
Эффективное нагрузочное тестирование СУБД — это не только о том, «сколько запросов в секунду», но и о том, «на каких данных». Инструменты PG_EXPECTO 4 и Демобаза 2.0 выводят процесс подготовки тестовой среды на новый уровень. В статье мы покажем, как быстро развернуть сложную базу с настроенными размерами таблиц, индексами и связями, чтобы ваши тесты говорили правду о реальной производительности системы.
ℹ️Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
Задача
Настроить комплекс pg_expecto для использования в качестве тестовой базы нагрузочного тестирования любой , заранее подготовленной базы данных.
Тестовая база данных
Вместо старых статичных таблиц мы построили генератор, имитирующий жизнь глобальной авиакомпании.
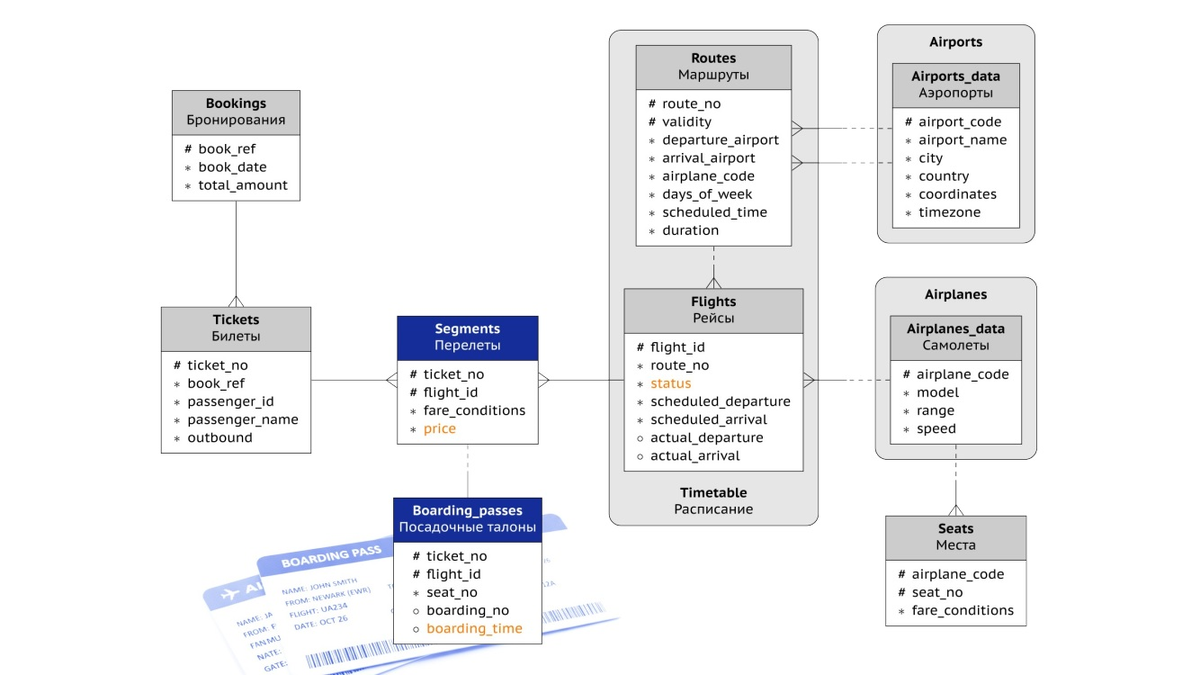
Шаг 1 - инсталляция демобазы
Подключитесь в psql к любой базе, кроме demo, убедитесь, что находитесь в каталоге репозитория, и выполните установку:
\! pwd
\i install
При необходимости смените текущий каталог командой \cd.
В ходе установки будет заново создана база данных demo. Если она существовала, то все данные в ней будут потеряны! В этой базе данных будут созданы две схемы: gen для объектов генератора и bookings для создаваемой демобазы.
Устанавливаются расширения btree_gist (для реализации темпорального ключа), earthdistance и cube (для расчета расстояний на сфере), а также dblink (для запуска параллельных процессов). Эти расширения входят в стандартный набор, но убедитесь, что они присутствуют в вашей установке PostgreSQL.
Генерация запускается процедурой generate, которой передаются начальное и конечное модельное время (которое будет фигурировать в таблицах демобазы). Например:
CALL generate( now(), now() + interval '2 year' );
Такая команда выполнит необходимую инициализацию, создаст очередь событий и начнет генерацию демобазы за один год.
