
Научитесь защищать свой малый бизнес от IT-рисков и угроз
Управление рисками IT в малом бизнесе: 5 шагов к безопасности. Если коротко, я покажу, как за один месяц собрать рабочую систему управления ит рисками, не утонув в бюрократии и дорогих внедрениях. Путь будет практичный: от простой инвентаризации и оценки ит рисков до политики доступа, резервного копирования и автоматизации на n8n и Make.com. Расскажу, где морально не стоит экономить, какие метрики спасают от самоуспокоения и как встроить ИИ-агентов без сюрпризов. Пишу для руководителей малых команд, ИТ-специалистов первого стула и тех, у кого до вчера «всё лежало на одном ноутбуке Васи». Тема актуальна не из-за громких заголовков про кибератаки, а потому что сбой в одной ИТ системе сегодня означает сорванные сроки, потерю данных и репутационный след на долгие месяцы.
Время чтения: ~15 минут
- Зачем малому бизнесу своя система безопасности
- Пять шагов к безопасности без паники
- Инструменты и сервисы, с которыми удобно стартовать
- Как организовать процесс управления рисками
- Каких результатов ждать и как их мерить
- Подводные камни и типичные ошибки
- Шпаргалка на 30 дней: короткие шаги
- Что особенно важно запомнить
- Если хочется продолжить вместе
- Частые вопросы по этой теме
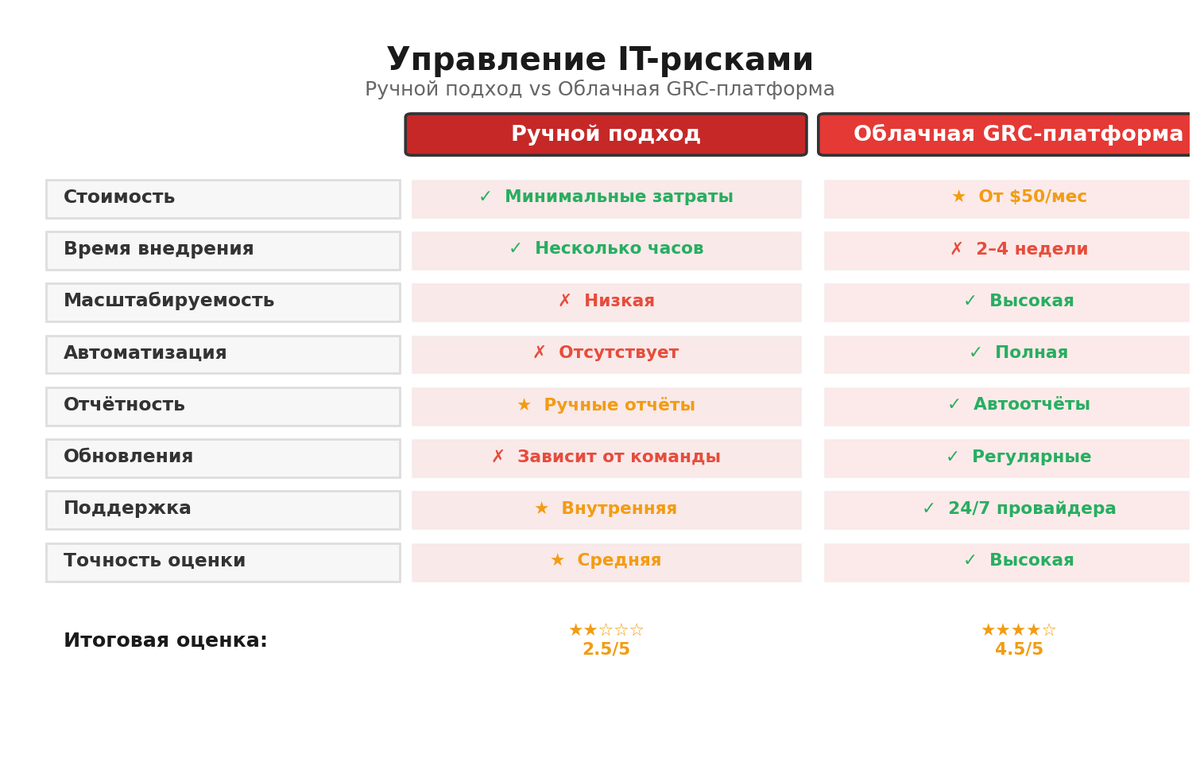
Обычно всё вспоминают про управление рисками, когда беда уже пришла и ноутбук не поднимается после обновления, а в чате с клиентом молчит длинная ветка, где лежал согласованный макет. Я видела разные истории: где-то бухгалтерия искала копию договора в облаке, которое отключили за неактуальную карту, где-то админ ушёл и вместе с ним ушли пароли. В моменте кажется, что это локальные ошибки, но, если честно, это классические операционные ит риски, их можно прогнозировать и снимать системно. В такие минуты хочется магическую кнопку, которая всё вернёт на место, но магия не помогает, помогает рутина, и да, иногда с третьей попытки в n8n.
