Введение: зачем вообще нужны «колокола», «светофоры» и REI
Историческая дата — это не цифра из школьного учебника.
Это результат отбора, сопоставления и взвешивания источников:
- одни сведения опираются на астрономию и жёсткие документы,
- другие противоречат друг другу,
- третьи дают только косвённые намёки.
Чтобы не «подбирать» даты под привычную картинку, я разработал комплексную методику, которая сочетает три инструмента:
- «колокола» — распределения вероятности по годам;
- «светофоры» — формализованная система статусов и весов источников;
- REI (Research Evidence Index) — индекс источников с явной трассировкой «цитата → статус → вклад в расчёт».
Всё вместе это образует процедуру, которую я называю:
Байесовская триангуляция с источниковой трассировкой (БТ-REI, Bayesian Triangulation with Research Evidence Index).
Автор методики — Руслан Абдуллин.
Важно сразу подчеркнуть два момента:
- Это альтернативная историография.
Я сознательно не воспроизвожу общепринятую академическую хронологию, а строю другую шкалу на основе чётко заданных правил работы с источниками и Δ-слоями. - Это фактически альтернативное летоисчисление.
Шаги:
сначала события привязываются к «обычному» григорианскому времени (CE_can) через астрономические и календарные расчёты (например, AH → CE_can по табличному исламскому календарю);
затем ключевой «учебный» коридор (например, 570–632 гг. CE_can) переустанавливается в другой участок истории — в моём случае в конец XII века (CE_alt) с помощью Δ-сдвигов;
всё, что вне этого коридора, остаётся в CE_can.
То есть методика не просто предлагает новые даты, а работает одновременно с двумя шкалами — канонической и альтернативной, и перевод между ними задан явно, а не «по настроению».
Что означает «байесовская триангуляция с источниковой трассировкой»
Название метода — это короткое техническое описание того, что происходит внутри.
«Байесовская»
Мы не выбираем одну «правильную» дату, а строим распределение вероятности по годам.
Пусть X — интересующая нас дата (рождение, хиджра, смерть и т. п.). Тогда:
- мы рассматриваем разумный диапазон лет,
- для каждого года считаем, насколько он согласуется со всеми имеющимися свидетельствами,
- получаем не одно число, а «колокол» p(X) по годам.
В самом простом виде:
p(X | источники) ∝ p₀(X) · L₁(X) · L₂(X) · … · Lₖ(X)
где:
- p₀(X) — исходное (априорное) представление: все годы в выбранном диапазоне сначала примерно равны;
- Lₖ(X) — вклад k-го источника: астрономического якоря, хроники, структурной связи между датами и т. д.
«Триангуляция»
Мы принципиально не опираемся на одну линию аргументов.
В ход идут:
- астрономические события (затмения, кометы, сверхновые),
- письменные традиции разных регионов (арабские, византийские, латинские, восточноазиатские тексты),
- структурные связи («между хиджрой и смертью прошло около 10–11 лет» и т. п.).
Как корабль в море фиксирует своё положение по нескольким ориентирам, так и здесь год события «находится» там, где пересекаются разные независимые линии свидетельств.
«С источниковой трассировкой» (REI)
Каждый шаг расчёта можно развернуть до конкретной цитаты.
Для этого есть REI — индекс источников, оформленный в виде карточек, где указано:
- короткая цитата (на языке оригинала) и перевод;
- полная ссылка: автор, издание, том, страницы;
- тип источника (затмение, комета, хроника, структурное соотношение);
- статус по «светофору» (зелёный, жёлтый, контекст, исключён);
- участок шкалы, на который источник влияет.
Это не декоративное приложение. Именно через REI любой несогласный может сказать:
«Вот эта конкретная карточка и её вес мне не кажутся оправданными — давайте изменим их и пересчитаем колокол».