Тестовая БД
demo=# SELECT count(*) num_bookings, min(book_date) book_date_from, max(book_date) book_date_to FROM bookings.bookings;
num_bookings | book_date_from | book_date_to
--------------+-------------------------------+-------------------------------
6412184 | 2023-11-11 14:27:52.488416+00 | 2025-03-18 23:53:51.299513+00
(1 row)
demo=# \l+ demo
List of databases
Name | Owner | Encoding | Locale Provider | Collate | Ctype | Locale | ICU Rules | Access privileges | Size | Tablespace | Description
------+----------+----------+-----------------+------------+------------+--------+-----------+-------------------+-------+------------+-------------
demo | postgres | UTF8 | icu | ru_RU.utf8 | ru_RU.utf8 | ru-RU | | | 12 GB | pg_default |
(1 row)
Шаг 2 - конфигурирование нагрузочного тестирования
Тестовый сценарий-1 : Простой SELECT по первичному ключу.
-- scenario1.sql
-- version 4.0
-- Простой точечный SELECT по первичному ключу.
CREATE OR REPLACE FUNCTION scenario2() RETURNS integer AS $$
DECLARE
test_rec record ;
test_code text ;
BEGIN
SET application_name = 'scenario1';
SELECT
array_to_string(array(select substr('ABCDEFGHIJKLMNOPQRSTUVWXYZ',((random()*(26-1)+1)::integer),1) from generate_series(1,3)),'')
INTO
test_code ;
SELECT
*
INTO
test_rec
FROM
airports_data
WHERE
airport_code = test_code ;
return 0 ;
END
$$ LANGUAGE plpgsql;
План выполнения тестового запроса
Index Scan using airports_data_pkey on airports_data (cost=0.28..2.50 rows=1 width=190) (actual time=0.027..0.028 rows=1 loops=1)
Index Cond: (airport_code = 'CBB'::bpchar)
Planning Time: 0.473 ms
Execution Time: 0.047 ms
Тестовый сценарий-2 : Запрос с GROUP BY и хэш-агрегацией.
-- scenario2.sql
-- version 4.0
-- Запрос с GROUP BY и хэш-агрегацией.
CREATE OR REPLACE FUNCTION scenario3() RETURNS integer AS $$
DECLARE
test_rec record ;
BEGIN
SET application_name = 'scenario2';
WITH empty_flights AS
(
SELECT f.flight_id, count( bp.flight_id )
FROM bookings.flights f
LEFT JOIN bookings.boarding_passes bp ON bp.flight_id = f.flight_id
WHERE f.status IN ( 'Departed', 'Arrived' )
GROUP BY f.flight_id
HAVING count( bp.flight_id ) = 0
)
SELECT count(*) empty,
CASE WHEN count(*) > 0 THEN 'WARNING: empty cabin' ELSE 'Ok' END verdict
INTO test_rec
FROM empty_flights;
return 0 ;
END
$$ LANGUAGE plpgsql;
План выполнения тестового запроса
Aggregate (cost=154.97..154.98 rows=1 width=32) (actual time=1.664..1.666 rows=1 loops=1)
-> HashAggregate (cost=150.91..154.94 rows=1 width=60) (actual time=1.662..1.664 rows=0 loops=1)
Group Key: f.flight_id
Batches: 1 Memory Usage: 24kB
-> Nested Loop (cost=0.42..149.77 rows=227 width=4) (actual time=1.661..1.662 rows=0 loops=1)
-> Nested Loop (cost=0.14..143.49 rows=1 width=8) (actual time=1.661..1.661 rows=0 loops=1)
-> Seq Scan on flights f (cost=0.00..141.11 rows=1 width=19) (actual time=1.660..1.661 rows=0 loops=1)
Filter: (status = ANY ('{Departed,Arrived}'::text[]))
Rows Removed by Filter: 6747
-> Index Scan using routes_route_no_validity_excl on routes r (cost=0.14..2.36 rows=1 width=33) (never executed)