Я выросла из внутреннего аудита и ИТ-рисков и давно держу курс на то, чтобы сложное превращалось в понятную механику. В малом бизнесе не взлетает тяжеловесный контроль на сотню пунктов, зато прекрасно работает набор из пяти шагов, где каждый закрывает конкретный сценарий: потерю данных, простой сервиса, утечку, саботаж прав доступа и неумолимые обновления, которые прилетают утром понедельника. Будет немного бытовых деталей, несколько аккуратных формул и живые примеры с автоматизацией, потому что процессы должны быть прозрачны, а метрики честные. И да, я работаю в white-data-зоне и берегу 152-ФЗ так же, как заголовки в вашем договоре.
Зачем малому бизнесу своя система безопасности
Что считать ИТ-риском по жизни
Когда говорю «ит риски», я не про что-то абстрактное, а про вполне конкретные истории: человек кликнул по ссылке и слил доступ к почте, VPS не продлили вовремя и легли интеграции, облако хранило бэкапы рядом с продакшеном и оба оказались недоступны из-за ошибки провайдера. Это не особые происшествия, это повторяемые риски ит систем и риски ит инфраструктуры, которые в небольших командах особенно чувствительны, потому что нет запаса людей и времени на долгий простой. Плюс современные риски ит технологий накладываются на привычные операционные ит риски: кадровые перестановки, форс-мажоры, требования регуляторов. Если смотреть трезво, управление рисками тут не про страх, а про экономию часов и бюджетов, которые потом идут на продукт, а не на тушение пожаров.
Еще важный момент, о котором многие забывают: зависимость от одного специалиста. Когда у вас один человек закрывает доступы, деплой и домены, это красиво до первого отпуска. Система управления рисками должна учитывать такие концентрации и предлагать простые меры управления рисками: разделение ролей, журналы действий, правила выхода сотрудника, которые срабатывают без лишнего шума. Я для себя называю это антихрупкостью команды: никто не становится точкой единственной неудачи, а процессы остаются управляемыми. И это, кстати, заметно снижает эмоциональные качели и помогает всем спать спокойнее, пусть кофе и остывает чаще, чем хотелось бы.
Куда исчезают деньги и почему это не всегда видно
Парадокс в том, что потери от неуправляемых рисков редко видны сразу. Нет красной лампочки, которая указывает, что утекло 4 часа, пока искали логин к хранилищу, или минус 3% маржи из-за задержек в один день. Но если подтянуть простейший процесс управления рисками, появляются числа: время восстановления, средняя длительность инцидента, доля критичных активов без бэкапа, доля учеток без 2FA. Эти метрики кажутся сухими, но в них деньги. Когда мы с одной командой ввели еженедельный обзор журналов и исправили доступы у подрядчиков, время на расследования сократилось вдвое, а общий «шум» инцидентов упал на треть. Формально мы не купили ничего нового, просто перестали терять незаметно.