Как БТ-REI соотносится с ИА-Δ и альтернативным летоисчислением
В моей работе два метода идут параллельно:
- ИА-Δ (интервальный анализ с контролируемым сдвигом)Он отвечает на вопрос:
«Можно ли наложить два ряда правителей или событий так, чтобы при сдвиге на Δ лет их интервалы хорошо совпали?»
На вход подаются два ряда интервалов (начала и окончания правлений).
Вводится сдвиг Δ.
Считается, насколько хорошо один ряд «ложится» на другой (через ε-ошибки, IoU и т. п.).Это даёт Δ-слои: какие «учебные» века естественно распаковываются в более поздние периоды. - БТ-REI (байесовская триангуляция с источниковой трассировкой)Здесь задача другая:
«В какой год на абсолютной шкале времени (CE_can и CE_alt), с какой неопределённостью, приходится конкретное событие?»Мы строим:
колокола p(X) по годам;
совместные распределения для связанных дат (например, хиджра H и смерть D);
HPD-интервалы (кратчайшие интервалы, содержащие 68% и 95% «массы» распределения).
Связка с альтернативным летоисчислением такая:
- Δ-слои из ИА-Δ задают, как именно «учебные» VII–IX века разъезжаются по реальной шкале;
- БТ-REI, используя астрономию и тексты, пришивает конкретные события к:
CE_can — каноническому времени (через, например, AH → CE_can),
CE_alt — альтернативной шкале, где коридор 570–632 CE_can встраивается в конец XII века.
Другими словами, ИА-Δ даёт форму перекрытий и значения Δ, а БТ-REI претворяет это в конкретные годы с указанием неопределённости.
Колокола: как выглядит вероятность по годам
Интуитивно:
- по горизонтали — годы (… 1179, 1180, 1181, 1182, 1183, …),
- по вертикали — относительная вероятность.
Чем выше точка над конкретным годом, тем больше вероятность, что событие X приходится именно на этот год.
Ключевые элементы:
- мода — год, где колокол достигает максимума;
- форма и ширина — насколько уверенно можно говорить о датировке (узкий пик или широкое плато);
- HPD 68% / 95% — самые узкие интервалы, где сосредоточено 68% и 95% «массы» распределения.
Пример:
- для хиджры H:
мода p(H) = 1182 (CE_can);
HPD 68% = 1182–1182;
HPD 95% = 1181–1183. - для смерти D:
мода p(D) = 1193 (CE_can);
HPD 68% = 1193–1194;
HPD 95% = 1192–1194.
А уже потом, на уровне CE_alt, эта цепочка «пересаживается» на альтернативную шкалу, где традиционный VII век оказывается «распакованным» в конец XII века.
Светофоры: как качество источника превращается в числа
Чтобы не тянуть один и тот же текст то вверх, то вниз по настроению, вводится формализованная система статусов.
Условно:
- зелёный — надёжный источник (жёсткое астрономическое событие, хорошо верифицируемая хроника);
- жёлтый — полезный, но с заметной неопределённостью;
- контекст — декларативно не участвует в расчёте, только помогает комментировать;
- исключён — сознательно выведен из модели.
Каждому статусу сопоставлены:
- численный вес;
- характерная ширина «шапки» вклада по годам.
Это дисциплинирует:
- если хронике повышают статус до «зелёной», это отражается в файлах настроек;
- любой пересчёт можно воспроизвести, сравнив, как именно менялись веса.
REI: как устроен паспорт каждого источника
REI (Research Evidence Index) — это список карточек, где для каждого фрагмента источника фиксируется:
- цитата и перевод;
- точная ссылка на издание;
- тип (затмение, комета, хроника, структурная связь и т. п.);
- статус по «светофору»;
- указание, на какую дату или участок шкалы источник влияет (B, FR, H, MC, D, структура H → D и т. д.).
Практический эффект:
- любая дата из итогового вывода «поднимается» до конечного набора REI-карточек;
- любой спор по датировке превращается в спор о конкретных карточках, а не о «впечатлении от корпуса».
