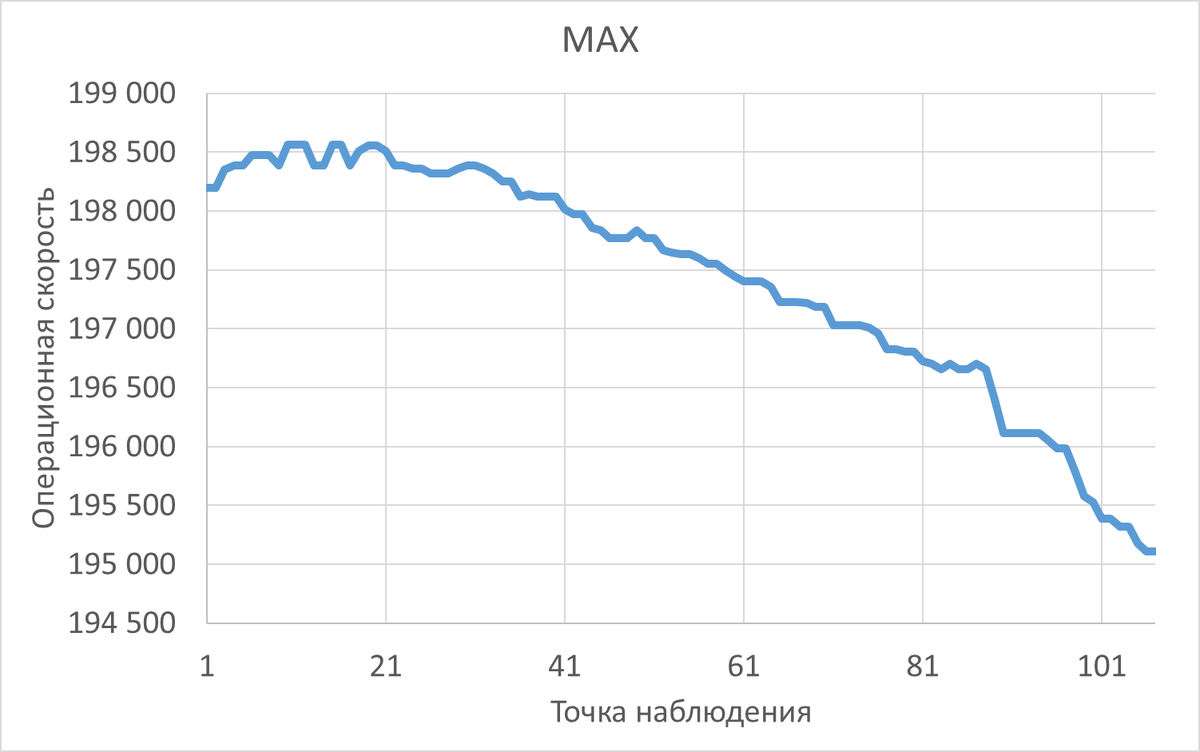
Паттерн ARRAY
Сравнительный график изменения операционной скорости для паттерна MAX и паттерна ARRAY
Среднее увеличение операционной скорости при использовании ARRAY по сравнению с использованием MAX составило 2 730%
Анализ метрик производительности инфраструктуры
Чек-лист CPU
Сравнительный анализ производительности
1. Нагрузка на CPU
- Тест-1 (MAX): cpu_us = 98%, cpu_sy = 2% - практически 100% загрузка, система работает на пределе
- Тест-2 (ARRAY): cpu_us = 77-79%, cpu_sy = 15-19%, cpu_id = 3-4% - более сбалансированная нагрузка, есть запас производительности
2. Очередь процессов (procs_r)
- Тест-1: Начинается с 11 и постепенно растет до 28 к концу теста
- Тест-2: Стабильно держится в диапазоне 11-16, без выраженного роста
3. Системные прерывания и переключения контекста
- Тест-1:
system_in: с 9099 растет до 16569 (+82%)
system_cs: с 4573 растет до 100354 (+2095%) - Тест-2:
system_in: с 58118 снижается до 15543 (-73%)
system_cs: с 126932 снижается до 100354 (-21%)
4. Память и I/O
- Своп (swpd): Одинаковый в обоих тестах (187) - норма
- Свободная память (free):
Тест-1: снижается с 214 до 220
Тест-2: снижается с 287 до 227 - I/O блоки (io_bo):
Тест-1: снижается с 79 до 48
Тест-2: стабильно около 50-55
Ключевые выводы
🚨 Проблемы паттерна MAX:
- 100% загрузка CPU - система не имеет резерва
- Растущая очередь процессов - накапливаются задачи в ожидании
- Экспоненциальный рост переключений контекста - высокие накладные расходы
- Деградация производительности во времени
✅ Преимущества паттерна ARRAY:
- Оптимальная загрузка CPU (96-97%) с запасом
- Стабильная очередь процессов - нет накопления
- Снижение системных издержек - меньше переключений контекста
- Стабильная производительность на протяжении всего теста
Заключение
Паттерн ARRAY демонстрирует на порядок лучшую эффективность - он обеспечивает сравнимую производительность с существенно меньшими системными издержками и стабильностью работы.