
Искусственный интеллект сегодня — это соблазнительный ключ к решению многих задач. Но когда дело доходит до тонкой настройки высоконагруженной СУБД PostgreSQL, этот ключ может оказаться отмычкой, ломающей весь механизм. Нейросети, обученные на миллионах текстовых примеров, способны генерировать правдоподобные SQL-советы, но они не несут ответственности за результат и, что главное, не понимают реальной стоимости запросов в условиях острой конкуренции за ресурсы.
В этой статье разбирается фатальная рекомендация нейросети, которая привела не к ускорению, а к полномасштабной деградации системы. На примере кейса со слепой заменой коррелированного подзапроса на JOIN будет показано : в highload-мире слепая вера в нейросеть — это прямой путь к проблемам с производительностью СУБД под нагрузкой .
ℹ️Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
Кейс "JOIN vs Коррелированный подзапрос"
Вопрос
Какой паттерн выгоднее использовать при высокой параллельной нагрузке на СУБД - JOIN или коррелированный подзапрос ?
Предпосылки , постановка и детали эксперимента :
1️⃣ Рекомендация нейросети "Ask Postgres"
Для нагрузочных тестов с растущей параллельностью всегда используйте JOIN-версию (запрос-1).
Коррелированные подзапросы с агрегациями — плохая практика в сценариях с высокой конкуренцией, даже если они выглядят «проще».
2️⃣ Рекомендация нейросети "DeepSeek"
Для данного сценария нагрузочного тестирования производительность будет выше при использовании тестового запроса-1 (с LEFT JOIN и GROUP BY).
💣Результат эксперимента - "нагрузочное тестирование СУБД с использованием JOIN и коррелированного подзапроса"
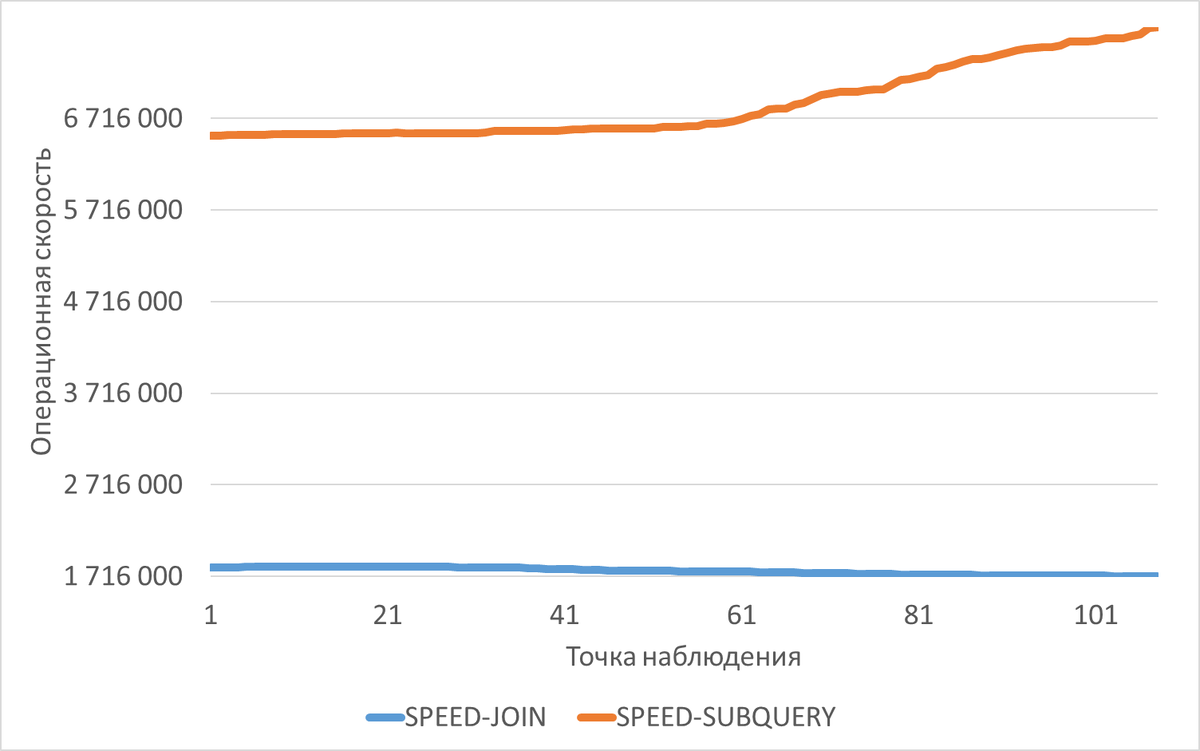
💥Среднее снижение операционной скорости при использовании JOIN составило 288%
⚠️Причины некорректной рекомендации нейросетей для случая "JOIN vs коррелированный подзапрос"
1. Статические эвристики вместо анализа конкретного плана
Нейросети обучаются на общих рекомендациях типа:
- "JOIN обычно эффективнее подзапросов"
- "Избегайте N+1 запросов"
- "Коррелированные подзапросы плохо масштабируются"
Но они не анализируют конкретные планы выполнения в условиях высокой нагрузки и конкуренции за ресурсы .
2. Игнорирование паттернов доступа к данным
- Запрос 1 (JOIN): Seq Scan on orders (чтение всей таблицы)
- Запрос 2 (Подзапрос): Bitmap Index Scan on idx_orders_customer_id (точечный доступ)
При параллельных соединениях :
- Количество сессий × Seq Scan = количество чтений всей таблицы orders.
- Количество сессий × Index Scan = равномерное распределение нагрузки на чтение.