Как БТ-REI строит и читает альтернативную шкалу (CE_can / CE_alt)
Важный элемент моей методики — чёткое разделение между:
- CE_can — «обычной» григорианской шкалой (то, как дата выглядела бы без альтернативных сдвигов);
- CE_alt — альтернативной шкалой, на которой «учебный» VII век и его окружение оказываются в конце XII века.
На уровне алгоритма это выглядит так:
- Все астрономические якоря и календарные пересчёты делаются в CE_can.
Пример: дата по хиджре 589 AH → через tabular-календарь → интервал конца 1193 – начала 1194 CE_can. - Для особых «учебных» коридоров (например, 570–632 CE_can) задаётся Δ-сдвиг в CE_alt.
Смысл: всё, что в канонической шкале лежит внутри этого окна, в альтернативной читается как XII век. - Всё, что вне этого окна:
остаётся в CE_can,
или получает другие Δ-коррекции, если это предусмотрено более общей Δ-картой.
Так получается, что:
- внутри локального анализа колокола p(B), p(H), p(D) живут в CE_can;
- на уровне «большой картины» привычный VII век в учебной сетке соответствует диапазону конца XII века в CE_alt;
- и именно так появляется альтернативная биография Пророка, сохраняя внутренние интервалы, но меняя привязку к «реальному» историческому фону.
Итог: что даёт связка «колокола – светофоры – REI» в рамках альтернативной хронологии
Если сжать всё до нескольких тезисов.
- Методика БТ-REI формализует альтернативную историографию.
Это не набор интуитивных гипотез, а последовательная схема:
задали якоря, Δ-слои и статусы источников →
получили конкретные колокола в CE_can →
перенесли их в CE_alt по оговорённым правилам →
получили альтернативную шкалу событий. - Даты перестают быть «догмой» и становятся результатом эксперимента.
Можно честно сказать:
«При этих допущениях B = 1130, H = 1182, D = 1193 (HPD до 1194) в CE_can,
а в CE_alt это означает, что “учебный” VII век фактически сидит внутри конца XII века». - Спор переносится с уровня “верю / не верю” на уровень конкретных карточек и весов.
Любой критик может:
указать на конкретный астрономический якорь;
оспорить статус или вес;
пересчитать колокола в другом сценарии и сравнить результат. - ИИ-чаты становятся интерфейсом лаборатории.
Архив и алгоритмы устроены так, что:
ИИ может брать на себя рутину (REI-карточки, AH → CE_can);
человек концентрируется на выборе якорей, Δ-слоёв и интерпретации;
весь процесс — от цитаты до числа и обратно — становится диалоговым и воспроизводимым.
Приложение. Внутренняя математика БТ-REI для технического читателя
В этом приложении я (Руслан Абдуллин) фиксирую то, что в основном тексте было только обозначено: как именно считаются вклады L_k(t), как устроены совместные распределения p(H, D) и как разложен по слоям архив, с которым работает БТ-REI.
1. Дискретная шкала и базовая модель
Я сознательно использую дискретную по годам шкалу вместо непрерывной по времени:
- выбирается диапазон лет
T = {t_min, …, t_max}
например, T = {1100, …, 1220}; - для каждой целевой даты X (B — рождение, H — хиджра, D — смерть и т. п.) задаётся массив значений
p_X[t] для всех t ∈ T.
Базовая формула:
p_X(t | источники) ∝ p0_X(t) * L_1^X(t) * L_2^X(t) * … * L_K^X(t)
где:
- p0_X(t) — априор (обычно «почти ровный» по всему диапазону T),
- L_k^X(t) — вклад k-го источника в дату X,
- K — количество источников (якорей), влияющих на эту дату.
После перемножения всех вкладов выполняется нормировка:
- считаем сумму S = Σ_t p_X_raw(t) по всем годам,
- делим каждое значение на S:
p_X(t) = p_X_raw(t) / S.
Так p_X(t) превращается в корректное распределение вероятности по годам:
- Σ_t p_X(t) = 1,
- p_X(t) ≥ 0 для всех t.
