Традиционная сегментация («Женщины, 25-45 лет, доход средний») — это стрельба из пушки по воробьям. В 2026 году такой подход не просто устарел, он сжигает ваш бюджет.
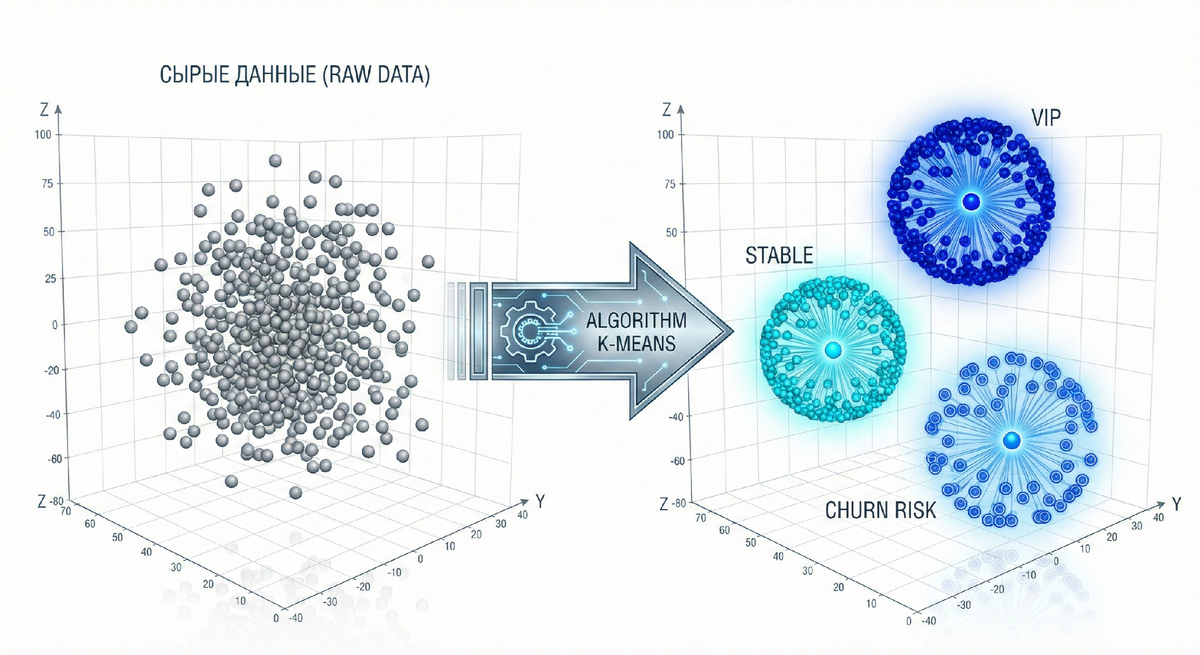
Пока конкуренты пытаются «понять» клиента через интуицию, мы решаем задачу математически. Мой выбор — K-means кластеризация. Это алгоритм машинного обучения без учителя, который находит скрытые паттерны в хаосе транзакций. Он не спрашивает, кто ваш клиент. Он смотрит, как он себя ведет.
Архитектура решения
Вместо ручной сортировки базы мы внедряем вычислительный узел, который анализирует клиентов по RFM-вектору (Recency, Frequency, Monetary). Представьте каждого клиента как точку в трехмерном пространстве. Алгоритм K-means автоматически находит центры притяжения (центроиды) и группирует людей вокруг них.
Кейс: Ритейл-архитектура В одном из проектов мы заменили веерные рассылки на кластерный таргетинг. Алгоритм выделил неочевидные группы:
- «Спящие киты» (High Value, Low Recency): Покупали много, но давно. Реакция системы: автоматическая отправка персонального оффера с высоким номиналом.
- «Охотники за скидками» (Low Value, High Frequency): Покупают часто, но только на распродажах. Реакция: исключение из кампаний с новинками (экономия бюджета).
Результат: Рост среднего чека (AOV) на 15% и снижение стоимости коммуникации.
Технический протокол внедрения
K-means — это мощный инструмент, но он требует гигиены данных. Вот мой чеклист инженера:
- Санитария данных (Data Sanitation). Алгоритм чувствителен к выбросам. Один клиент с чеком в миллион сломает кластеризацию для тысячи обычных покупателей. Мы чистим дубликаты и нормализуем данные перед загрузкой.
- Поиск числа «k» (Elbow Method). Не гадайте, сколько у вас сегментов. Используйте «Метод локтя». Стройте график и ищите точку изгиба — это и есть математически обоснованное количество кластеров.
- Масштабирование (Scaling). Частота покупок (число 1-10) и сумма покупок (число 1000-50000) имеют разный вес. Без скейлинга алгоритм будет игнорировать частоту. Мы приводим все к единому диапазону.
Вывод
Сегментация — это не разовая презентация в PowerPoint. Это динамический процесс. Рынок живой. В моей архитектуре пересчет кластеров происходит автоматически каждую неделю. Клиент перестал покупать? Система сама перекинет его из кластера «Лояльный» в кластер «Риск оттока» и запустит протокол удержания.
Перестаньте думать о клиентах. Начните их вычислять.
Хотите внедрить алгоритмический маркетинг? Подписывайтесь, здесь мы говорим на языке цифр и кода.