Index Cond: ((route_no = f.route_no) AND (validity @> f.scheduled_departure))
-> Index Only Scan using seats_pkey on seats s (cost=0.28..4.11 rows=218 width=4) (never executed)
Index Cond: (airplane_code = r.airplane_code)
Heap Fetches: 0
SubPlan 1
-> Aggregate (cost=4.02..4.03 rows=1 width=8) (never executed)
-> Index Only Scan using segments_flight_id_idx on segments s_1 (cost=0.30..3.83 rows=76 width=0) (never executed)
Index Cond: (flight_id = f.flight_id)
Heap Fetches: 0
Planning Time: 3.750 ms
Execution Time: 1.934 ms
Тестовый сценарий-3 : Запрос с ORDER BY ... LIMIT
-- scenario3.sql
-- version 4.0
-- Запросы с ORDER BY ... LIMIT N
CREATE OR REPLACE FUNCTION scenario4() RETURNS integer AS $$
DECLARE
test_rec record ;
test_limit integer ;
BEGIN
SET application_name = 'scenario3';
SELECT random() * 1000 + 1
INTO
test_limit ;
SELECT a.airplane_code, a.model->>'en' AS model,
count(DISTINCT r.route_no) AS no_flights,
CASE
WHEN count(DISTINCT r.route_no) > 0 AND a.in_use THEN 'Ok'
WHEN count(DISTINCT r.route_no) = 0 AND a.in_use THEN 'NOT USED'
WHEN count(DISTINCT r.route_no) > 0 AND NOT a.in_use THEN 'WRONGLY USED'
WHEN count(DISTINCT r.route_no) = 0 AND NOT a.in_use THEN 'Ok (not in use)'
END AS verdict
INTO test_rec
FROM bookings.routes r
RIGHT JOIN gen.airplanes_data a ON a.airplane_code = r.airplane_code
GROUP BY a.airplane_code, a.model, a.in_use
ORDER BY a.airplane_code
LIMIT test_limit ;
return 0 ;
END
$$ LANGUAGE plpgsql;
План выполнения тестового запроса
Limit (cost=90.62..98.30 rows=20 width=140) (actual time=3.636..4.012 rows=10 loops=1)
-> GroupAggregate (cost=90.62..98.30 rows=20 width=140) (actual time=3.635..4.010 rows=10 loops=1)
Group Key: a.airplane_code, a.model, a.in_use
-> Sort (cost=90.62..92.07 rows=578 width=75) (actual time=3.602..3.643 rows=580 loops=1)
Sort Key: a.airplane_code, a.model, a.in_use, r.route_no
Sort Method: quicksort Memory: 79kB
-> Hash Right Join (cost=1.23..24.95 rows=578 width=75) (actual time=0.077..0.439 rows=580 loops=1)
Hash Cond: (r.airplane_code = a.airplane_code)
-> Seq Scan on routes r (cost=0.00..15.78 rows=578 width=11) (actual time=0.024..0.154 rows=578 loops=1)
-> Hash (cost=1.10..1.10 rows=10 width=68) (actual time=0.047..0.048 rows=10 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on airplanes_data a (cost=0.00..1.10 rows=10 width=68) (actual time=0.038..0.040 rows=10 loops=1)
Planning Time: 0.414 ms
Execution Time: 4.104 ms
(14 rows)
Тестовый сценарий-4 : Запрос с JOIN через хэш
-- scenario4.sql
-- version 4.0
-- Запросы с JOIN через хэш
CREATE OR REPLACE FUNCTION scenario5() RETURNS integer AS $$
DECLARE
test_rec record ;
BEGIN
SET application_name = 'scenario4';
WITH seats_available AS
( SELECT airplane_code, fare_conditions, count( * ) AS seats_cnt
FROM bookings.seats
GROUP BY airplane_code, fare_conditions
), seats_booked AS
( SELECT flight_id, fare_conditions, count( * ) AS seats_cnt
FROM bookings.segments
GROUP BY flight_id, fare_conditions
), overbook AS (
SELECT f.flight_id, r.route_no, r.airplane_code, sb.fare_conditions,
sb.seats_cnt AS seats_booked,