Точно такая же схема используется для B, H, D и любых других дат, которые я включаю в модель.
2. Типы вкладов L_k(t)
Каждый источник превращается в функцию L_k(t) по годам. Я использую три базовых типа:
- гауссовы (колоколообразные) вклады — для астрономических и жёстких дат;
- «оконные» вклады — для текстовых интервалов «между… и…»;
- структурные вклады — для связей вида D ≈ H + 10–11 лет.
2.1. Гауссов вклад для астрономического якоря
Типичный случай: затмение, сверхновая или комета с хорошо известным годом mu_k и характерной погрешностью sigma_k.
Формула:
L_k(t) = exp( -0.5 * ((t - mu_k) / sigma_k)^2 ) ^ alpha_k
где:
- mu_k — «центральный» год (например, SN 1181 → mu_k = 1181),
- sigma_k — ширина (в годах); малое sigma_k даёт узкий пик,
- alpha_k — коэффициент усиления/ослабления в зависимости от статуса «светофора».
Привязка статуса:
- зелёный (надежный): alpha_k близок к 1.0 или чуть больше;
- жёлтый (осторожный): alpha_k < 1.0 (обычно 0.5–0.8);
- контекст: либо очень малое alpha_k, либо вообще не входит в расчёт;
- исключён: L_k(t) = 1 для всех t (источник никак не влияет).
Важно: абсолютная величина L_k(t) неважна, важна только форма по t. Общая нормировка всё равно потом «съедается» при делении на сумму.
2.2. Оконные вклады для текстовых интервалов
Если хроника говорит:
«Событие X было при таком-то правителе (правил с A по B год)»,
я не фиксирую один год, а даю источнику вклад-трапецию:
- внутри интервала [A, B] — плато с почти одинаковыми значениями;
- мягкие спады за пределами интервала, чтобы позволить небольшие отклонения.
Один из удобных вариантов:
- внутри [A, B]:
L_k(t) = 1 - снаружи использовать затухающие «хвосты», например экспоненциальные или те же гауссовы:
L_k(t) = exp( -|t - A| / tau ) при t < A
L_k(t) = exp( -|t - B| / tau ) при t > B
где tau — характерный масштаб допуска (в годах).
Если источнику присвоен жёлтый статус, я увеличиваю tau (шире допуск) и/или уменьшаю вес через alpha_k.
2.3. Структурные vínculos между датами (пример H → D)
Для связи «между хиджрой H и смертью D прошло примерно 10–11 лет» используется отдельный вклад L_struct(H, D):
L_struct(H, D) = exp( -0.5 * (( D - (H + delta) ) / tau )^2 )
где:
- delta ≈ 10.5 — «средняя» разность лет,
- tau ≈ 1.5 — допустимый разброс.
Интерпретация:
- если D близок к H + 10.5, вклад близок к 1;
- если D сильно отходит от этого значения, вклад быстро падает.
Так я не «прибиваю» D к H + 10.5 жёстко, а задаю мягкое гауссово ограничение.
3. Совместные распределения и теплокарты p(H, D)
Отдельные «колокола» p_H(H) и p_D(D) полезны, но для настоящей реконструкции я использую совместное распределение p(H, D).
3.1. Базовая формула
Сначала считаются «одиночные» распределения p_H(H) и p_D(D) по их собственным якорям. Затем на сетке пар (H, D):
p_raw(H, D) = p_H(H) * p_D(D)
* L_struct(H, D)
* L_eclipses(H)
* L_comets(D)
* L_layers(H, D)
где:
- L_struct(H, D) — структурная связь «между H и D ≈ 10–11 лет»;
- L_eclipses(H) — дополнительные вклады затмений вокруг хиджры;
- L_comets(D) — вклады болидов и комет вокруг смерти;
- L_layers(H, D) — вклад Δ-слоёв (слоевые согласования между традициями).
