
Аннотация
В статье проводится сравнительный анализ эффективности использования оператора JOIN и коррелированного подзапроса в СУБД PostgreSQL в условиях высокой параллельной нагрузки. На основе экспериментальных данных опровергаются универсальные рекомендации систем искусственного интеллекта и выявляются ключевые факторы, влияющие на производительность.
ℹ️ Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
1. Постановка задачи
Рассматривается вопрос выбора оптимального паттерна для выполнения запросов при высокой параллельной нагрузке на СУБД: использование JOIN или коррелированного подзапроса.
Были получены рекомендации от нейросетевых моделей:
- «Ask Postgres»: Для нагрузочных тестов с растущей параллельностью всегда используйте версию с JOIN. Коррелированные подзапросы с агрегациями — плохая практика в сценариях с высокой конкуренцией.
- «DeepSeek»: Для данного сценария производительность будет выше при использовании запроса с LEFT JOIN и GROUP BY.
2. Детали эксперимента
Полное описание эксперимента:
2.1. Тестовый запрос с использованием JOIN
SELECT
c.customer_id, COUNT(o.order_id) AS orders_count
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id
GROUP BY c.customer_id;
План выполнения
HashAggregate (cost=35.85..37.25 rows=140 width=12) (actual time=0.622..0.629 rows=25 loops=1)
Group Key: c.customer_id
Batches: 1 Memory Usage: 40kB
-> Hash Right Join (cost=13.15..30.85 rows=1000 width=8) (actual time=0.077..0.429 rows=1000 loops=1)
Hash Cond: (o.customer_id = c.customer_id)
-> Seq Scan on orders o (cost=0.00..15.00 rows=1000 width=8) (actual time=0.035..0.148 rows=1000 loops=1)
-> Hash (cost=11.40..11.40 rows=140 width=4) (actual time=0.028..0.028 rows=25 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on customers c (cost=0.00..11.40 rows=140 width=4) (actual time=0.018..0.021 rows=25 loops=1)
Planning Time: 0.221 ms
Execution Time: 0.787 ms
2.2. Тестовый запрос с использованием коррелированного подзапроса
SELECT c.customer_id,
(SELECT COUNT(o.order_id)
FROM orders o
WHERE o.customer_id = c.customer_id) AS orders_count
FROM customers c;
План выполнения
Seq Scan on customers c (cost=0.00..1015.20 rows=140 width=12) (actual time=0.093..0.614 rows=25 loops=1)
SubPlan 1
-> Aggregate (cost=7.16..7.17 rows=1 width=8) (actual time=0.023..0.023 rows=1 loops=25)
-> Bitmap Heap Scan on orders o (cost=1.56..7.06 rows=40 width=4) (actual time=0.007..0.017 rows=40 loops=25)
Recheck Cond: (customer_id = c.customer_id)
Heap Blocks: exact=125
-> Bitmap Index Scan on idx_orders_customer_id (cost=0.00..1.55 rows=40 width=0) (actual time=0.004..0.004 rows=40 loops=25)
Index Cond: (customer_id = c.customer_id)
Planning Time: 0.145 ms
Execution Time: 0.718 ms
2.3. Сравнение производительности СУБД в ходе нагрузочного тестирования
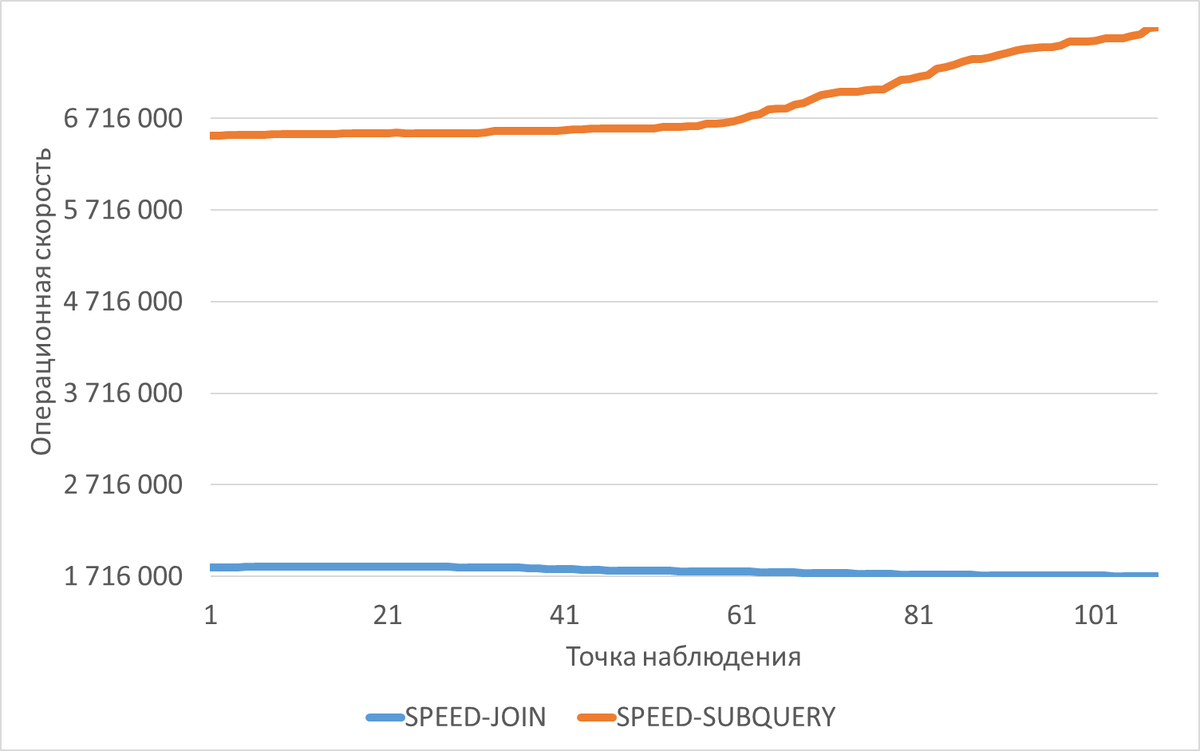