Какие ориентиры выбирать, чтобы не переусердствовать
Стандарты уровня ISO/IEC и практики Zero Trust звучат громко, однако для малого бизнеса важнее адаптация. Я ориентируюсь на принципы здравого смысла и соответствия российским реалиям: соблюдаем персональные данные, внимательно относимся к требованиям ФСТЭК к сегментам инфраструктуры, делаем минимум один независимый бэкап и ограничиваем привилегированные доступы. Это база, которая не конфликтует ни с чем и не требует армаду консультантов. Можно нарастить поверх логи, мониторинг, автоматизацию проверки учеток и регулярные учения по фишингу. Главное — двигаться итеративно и фиксировать, что именно вы сделали, чтобы завтра это повторить без лотереи.
Устойчивость компании не в том, чтобы никогда не падать, а в том, чтобы быстро подниматься и при этом ничего не терять.
Я сознательно не обещаю серебряных пуль и стопроцентной защиты, потому что управление рисками ит проекта всегда игра вероятностей. Зато я обещаю работающий язык общения между владельцем бизнеса, ИТ и командой: у нас есть карта активов, у нас есть уровни критичности, у нас есть план восстановления. И когда это произнесено вслух и записано, неожиданности становятся менее острыми, а решения — быстрее.
Пять шагов к безопасности без паники
Инвентаризация и оценка, которые занимают один вечер
Начать лучше с таблицы, где перечислены активы: домены, почта, CRM, облачные диски, репозитории, платежные шлюзы, сервисы аналитики, рабочие станции и серверы. Рядом — владелец, уровень критичности, где лежат бэкапы и кто имеет доступ. Это не музей артефактов, а основа для оценка ит рисков: что будет, если пропадет доступ, насколько вероятно событие, как долго мы хорошо выдержим простой. В малой команде достаточно трех уровней для вероятности и трех для влияния, чтобы не рисовать академические матрицы. Получается грубая, но полезная карта, где красным горят сюжеты «нет бэкапа» и «один админ с полными правами».
Дальше добавляю быстрые проверки: парольная политика, наличие 2FA, обновления ОС и приложений, кто администратор в облачных сервисах. Здесь часто всплывают сюрпризы вроде старых интеграций, которые продолжают читать данные, хотя проект закрыли год назад. Это и есть процесс управления рисками ит в действии — вы снимаете верхний слой шума и находите концентрат с высокой отдачей. В конце вечера у меня обычно список из 10-15 мер управления рисками с понятным эффектом и ценой времени.
Правила игры для людей и минимум бумажной дисциплины
Политика безопасности звучит официозно, но по сути это компактный набор правил: как выдаем доступы, как реагируем на инцидент, что делаем при увольнении или входе подрядчика, где храним пароли и как шифруем диски. Я держу такую политику на 4-6 страниц, без канцелярита, чтобы ее реально читали. Обучение делаю короткими сессиями: фишинг, социнжиниринг, работа с почтой и мессенджерами, базовая гигиена. Сотрудники — не слабое звено по определению, слабым звеном становится отсутствие ясных правил и тренировки, особенно когда команда гибридная и распределенная. Если добавить элемент игрового теста раз в квартал, защита растет ощутимо.
Техника, копии, обновления и действия при ЧП
Технический слой неизбежен: антивирус, брандмауэр, шифрование дисков ноутбуков, контроль обновлений, отслеживание журналов входов. Для малых команд достаточно базовых решений, важно не забывать про резервное копирование по правилу 3-2-1: три копии, два разных носителя, одна копия вне площадки. Раз в месяц устраиваю проверку восстановления — не теория, а реальный возврат файла и тестовый запуск из бэкапа. Добавляю процедуру реагирования: кто сообщает, кто влияет, какие пороги эскалации и как коммуницировать с клиентами. Это и есть система управления ит рисками в миниатюре: правила, роли, циклы проверки, и, что важно, она вписывается в рабочий график без насилия над людьми.
Совет: не переносите все на одного «суперадмина». Разделите права на администрирование доменов, почты и облаков, ведите журнал выдачи токенов и регулярно закрывайте неиспользуемые.
Пять шагов складываются в привычку: инвентаризация, оценка, политика, техника, бэкап и реагирование. Да, я знаю, это шесть слов, но на практике люди и техника всегда идут вместе, а оценка без инвентаризации не живет. В этой связке легко назначить периодичность и встроить напоминания в календарь, чтобы забота не зависела от моего настроения и уровня кофеина.