sa.seats_cnt AS seats_available
FROM bookings.flights AS f
JOIN bookings.routes AS r ON r.route_no = f.route_no AND r.validity @> f.scheduled_departure
JOIN seats_booked AS sb ON sb.flight_id = f.flight_id
JOIN seats_available AS sa ON sa.airplane_code = r.airplane_code
AND sa.fare_conditions = sb.fare_conditions
WHERE sb.seats_cnt > sa.seats_cnt
)
SELECT count(*) overbookings,
CASE WHEN count(*) > 0 THEN 'ERROR: overbooking' ELSE 'Ok' END verdict
INTO test_rec
FROM overbook;
return 0 ;
END
$$ LANGUAGE plpgsql;
План выполнения тестового запроса
Aggregate (cost=9825.94..9825.95 rows=1 width=40) (actual time=262.702..262.707 rows=1 loops=1)
-> Hash Join (cost=9431.95..9825.94 rows=1 width=0) (actual time=262.696..262.701 rows=0 loops=1)
Hash Cond: ((f.route_no = r.route_no) AND (seats.airplane_code = r.airplane_code))
Join Filter: (r.validity @> f.scheduled_departure)
Rows Removed by Join Filter: 217
-> Nested Loop (cost=9407.50..9796.79 rows=567 width=19) (actual time=218.641..259.306 rows=11355 loops=1)
-> Hash Join (cost=9407.22..9623.25 rows=567 width=8) (actual time=218.539..235.320 rows=11355 loops=1)
Hash Cond: (segments.fare_conditions = seats.fare_conditions)
Join Filter: ((count(*)) > (count(*)))
Rows Removed by Join Filter: 66545
-> HashAggregate (cost=9366.21..9507.87 rows=14166 width=20) (actual time=217.266..219.770 rows=10888 loops=1)
Group Key: segments.flight_id, segments.fare_conditions
Batches: 1 Memory Usage: 1425kB
-> Seq Scan on segments (cost=0.00..6654.55 rows=361555 width=12) (actual time=0.071..90.350 rows=361489 loops=1)
-> Hash (cost=40.71..40.71 rows=24 width=20) (actual time=1.228..1.230 rows=20 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 10kB
-> HashAggregate (cost=40.47..40.71 rows=24 width=20) (actual time=1.205..1.211 rows=20 loops=1)
Group Key: seats.airplane_code, seats.fare_conditions
Batches: 1 Memory Usage: 24kB
-> Seq Scan on seats (cost=0.00..27.41 rows=1741 width=12) (actual time=0.059..0.420 rows=1741 loops=1)
-> Index Scan using flights_pkey on flights f (cost=0.28..0.31 rows=1 width=19) (actual time=0.002..0.002 rows=1 loops=11355)
Index Cond: (flight_id = segments.flight_id)
-> Hash (cost=15.78..15.78 rows=578 width=33) (actual time=0.631..0.632 rows=578 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 45kB
-> Seq Scan on routes r (cost=0.00..15.78 rows=578 width=33) (actual time=0.083..0.375 rows=578 loops=1)
Planning Time: 5.779 ms
Execution Time: 263.774 ms
Изменить конфигурационный файл param.conf
cd /postgres/pg_expecto/sh/load_test
# НАСТРОЙКИ НАГРУЗОЧНОГО ТЕСТИРОВАНИЯ
# Максимальная нагрузка
finish_load = 20
# Тестовая БД
#testdb = default
testdb = demo
# Веса сценариев
scenario1 = 1.0
scenario2 = 1.0
scenario3 = 1.0
scenario4 = 1.0
Шаг 3 - старт нагрузочного тестирования
cd /postgres/pg_expecto/sh/load_test
./load_test_start.sh
TIMESTAMP : 13-11-2025 09:03:29 : OK : НОВЫЙ НАГРУЗОЧНЫЙ ТЕСТ
TIMESTAMP : 13-11-2025 09:03:29 : OK : МАКСИМАЛЬНАЯ НАГРУЗКА = 20 СЕССИЙ
TIMESTAMP : 13-11-2025 09:03:29 : OK : ТЕСТОВАЯ БД = demo
