🚀 Uni-MoE-2.0-Omni - новый прорыв в омнимодальных моделях
Эта модель поднимает планку: от мультимодальности к полноценному омнимодальному пониманию и генерации: речь, текст, изображения, видео, аудио-видео взаимодействия.
✨ Главное нововведение
Разработчики показали, как эволюционно превратить обычные плотные LLM в эффективные MoE-модели, способные работать со всеми модальностями одновременно.
🧠 Архитектура
1️⃣ Omnimodality 3D RoPE + Dynamic Capacity MoE
- Унифицирует выравнивание речи, текста, изображений и видео в пространственно-временных измерениях
- Динамически распределяет вычисления в зависимости от сложности задачи
2️⃣ Глубоко слитый мультимодальный encoder-decoder
- Любые комбинации входных и выходных модальностей
- Настоящее омнимодальное взаимодействие и генерация
🛠️ Тренировка
1️⃣ Прогрессивная стратегия обучения
Cross-modal alignment → Warm-up экспертов → MoE + RL → Генеративное обучение
- Масштабирует плотные LLM в MoE-модели
- Всего 75B токенов
- Стабильная сходимость, особенно на RL
2️⃣ Языковая основа для задач понимания и генерации
- Все задачи сводятся к языковой генерации
- Пробивает барьеры между модальностями
🎨 Возможности
✔ Генерация и взаимодействие через речь
✔ Генерация и редактирование изображений
✔ Понимание изображений и видео
✔ Аудиовизуальное рассуждение
✔ 10+ мультимодальных задач
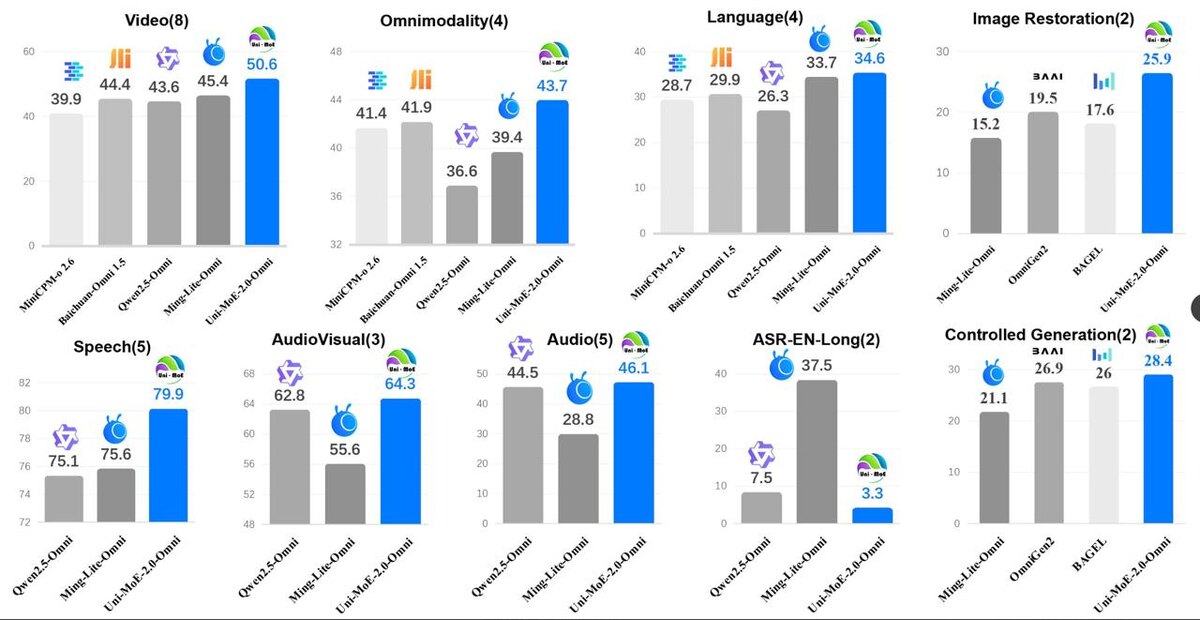
🔥 Результаты
Модель превзошла Qwen2.5-Omni (1.2T токенов) в 50+ из 76 задач, имея всего 75B токенов:
- Видео-понимание: +5%
- Омнимодальное понимание: +7%
- Speech QA: +4.3%
- Обработка изображений: +7%
🌍 Open Source
Model: https://huggingface.co/collections/HIT-TMG/lychee-uni-moe-20
Code: https://github.com/HITsz-TMG/Uni-MoE/tree/master/Uni-MoE-2
Homepage: https://idealistxy.github.io/Uni-MoE-v2.github.io/