Инструменты и сервисы, с которыми удобно стартовать
Автоматизация на n8n и Make.com
Я люблю, когда процессы крутятся сами. В n8n и Make.com за вечер можно собрать полезные сценарии: мониторинг статуса бэкапов, проверка истечения доменов, оповещения о новых админах в SaaS, выгрузка логов в единый канал. Если задействовать ИИ-агентов, то они помогают предварительно классифицировать события: фейл входа в систему, подозрительная активность API, массовое удаление файлов. Главное — не отдавать агентам принятие решений, только подсказки и черновые классификации. Такой подход дисциплинирует и снимает рутину: система управления рисками начинает дышать чаще, а ручных действий меньше.
Чтобы не изобретать велосипед, я держу библиотеку блоков: узлы для проверки 2FA в почтовых доменах, парсер журналов VPN, детектор подозрительных IP, напоминалки владельцам активов про продление лицензий. Эти заготовки легко переносить между компаниями, подправив конфигурацию. Иногда автоматизация требует третьей попытки, особенно если облако меняет API, но это жизнь, и лог безуспешных попыток тоже часть контроля. Я отдельно отмечу, что хранение чувствительных данных в сценариях должно быть аккуратным: токены в секретах, доступ по принципу необходимости и без личных ключей в общих репозиториях.
Мониторинг, журналы и минимальный SOC для малого бизнеса
Дорогой мониторинговый комбайн не обязателен. Начните с журналов входов, событий в облачных сервисах, уведомлений о сбоях. Важно настроить пороги и агрегировать сигналы: три неудачных входа подряд, смена привилегий, массовое скачивание данных. Выделите канал, где эти события живут, и человека на дежурство по неделям. Если добавить простой дашборд, появляются цифры для управленческого взгляда: сколько инцидентов, сколько решено, сколько требует мер управления рисками. И становится видно, где боли, а где шум.
Доступы, секреты и отключение лишнего
Самое недооцененное — своевременное закрытие доступов. Договор с подрядчиком завершен, а учетка живет месяцами. Решается просто: чек-лист входа и выхода, разнесение ролей, ревизия раз в квартал. Секреты храним в менеджерах паролей, заводим групповые учетные записи только там, где невозможно иначе, и неизбежно включаем 2FA. Для облачных автоматизаций создаем сервисные аккаунты с минимальными правами. Это скучные вещи, но именно они превращают управление рисками в повторяемый процесс, где сюрпризы случаются не по вине дисциплины.
Не всё нужно автоматизировать. Автоматизируйте то, что повторяется и болит, а не то, что красиво в презентации.
Кстати, я периодически делюсь разборами автоматизаций и рабочих сценариев у себя, и если хочется подсмотреть живые примеры без пафоса, удобнее заглядывать через мой канал там, где я собираю заметки и кейсы. Без привязки к конкретным вендорам, с акцентом на то, как вернуть себе время и не сорвать процессы.
Как организовать процесс управления рисками
Идентификация и оценка без лишних формул
Процесс начинается с карты активов и сценариев. Для каждого актива фиксируем три вещи: что может пойти не так, как часто это бывает, сколько боли принесет. Оценка простая: низкая, средняя, высокая. Подсвечиваем верхнюю треть и размечаем, кто владелец. Этого достаточно, чтобы не спорить о терминах и не утонуть в цифрах. При желании можно добавить денежную оценку часа простоя и тогда приоритизация становится математикой, а не компромиссом. Получается прозрачный процесс управления рисками, где решения привязаны к фактам, а не к интуиции.
На этом этапе я делаю маленькое упражнение: берем один актив, например CRM, и моделируем две ситуации — недоступность на 4 часа и утечка экспортом. Для первого считаем упущенные сделки и нагрузку на поддержку, для второго — юридические и репутационные последствия, включая требования 152-ФЗ. Это быстро показывает границы допустимого и помогает аргументированно распределить бюджет и время. Никакой теоретической магии, только здравый смысл и пара таблиц.