3. Непонимание механизмов блокировки и конфликта ресурсов
Проблема JOIN при высокой конкуренции:
- Все сессии одновременно читают одни и те же страницы orders
- Возникает конфликт ресурсов(contention) на буферный кэш и I/O
Преимущество подзапроса:
- Каждая сессия работает с разными частями индекса
- Меньше блокировок, лучше параллелизм
4. Разный профиль использования памяти
- JOIN: Memory Usage: 40kB + хэш-таблица
- Подзапрос: Точечное использование памяти для каждого клиента
При множественных сессиях JOIN создает большую нагрузку на shared buffers.
Почему подзапрос выигрывает:
Анализ данных:
- customers: 25 строк
- orders: 1000 строк
- Соотношение: ~40 заказов на клиента
- Индекс: idx_orders_customer_id эффективно используется
При росте нагрузки:
5 сессий:
JOIN - 5 полных сканирований orders
Подзапрос - 5 × 25 = 125 индексных сканирований
20 сессий:
JOIN - 20 полных сканирований orders (высокий contention)
Подзапрос - 20 × 25 = 500 индексных сканирований (лучше распределение)
⚠️Что упускают нейросети:
- Влияние на shared buffers: Множественные Seq Scan вытесняют кэш
- Lock contention: Конкуренция за одни и те же ресурсы
- Распределение I/O: Индексные чтения лучше распределены
- Параметры PostgreSQL: work_mem, shared_buffers, random_page_cost
⚠️Почему нейросеть может ошибочно рекомендовать «JOIN всегда лучше»?
Обучение на синтетических или упрощённых данных
Многие модели машинного обучения для оптимизации SQL обучаются на:
- в наборах данных небольшого объёма (например, TPCH, TPC-DS),
- при запросах с низкой параллельностью (1–10 соединений)
- идеальными индексами,
- отсутствие блокировок, конкуренции за ЦП/Ввод-вывод.
Результат: модель видит, что JOIN в этих условиях работает быстро, и обобщает это как универсальное правило.
Вывод
Нейросети дают общие рекомендации, но не заменяют анализ конкретных планов выполнения и понимание архитектуры СУБД под нагрузкой. Пример прекрасно это демонстрирует.
—————————————————
Дополнительно : "Index Only Scan" vs "Bitmap Index Scan" : 👉неоднозначная рекомендация.
Предпосылки , постановка и детали эксперимента :
1️⃣ Рекомендация нейросети "Ask Postgres"
1. Создать покрывающий индекс (Covering Index)
Замените текущий индекс на составной индекс, включающий bid и abalance:
DROP INDEX pgbench_test_idx;
CREATE INDEX pgbench_test_bid_abalance_idx ON pgbench_test (bid, abalance);
2️⃣ Рекомендация нейросети "DeepSeek"
Результат эксперимента -"нагрузочное тестирование СУБД с использованием Index Only Scan vs Bitmap Index Scan"
Сравнение операционной скорости в Эксперимент-2(обычный индекс) и Эксперимент-3(покрывающий индекс)
Результаты
- До нагрузки 15 соединений, производительность СУБД, при использовании покрывающего индекса(эксперимент-3) ниже производительности СУБД с использованием простого индекса (эксперимент-2) в среднем на 7%.
- С ростом нагрузки, после 15 соединений, производительность СУБД при использовании покрывающего индекса(эксперимент-3) выше производительности СУБД с использованием простого индекса (эксперимент-2) в среднем на 22%.
Причины неоднозначных рекомендаций нейросетей для оптимизации индексов в отличии от экспертной оценки.
1. Статистическая природа LLM vs. Детерминированные знания
- LLM работают на основе статистических закономерностей в тренировочных данных, а не на реальном понимании
- Эксперт опирается на системные знания архитектуры СУБД и принципов работы индексов
2. Поверхностное понимание контекста
Нейросети часто:
- Улавливают ключевые слова ("индекс", "производительность", "SELECT")
- Выдают обобщенные ответы без учета нюансов
- Не могут провести причинно-следственный анализ
3. Отсутствие практического опыта
LLM не имеют:
- Опыта нагрузочного тестирования реальных систем
- Понимания, как планировщик PostgreSQL принимает решения
- Знания о внутреннем устройстве B-деревьев и механизмов блокировок
Почему данный кейс особенно сложен:
Скрытые переменные:
- Соотношение операций чтения/записи в тесте
- Размер таблицы и селективность данных
- Настройки autovacuum и статистики
- Размер shared_buffers и работа с кэшем
Что отличает экспертный ответ:
- Признание неоднозначности - честный ответ "зависит от..."
- Перечисление условий - явное указание, когда производительность увеличится, а когда уменьшится
- Практические рекомендации - совет протестировать на реальных данных
- Глубина анализа - рассмотрение не только прямых, но и косвенных эффектов
⚠️Вывод
Случай попадает в "слепую зону" современных LLM - область, где требуется:
- Глубокие предметные знания
- Способность к системному мышлению
- Понимание компромиссов и скрытых затрат
- Практический опыт работы со сложными системами
Идеальный ответ на такой вопрос должен признавать свою ограниченность и рекомендовать обращение к документации и реальному тестированию, а не давать однозначные, но потенциально неверные утверждения.
ℹ️Общий итог
Для реального, практического применения в условиях высокой нагрузки и конкуренции за ресурсы СУБД - рекомендации нейросетей в лучшем случае слабо применимы и носят справочно-рекомендательный характер, в крайнем случае приводят к деградации производительности СУБД.
Использовать нейросети для оптимизации СУБД под высокой нагрузкой - не рекомендуется.