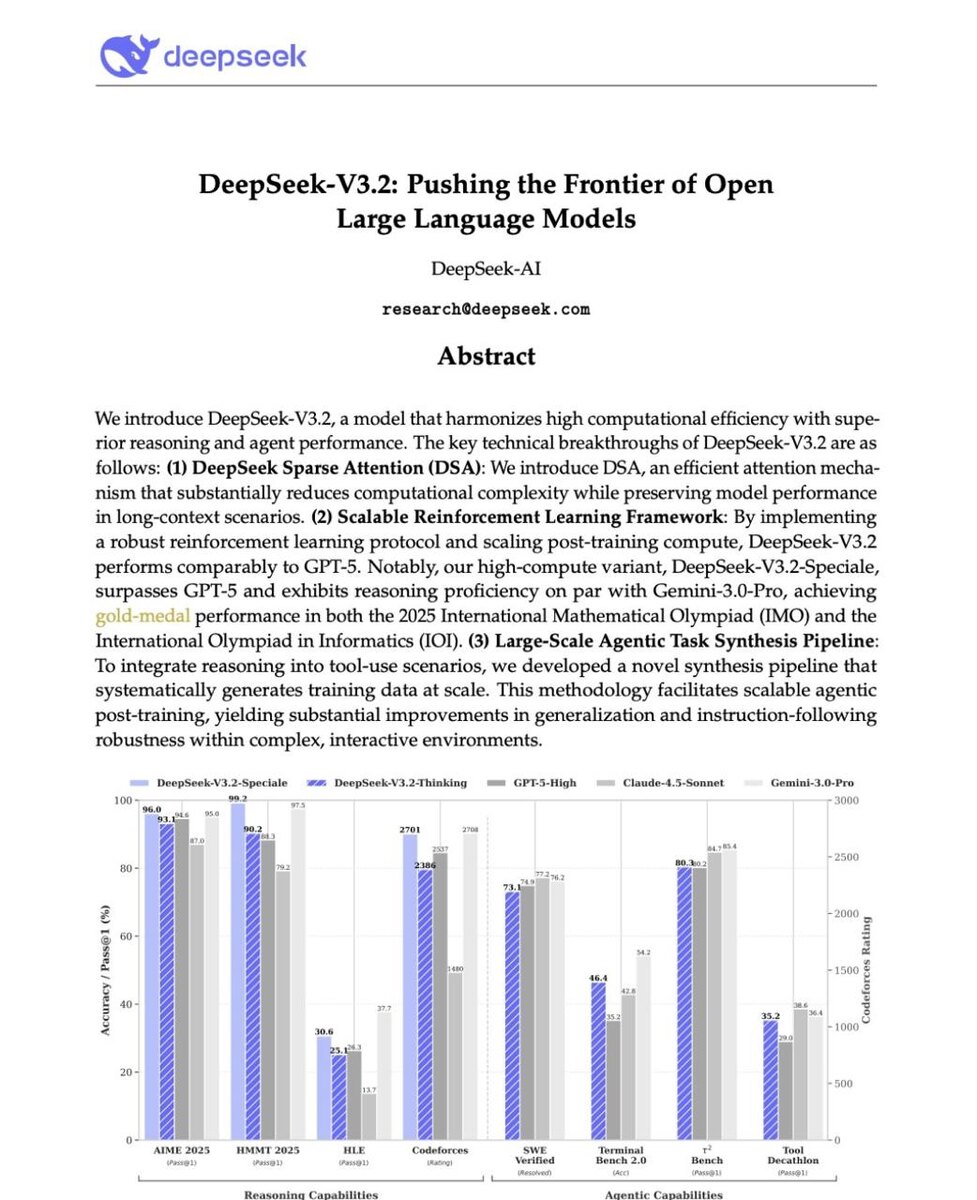
🐋 DeepSeek выкатили не «ещё одну модель», а полноценную топ-систему уровня IMO/IOI/ICPC - при этом обучение и генерация стоят в десятки раз дешевле, чем у GPT-5 и Gemini 3 Pro.