После этого:
p(H, D) = p_raw(H, D) / Σ_{H,D} p_raw(H, D)
где сумма берётся по всей H×D-сетке.
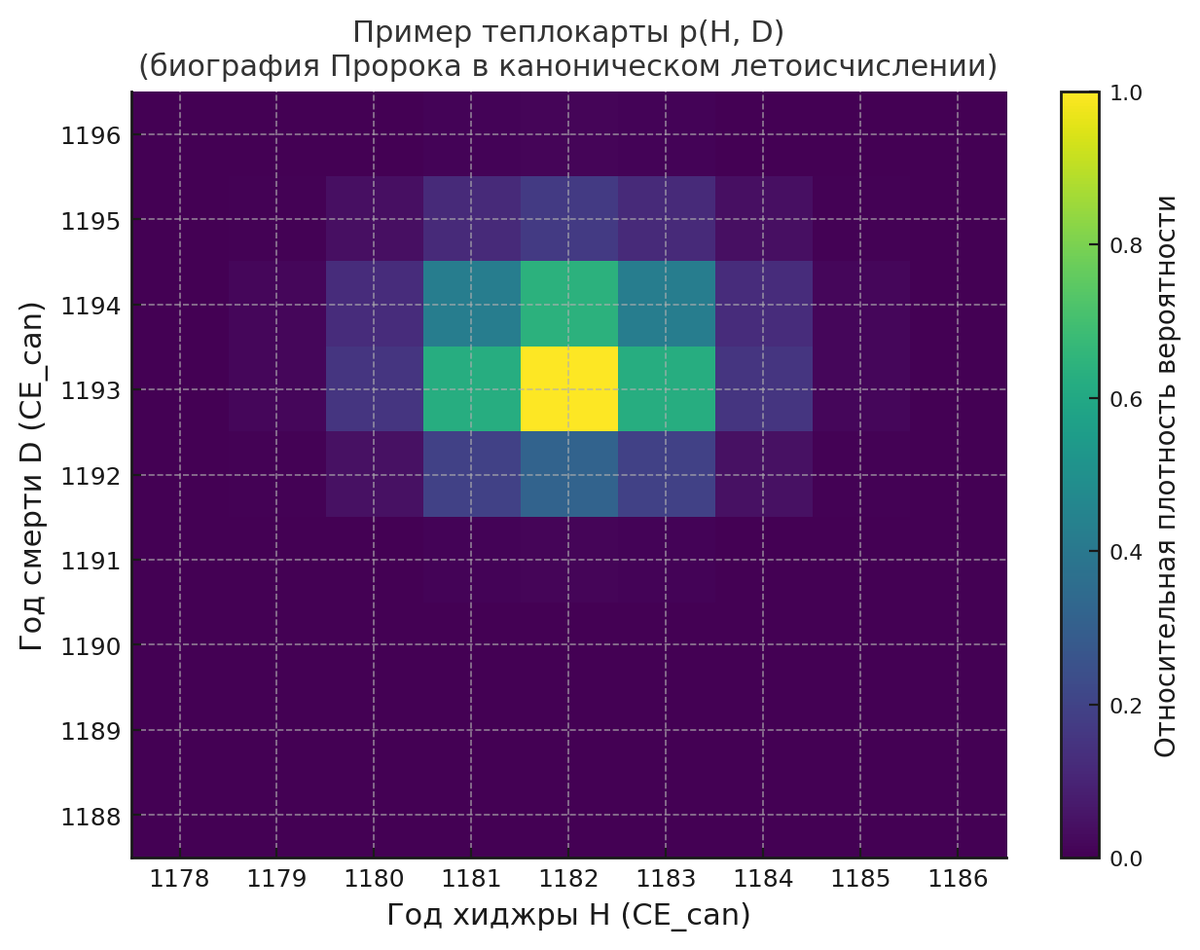
3.2. Как выглядит теплокарта на практике
Если взять диапазон лет 1100–1220 и отрисовать p(H, D) как матрицу, по осям будут:
- горизонталь: годы для H (хиджра),
- вертикаль: годы для D (смерть).