План обработки и конкретные меры
Когда верхние риски перед глазами, обсуждаем меры: избегать, снижать, передавать, принимать. Избегать — отказаться от опасного сценария. Снижать — 2FA, разграничение прав, бэкапы, мониторинг. Передавать — страхование или договорные обязательства с провайдером. Принимать — сознательно жить с риском, если цена снижения выше потенциального ущерба. Для малого бизнеса чаще всего это комбинация: базовые технические меры плюс организационные правила. Составляем план из 10-12 пунктов на ближайшие 3 месяца, вешаем сроки и ответственных. Это и есть система управления рисками, только маленькая и живая.
Контроль, пересмотр и короткие циклы
Контроль — это не про недоверие, а про память. Раз в неделю смотрим логи, раз в месяц делаем тест восстановления, раз в квартал ревизию доступов. Добавляем индикаторы: доля активов с 2FA, доля сервисов с актуальными контактами и платежными методами, количество инцидентов. В n8n ставим напоминания и автопроверки, чтобы не зависеть от человеческого фактора. Пересмотр рисков делаем раз в полгода или после заметного изменения в инфраструктуре. И всё, процесс управления рисками начинает крутиться сам, а я снимаю руками только трудные случаи.
Небольшая деталь: ведите журнал изменений. Даже текстовый файл с датами и кратким описанием часто спасает от споров «кто что когда делал».
Каких результатов ждать и как их мерить
Метрики, которые не стыдно показать на планерке
Мы любим числа, потому что они охлаждают головы. Полезные метрики: среднее время восстановления сервиса, доля активов с бэкапом, доля критичных доступов с 2FA, количество инцидентов на сотрудника, процент закрытых инцидентов до 24 часов. Дополнительно считаем долю устаревших токенов и сервисных ключей, чтобы не плодить «вечные» интеграции. Эти показатели не украшают презентации, зато дают возможность честно ответить, работает ли управление рисками или мы просто надеемся на удачу. Я обычно выношу 5-7 ключевых чисел и обновляю их ежемесячно.
Экономика профилактики на коротком плече
Скучные меры окупаются. Если команда тратит 8 часов в месяц на восстановление после мелких происшествий, а базовые меры срезают это до 3-4 часов, то на горизонте квартала освобождается неделя работы. Добавьте снижение вероятности крупного инцидента и появится понятная экономия. Да, это приблизительные оценки, но они помогают защищать решения перед командой и партнерами. Иногда я прямо считаю: цена простоя часа × вероятность × продолжительность — стоимость контроля. Если контроль окупается при двух инцидентах в год, значит это хорошая инвестиция в устойчивость.
Культура, которая не раздражает
Лучший индикатор — спокойствие в чатах. Когда правила понятны и автоматизация подстраховывает, снижается общий фон тревоги, а люди перестают бояться слова «аудит». Документы живут в простом виде, роли ясны, дежурства распределены, бэкапы подтверждены восстановлением. Меня иногда спрашивают, не превращается ли это в бюрократию. Нет, если правило умирает, когда не работает. Наша цель — не бумажное управление контролЯ рисков, а система, где каждый шаг возвращает время и ощущение контроля, а не отнимает силы у продукта.
Мы не строим крепость. Мы строим систему, которая терпит ошибки и быстро возвращается в рабочее состояние.
Подводные камни и типичные ошибки
Люди, ожидания и привычки
Чаще всего ломается не техника, а коммуникация. Ожидание, что «все и так понимают» правила доступа, заканчивается хаосом. Еще один сценарий — героический админ, который решает все лично. На короткой дистанции это быстро, на длинной все падает в отпуске. Поэтому я настаиваю на простых чек-листах и регулярных коротких сессиях по обучению. И да, фишинговые симуляции должны быть без стыда и обвинений, иначе люди прячут ошибки. Мы учимся ловить угрозы, не ловить коллег на ошибках.
Технологические ловушки и интеграционные хвосты
Ловушка номер один — слишком широкие права сервисных аккаунтов. Номер два — давно неиспользуемые интеграции, которые продолжают жить в фоне. Номер три — бэкапы без проверки восстановления. Все три решаются дисциплиной и небольшими автоматизациями: оповещения о новых правах, ревизия токенов раз в квартал, восстановление тестового кейса раз в месяц. Еще я часто вижу неочевидное: платежная карта на облако привязана к человеку, который уволен год назад. Тогда любой сбой оплаты превращается в мини инцидент. Переводите платежи на корпоративные реквизиты и держите актуальные контакты у провайдеров.