TIMESTAMP : 13-11-2025 09:03:29 : OK : ТЕСТОВАЯ БД НАГРУЗОЧНОГО ТЕСТИРОВАНИЯ = demo
TIMESTAMP : 13-11-2025 09:03:29 : OK : ВЛАДЕЛЕЦ ТЕСТОВОЙ БД = postgres
TIMESTAMP : 13-11-2025 09:03:29 : OK : BEFORE_START.SQL
TIMESTAMP : 13-11-2025 09:03:29 : OK : СОЗДАТЬ ФУНКЦИЮ ДЛЯ СЦЕНАРИЯ-1
TIMESTAMP : 13-11-2025 09:03:29 : OK : СОЗДАТЬ СКРИПТ ВЫЗОВА СЦЕНАРИЯ-1
TIMESTAMP : 13-11-2025 09:03:29 : OK : СЦЕНАРИЙ-1 ВЕС = 1.0
TIMESTAMP : 13-11-2025 09:03:29 : OK : СОЗДАТЬ ФУНКЦИЮ ДЛЯ СЦЕНАРИЯ-2
TIMESTAMP : 13-11-2025 09:03:29 : OK : СОЗДАТЬ СКРИПТ ВЫЗОВА СЦЕНАРИЯ-2
TIMESTAMP : 13-11-2025 09:03:29 : OK : СЦЕНАРИЙ-2 ВЕС = 1.0
TIMESTAMP : 13-11-2025 09:03:29 : OK : СОЗДАТЬ ФУНКЦИЮ ДЛЯ СЦЕНАРИЯ-3
TIMESTAMP : 13-11-2025 09:03:29 : OK : СОЗДАТЬ СКРИПТ ВЫЗОВА СЦЕНАРИЯ-3
TIMESTAMP : 13-11-2025 09:03:29 : OK : СЦЕНАРИЙ-3 ВЕС = 1.0
TIMESTAMP : 13-11-2025 09:03:29 : OK : СОЗДАТЬ ФУНКЦИЮ ДЛЯ СЦЕНАРИЯ-4
TIMESTAMP : 13-11-2025 09:03:29 : OK : СОЗДАТЬ СКРИПТ ВЫЗОВА СЦЕНАРИЯ-4
TIMESTAMP : 13-11-2025 09:03:30 : OK : СЦЕНАРИЙ-4 ВЕС = 1.0
TIMESTAMP : 13-11-2025 09:03:30 : OK : НАГРУЗОЧНЫЙ ТЕСТ СУБД - ГОТОВ К СТАРТУ
Шаг 4 - контроль статуса нагрузочного тестирования
cd /postgres/pg_expecto/sh/load_test
TIMESTAMP : 13-11-2025 09:03:30 : OK : НАГРУЗОЧНЫЙ ТЕСТ СУБД - ГОТОВ К СТАРТУ
tail: load_test.log: file truncated
TIMESTAMP : 13-11-2025 09:04:01 : OK : СБОР ДАННЫХ ПО НАГРУЗОЧНОМУ ТЕСТУ
TIMESTAMP : 13-11-2025 09:04:01 : OK : Текущий проход: 1
TIMESTAMP : 13-11-2025 09:04:01 : OK : Количество сессий: 5
TIMESTAMP : 13-11-2025 09:04:01 : OK : Время теста в секундах: 600
TIMESTAMP : 13-11-2025 09:04:01 : OK : jobs= 8
TIMESTAMP : 13-11-2025 09:04:01 : OK : ИТЕРАЦИЯ pg_bench
TIMESTAMP : 13-11-2025 09:04:01 : OK : ТЕСТОВАЯ БД = demo
TIMESTAMP : 13-11-2025 09:04:01 : OK : ВЛАДЕЛЕЦ ТЕСТОВОЙ БД = postgres
TIMESTAMP : 13-11-2025 09:04:01 : OK : СЦЕНАРИЙ-1: pgbench_clients= 5
TIMESTAMP : 13-11-2025 09:04:01 : OK : СЦЕНАРИЙ-1: pgbench_param= --file=/postgres/pg_expecto/sh/load_test/do_scenario1.sql --protocol=extended --report-per-command --jobs=8 --client=5 --time=600 demo
TIMESTAMP : 13-11-2025 09:04:01 : OK : СЦЕНАРИЙ-2: pgbench_clients= 5
TIMESTAMP : 13-11-2025 09:04:01 : OK : СЦЕНАРИЙ-2: pgbench_param= --file=/postgres/pg_expecto/sh/load_test/do_scenario2.sql --protocol=extended --report-per-command --jobs=8 --client=5 --time=600 demo
TIMESTAMP : 13-11-2025 09:04:01 : OK : СЦЕНАРИЙ-3: pgbench_clients= 5
TIMESTAMP : 13-11-2025 09:04:01 : OK : СЦЕНАРИЙ-3: pgbench_param= --file=/postgres/pg_expecto/sh/load_test/do_scenario3.sql --protocol=extended --report-per-command --jobs=8 --client=5 --time=600 demo
TIMESTAMP : 13-11-2025 09:04:01 : OK : СЦЕНАРИЙ-4: pgbench_clients= 5
TIMESTAMP : 13-11-2025 09:04:01 : OK : СЦЕНАРИЙ-4: pgbench_param= --file=/postgres/pg_expecto/sh/load_test/do_scenario4.sql --protocol=extended --report-per-command --jobs=8 --client=5 --time=600 demo
TIMESTAMP : 13-11-2025 09:05:01 : ИТЕРАЦИЯ : 1 СЕССИЙ pgbench : 5
TIMESTAMP : 13-11-2025 09:06:01 : ИТЕРАЦИЯ : 1 СЕССИЙ pgbench : 5
TIMESTAMP : 13-11-2025 09:07:01 : ИТЕРАЦИЯ : 1 СЕССИЙ pgbench : 5