
Перед тем как запустить Screaming Frog, я всегда уделяю минуту базовым настройкам.
С годами у меня выработался свой небольшой список параметров — не универсальный, но проверенный десятками аудитов. Это базовые настройки, с которых я начинаю первичное знакомство с сайтом: они помогают быстро собрать общую картину структуры, ссылок и технических проблем.
Конечно, всё зависит от задачи. Если нужен глубокий аудит — подключаю JavaScript-рендеринг, настраиваю скорость, добавляю API-интеграции или отдельные проверки структурированных данных и так далее.
Но для первичного скана я почти всегда использую один и тот же набор — минимальный, но дающий чёткое понимание, в каком состоянии может находится сайт.
1. Включаю опцию Crawl All Subdomains
Путь: Configuration → Spider → Crawl → Crawl All Subdomains
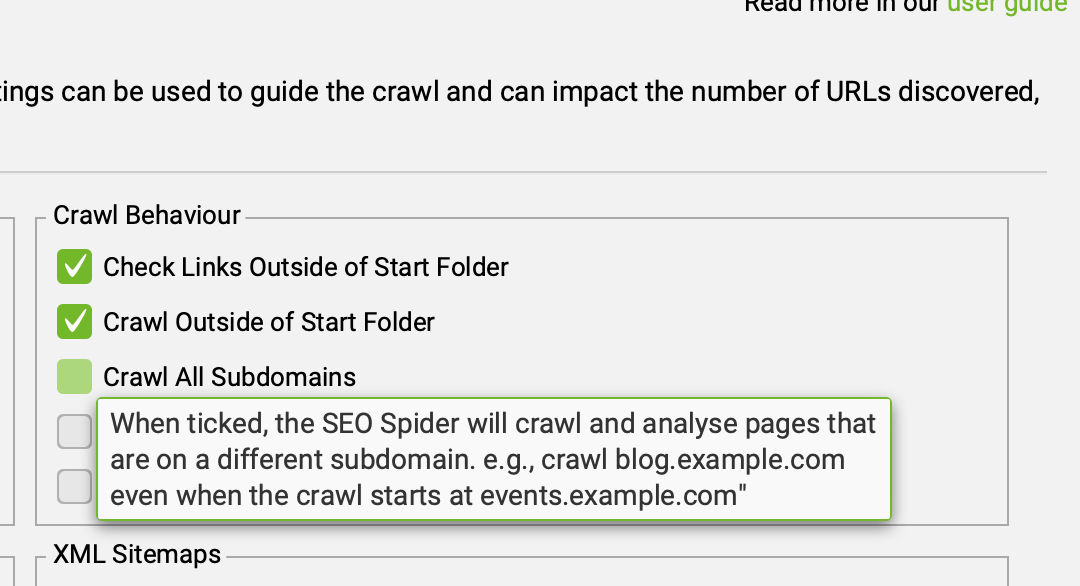
Эта настройка позволяет пауку проходить не только основной домен, но и все поддомены, которые встречаются на сайте — например, blog.site.ru, shop.site.ru или test.site.ru.
Почему это важно:
Поддомены часто содержат части проекта, которые напрямую влияют на SEO — блог, лендинги, мультирегиональные версии, старые каталоги. Если не включить эту галочку, Screaming Frog обойдёт их стороной, и вы получите неполную картину структуры сайта.
Ещё один плюс — инструмент помогает обнаружить тестовые или архивные поддомены, если на них остались внутренние или внешние ссылки. Такое бывает чаще, чем кажется: сайт переехал, а старая версия продолжает «жить» где-то на dev. или old..
Из опыта: именно там часто прячутся дубли, редиректы и утерянные страницы, которые всё ещё видят поисковики. Поэтому я всегда начинаю скан с включённым Crawl All Subdomains — чтобы видеть весь проект целиком.
2. Включаю опцию Follow Internal “nofollow”
Путь: Configuration → Spider → Crawl → Follow Internal “nofollow”
По умолчанию Screaming Frog игнорирует ссылки, помеченные атрибутом rel="nofollow". Но внутри сайта такие ссылки могут вечти на важные страницы — просто когда-то кто-то поставил nofollow «на всякий случай» или по совету разработчика либо просто забыли снять при выкатке сайта на бой.
Включение этой галочки говорит пауку: «идти дальше» даже по внутренним nofollow-ссылкам. Это помогает увидеть всю реальную структуру сайта, включая разделы, на которые могли забыть снять ограничение.