Главное:
• DeepSeek-V3.2-Speciale обгоняет Gemini 3.0 Pro в математике и коде
• Новая флагманская модель совмещает рассуждения + агентность
• Архитектура MoE из семейства V3.1 Terminus, контекст 128k
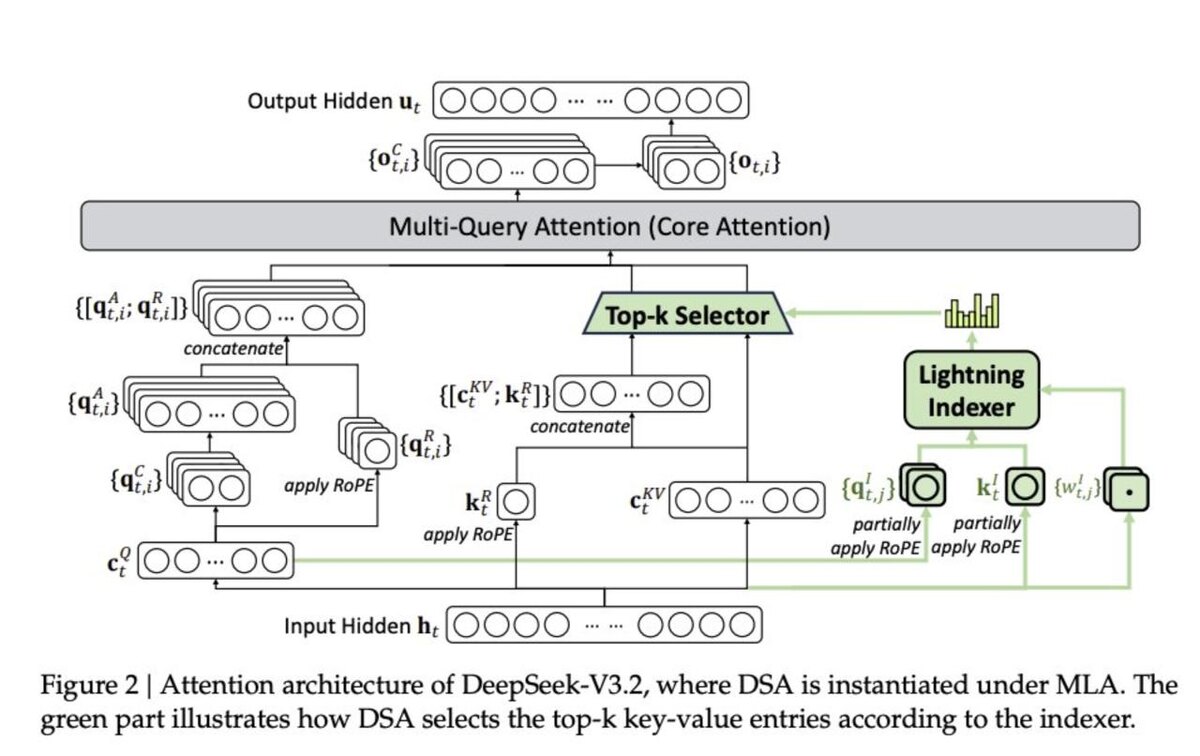
• Главное нововведение — DeepSeek Sparse Attention (DSA), сделанный ради дешёвого длинного контекста
Что делает DSA
Обычное внимание - O(T²), что больно при 128k токенов.
DSA снижает стоимость до O(T·U), где U - только небольшое число релевантных токенов.
Как работает:
1) Lightning Indexer - лёгкая сеть оценивает важность каждого прошлого токена
2) Fine-grained top-k - модель выбирает только самые полезные токены и считает внимание по ним
Как обучали
Начали с чекпоинта V3.1 (128k) и сделали 2-ступенчатое дообучение:
• Stage 1 - плотное внимание, замороженная модель, обучается только DSA
• Stage 2 - постепенный переход на DSA по всей модели
Итог: длинный контекст стал реально дешёвым, а качество выше, чем у предыдущих версий и конкурентов.
Tech report: https://huggingface.co/deepseek-ai/DeepSeek-V3.2/resolve/main/assets/paper.pdf