Цвет (или интенсивность) в клетке (H, D) — значение p(H, D).
Типичная картина для моей реконструкции:
- яркий максимум около H ≈ 1182, D ≈ 1193;
- облако «вытянуто» вдоль диагонали D ≈ H + 10–11 — это визуальное проявление структурного условия;
- по D заметно небольшое «правое плечо» до 1194 года — вклад окон 589 г. хиджры и комет конца 1193 – начала 1194 г.
Маргинальные распределения восстанавливаются из теплокарты:
p_H_final(H) = Σ_D p(H, D)
p_D_final(D) = Σ_H p(H, D)
далее по ним считаются:
- мода (год с максимальным значением),
- HPD 68% и HPD 95% (самые узкие интервалы, где лежит 68% и 95% «массы» распределения).
4. Как статусы «светофора» превращаются в числа
Сами по себе статусы (зелёный / жёлтый / контекст / исключён) — качественные. В БТ-REI они жёстко привязаны к числам:
- таблица статусов:
каждый якорь k получает статус status_k ∈ {green, yellow, context, excluded}. - словарь весов:например:
weight.green = 1.0,
weight.yellow = 0.6,
weight.context = 0.1,
weight.excluded = 0.0. - при построении L_k(t):
выбираю базовую форму (гаусс, окно, структурный вклад);
затем поднимаю в степень weight.* или умножаю на коэффициент:
L_k(t) := (L_k_base(t)) ^ weight.status_kлибо
L_k(t) := 1 + weight.status_k * (L_k_base(t) - 1)(оба подхода эквивалентны по смыслу: чем меньше вес, тем ближе вклад к «ничего не делает»).
Результат:
- зелёный якорь создаёт узкий и высокий пик,
- жёлтый даёт более низкий и широкий вклад,
- контекст почти не влияет на форму колокола, но присутствует в REI,
- исключённый вообще не меняет распределение.
5. Слоевые Δ-вклады L_layers(H, D)
Δ-слои приходят из отдельного интервал-анализа (ИА-Δ), где я сопоставляю целые династические ряды.
Каждый слой задаёт условие вида:
«если H и D попадают в такие-то зоны, то такая комбинация согласуется с Δ-мостами лучше».
Формально это ещё один множитель:
L_layers(H, D) = Π_s L_s(H, D)
для всех слоёв s.
Простейший вид L_s(H, D):
- = 1, если пара (H, D) попадает в «разрешённый» прямоугольник или диагональную полосу, согласованную с Δ-сдвигом;
- плавно убывает к 0, если пара начинает выходить за пределы этих зон.
Таким образом:
- Δ-слои не «рисуют» колокола с нуля,
- они поддерживают те области H и D, где разные традиции (арабская, византийская, латинская, восточноазиатская) сшиваются без сильных конфликтов.
6. Структура слоёв архива: от текста до колокола
Архив, с которым работает БТ-REI, разбит на несколько логических слоёв. Ниже — схема слоёв и их роли.
6.1. Слой REI-карточек (docs/REI/…)
Задача: превратить «сырой» текст из источников в структурированные карточки.
В каждой карточке фиксируется:
- краткая цитата на языке оригинала;
- перевод;
- полная ссылка на издание (автор, название, том, страницы);
- тип источника (eclipse, comet, supernova, chronicle, structural, …);
- какие даты затрагивает (B, H, D или связи между ними);
- служебные пометки (комментарий, уровень спора и т. п.).
На этом слое нет чисел, только связка:
«строка текста → сущность (якорь) → идентификатор».
6.2. Слой статусов и весов (data/ANCHORS_STATUS., data/anchors_weights.)
Следующий слой — перевод качества источника в вес:
- ANCHORS_STATUS:
таблица, где каждой карточке REI присвоен статус «зелёный / жёлтый / контекст / исключён». - anchors_weights:
словарь численных параметров для статусов (веса, величины sigma/tau, дополнительные коэффициенты).