В ходе сравнительного нагрузочного тестирования была измерена операционная скорость СУБД при использовании оператора JOIN и коррелированного подзапроса. Согласно результатам, среднее снижение операционной скорости при использовании JOIN составило 288% по сравнению с коррелированным подзапросом.
3. Анализ причин некорректности рекомендаций нейросетей
3.1. Применение статических эвристик вместо анализа плана выполнения
Нейросети опираются на общие рекомендации, такие как:
- «JOIN обычно эффективнее подзапросов»;
- «Избегайте N+1 запросов»;
- «Коррелированные подзапросы плохо масштабируются».
Однако они не анализируют конкретные планы выполнения запросов в условиях высокой нагрузки и конкуренции за ресурсы.
3.2. Игнорирование паттернов доступа к данным
Анализ планов выполнения показал:
- Запрос 1 (JOIN): Seq Scan on orders (полное сканирование таблицы).
- Запрос 2 (Подзапрос): Bitmap Index Scan on idx_orders_customer_id (точечный доступ по индексу).
При параллельных соединениях:
- Количество сессий × Seq Scan = количество полных сканирований таблицы orders.
- Количество сессий × Index Scan = равномерно распределенная нагрузка на чтение.
3.3. Неучёт механизмов блокировки и конфликтов ресурсов
- Проблема JOIN при высокой конкуренции: Все сессии одновременно читают одни и те же страницы таблицы orders, что вызывает конфликт ресурсов (contention) на буферный кэш и подсистему ввода-вывода.
- Преимущество подзапроса: Каждая сессия работает с разными частями индекса, что снижает конкуренцию за блокировки и улучшает параллелизм.
3.4. Разный профиль использования памяти
- JOIN: Memory Usage: 40 kB + хэш-таблица.
- Подзапрос: Точечное использование памяти для каждого клиента.
При множественных сессиях JOIN создает значительную нагрузку на shared_buffers.
4. Критические факторы, упускаемые нейросетями
- Влияние на shared_buffers: Множественные последовательные сканирования вытесняют полезные данные из кэша.
- Lock contention: Конкуренция за одни и те же ресурсы (блокировки).
- Распределение операций ввода-вывода: Индексные чтения лучше распределены.
- Параметры PostgreSQL: Значения work_mem, shared_buffers, random_page_cost и других настроек существенно влияют на результат.
5. Причины ошибок в рекомендациях нейросетевых моделей
Нейросети обучаются на синтетических или упрощённых данных, для которых характерны:
- Небольшой объём наборов данных (TPC-H, TPC-DS).
- Низкая параллельность запросов (1–10 соединений).
- Идеализированные индексы.
- Отсутствие блокировок и конкуренции за ресурсы (ЦП, ввод-вывод).
В результате модель вырабатывает универсальное правило «JOIN всегда лучше», которое не работает в реальных условиях высокой конкуренции.
6. Заключение
Рекомендации, сгенерированные нейросетями, основаны на общих эвристиках и не могут учитывать всех особенностей конкретной эксплуатационной среды. Они не заменяют глубокого анализа планов выполнения запросов и понимания архитектуры СУБД под нагрузкой. Проведенный эксперимент наглядно демонстрирует важность практического тестирования и невозможность слепого следования автоматизированным советам.