На практике это часто выручает при аудитах крупных проектов — особенно если структура формировалась годами, а правила линковки менялись. Так можно найти изолированные страницы, которые поисковик мог не видеть из-за nofollow, но которые продолжают быть частью навигации или меню.
3. Включаю опцию Follow External “nofollow”
Путь: Configuration → Spider → Crawl → Follow External “nofollow”
Эта настройка позволяет Screaming Frog переходить по внешним ссылкам, даже если они помечены rel="nofollow".
Зачем это нужно:
Иногда такие ссылки ведут на важные партнёрские сайты, дополнительные домены компании или старые внешние ресурсы, где всё ещё остались связи с брендом. Также с помощью этой настройки можно найти ссылки на сомнительные источники.
Особенно полезно включать эту опцию, если вы делаете глубокий технический аудит или чистите ссылочное окружение проекта (исходящие для уменьшения уровня спама). Screaming Frog покажет, куда реально ведут все внешние ссылки, и поможет найти лишние или «утекшие» nofollow-ссылки, которые когда-то остались в шаблонах.
4. Включаю опцию Crawl Linked XML Sitemaps
Путь: Configuration → Spider → Crawl → Crawl Linked XML Sitemaps
Эта настройка позволяет Screaming Frog автоматически находить и сканировать все XML-карты сайта, чтобы сверить их с реальной структурой.
Здесь есть два уровня настройки:
- Автоматический поиск — бот сам находит карты, если они указаны в robots.txt (например, Sitemap: https://site.ru/sitemap.xml).
- Ручное добавление — можно задать конкретные адреса sitemap-файлов через соответствующее окно.
Почему это важно:
XML-sitemap показывает страницы, которые сайт рекомендует для индексации. Часто они не связаны внутренними ссылками, но остаются в структуре сайта. Без этой опции Screaming Frog может их просто не увидеть — и получится неполная картина.
Я всегда включаю Crawl Linked XML Sitemaps, чтобы сопоставить заявленное в sitemap и фактическое на сайте. Это помогает быстро находить несуществующие, устаревшие или недоступные страницы, которые всё ещё прописаны в карте сайта.
5. Включаю Ignore robots.txt, но оставляю отчёт по блокировкам
Путь: Configuration → Robots.txt → Settings → Ignore robots.txt but report status
Я часто включаю Ignore robots.txt, чтобы Screaming Frog просканировал весь сайт без ограничений и помог найти скрытые страницы, на которые всё ещё ведут ссылки.
При этом опцию Report “Blocked by Robots.txt” обязательно оставляю активной — она фиксирует, какие страницы были бы заблокированы, если бы робот следовал правилам.
В результате получается двойная польза:
- бот проходит по всем ссылкам, даже если они закрыты в robots.txt;
- в отчётах видно, какие URL формально запрещены, но продолжают быть частью структуры.
Так часто удаётся найти старые страницы, тестовые поддомены или лендинги, которых нет в sitemap, но на них до сих пор ведут ссылки с действующих страниц ну или просто страницы, которые закрыли от сканирования.
6. Ставлю User-Agent: Googlebot
Путь: Configuration → User-Agent → Googlebot
Перед запуском скана я почти всегда меняю User-Agent на Googlebot (ну или другого бота поисковых систем).
Это позволяет увидеть сайт так, как его видит поисковик, а не как стандартный бот Screaming Frog.
Зачем это нужно:
Некоторые сайты отдают разный контент в зависимости от User-Agent — могут прятать часть элементов, подгружать другие версии страниц или блокировать бота полностью на стороне сервера.
Если оставить дефолтный Screaming Frog, можно получить искажённую картину: одни страницы покажутся «пустыми», другие — вовсе недоступными.
Итог
Каждый SEO-аудит начинается с мелочей. Правильно настроенный Screaming Frog экономит часы работы и показывает сайт таким, какой он есть на самом деле — со всеми поддоменами, закрытыми страницами и забытыми ссылками.
Этот набор — мой стартовый минимум. Простые галочки, которые помогают быстро понять архитектуру проекта и увидеть, с чего стоит начинать глубокий анализ.
А дальше уже подключаю всё остальное: рендеринг, API, структурированные данные — когда сайт того требует. Но без этой базы я не запускаю ни одно сканирование.
А без каких настроек Screaming Frog вы не запускаете сканирование ваших проектов?