Этот слой отвечает за то, как именно качественные решения («этот текст надёжный, а этот сомнительный») превращаются в параметры для L_k(t).
6.3. Слой календарных преобразований (data/ah_ce_mapping.*)
Здесь фиксируется:
- как пересчитываются даты по хиджре (AH) в григорианские (CE) по табличной схеме;
- как поверх этого задаётся альтернативное летоисчисление (коридор 570–632 и сдвиг к «поздней» шкале), если оно используется;
- контрольные таблицы: какие AH-годы и месяцы попадают в какие CE-окна.
Этот слой нужен, чтобы любой текст вида «589 г. хиджры» был однозначно привязан к числовой временной оси, на которой строятся колокола.
6.4. Слой численных расчётов (data/posterior_*.csv)
Результат работы всех предыдущих слоёв — массивы:
- p_B(t), p_H(t), p_D(t) по годам,
- совместные p(H, D) на сетке.
Они сохраняются в виде простых таблиц:
- для «колокола» — два столбца (год, p),
- для теплокарты — тройки (H, D, p).
На этом слое уже нет текстов, только числа.
6.5. Слой QA и чувствительности (qa/…)
Отдельный слой отвечает за проверки:
- чувствительность к изменениям весов жёлтых источников;
- поведение колокола при выключении контекста;
- проверка разности D − H относительно структурного ожидания (10–11 лет);
- проверка того, что AH→CE-таблицы согласуются с астрономическими окнами.
Здесь хранятся:
- журналы прогонов,
- альтернативные версии колоколов,
- сравнительные таблицы «до/после».
6.6. Слой слепка (SC/append_only/canonX/…)
Этот слой — «замороженный кадр» архива на момент публикации:
- копии ключевых таблиц (колокола, теплокарты),
- статусы и веса на тот момент,
- минимальный набор REI-карточек, достаточный для воспроизведения результата,
- контрольные хеши файлов.
Режим append-only означает:
- уже записанные файлы не перезаписываются и не удаляются;
- новые версии кладутся отдельно;
- слепок canonX/ остаётся эталоном, к которому можно вернуться через годы.
6.7. Публикационный слой (publication/…)
Финальный слой — материалы «для людей»:
- сводные таблицы якорей,
- краткие описания метода,
- графики колоколов и теплокарт,
- текстовые конспекты.
Сюда попадает то, что выносится в статьи, доклады и популярные тексты, тогда как остальные слои остаются «под капотом».
7. Как всё это работает вместе
Вся машина БТ-REI в технических терминах — это конвейер:
- Текст → REI:
источники разбиваются на карточки с чёткими идентификаторами. - REI → статусы/веса:
каждому якорю присваивается статус «светофора» и численные параметры. - AH/локальные календарі → CE/alt-CE:
все даты приводятся к одной числовой шкале лет. - Якоря → L_k(t):
для каждого источника строится вклад L_k(t) (или L_k(H, D) для структурных и слоевых связей). - L_k → p_X(t):
для B, H, D последовательно перемножаются все вклады, выполняется нормировка, считаются моды и HPD-интервалы. - p_H, p_D → p(H, D):
строится совместное распределение, теплокарта, восстанавливаются маргинальные p_H_final, p_D_final. - QA и слепки:
модель прогоняется под разными наборами весов/статусов, проверяется устойчивость; стабильный вариант фиксируется в canon-слепке.
В результате:
- любой «колокол» в статье — это не рисунок «по ощущениям», а отражение массивов p_X(t) из архива;
- любая точка на теплокарте p(H, D) может быть «размотана» назад до набора конкретных L_k, а через них — до REI-карточек и цитат в источниках.
Это и есть ядро БТ-REI как байесовской триангуляции с источниковой трассировкой: от строки текста до числа в колоколе и обратно по одному и тому же прозрачному маршруту.