Юридическая гигиена и соответствие требованиям
Мы в России, и это важно учитывать. Персональные данные — не игровая тема, и тут нужен аккуратный учет, разграничение доступов и осмысленная обработка. Полезно заранее знать, где проходят границы ответственности между вами и провайдером, особенно в части хранения и передачи информации. Я не драматизирую, просто предлагаю держать в голове, что управлять рисками — это еще и про прозрачность отношений с контрагентами, договора, журналы событий и понятную процедуру ответа на инцидент. Когда точка контакта обозначена, вы экономите часы в критический момент.
Мини правило: все важное должно быть или задокументировано, или автоматизировано. Иначе это не контроль, а надежда.
Шпаргалка на 30 дней: короткие шаги
Неделя 1 — видимость и приоритеты
За первую неделю собираем карту активов и расставляем критичность. Я делаю это в таблице с пятью столбцами: актив, владелец, критичность, текущие меры, планы. Параллельно включаем 2FA там, где она отсутствует, и закрываем очевидные дыры в доступах. Этого уже достаточно, чтобы риск заметно снизился, а команда почувствовала контроль. Не забудьте назначить ответственных за каждый актив, пусть даже это временно и с правом на замену.
- Соберите список доменов, почты, облаков, CRM, репозиториев, платежных сервисов.
- Назначьте владельцев и уровни критичности.
- Включите 2FA и зафиксируйте резервные контакты у провайдеров.
Неделя 2-3 — правила и техника
Дальше пишем короткую политику безопасности и внедряем бэкапы по правилу 3-2-1. Настраиваем базовый мониторинг: логи входов, уведомления о смене прав, алерты о неудачных платежах. Подключаем n8n или Make.com для напоминаний и простых проверок. Проводим 30-минутную сессию для команды про фишинг и безопасную работу с файлами. Это не забирает день, но создаёт общий язык.
- Опишите правила выдачи и отзыва доступов плюс чек-лист входа и выхода.
- Проверьте бэкапы и сделайте тестовое восстановление файла.
- Добавьте автоматические уведомления о ключевых событиях.
Неделя 4 — устойчивость и пересмотр
На финише проводим ревизию токенов и сервисных аккаунтов, отрубаем лишнее, подтверждаем владельцев активов и контакты у провайдеров. Подводим метрики за месяц: сколько инцидентов, сколько решено, где узкие места. Формируем план на следующий месяц из 8-10 пунктов. Если время осталось, тестируем сценарий реагирования — кто кого уведомляет и как идем по шагам. Всё, у вас базовая система управления рисками проекта, которая работает без музейной пыли.
- Пересмотрите права, удалите устаревшие интеграции.
- Подтвердите роли и контакты, зафиксируйте в журнале изменений.
- Соберите метрики и сформируйте следующий план.
Если нужна вдохновляющая инженерная пища, на моем сайте можно посмотреть, чем я занимаюсь и какие процессы автоматизирую. Это помогает понять, как такие практики живут в реальных проектах и где automation действительно экономит часы, а не делает вид.
Что особенно важно запомнить
Я стараюсь оставлять после себя не отчеты, а привычку к ясности. Управление ит рисками — не про страх и запреты, а про осмысленную экономию времени и нервов. Малому бизнесу не нужны тяжелые регламенты, ему нужны простые ритуалы: инвентаризация, минимальная оценка, правила доступа, проверенные бэкапы и аккуратная автоматизация. ИИ-агенты уместны как помощники, но не как вершители судеб. Метрики пусть будут скучными, зато они показывают, что меняется в реальности, а не на слайдах. Люди всегда важнее технологий, а прозрачные процессы важнее красивых названий. Если что-то не работает, меняем, а не держимся из уважения к прошлому, и да, иногда я перечеркиваю полстраницы и думаю: нет, лучше так.
Спокойствие приходит не от «железа», а от соглашений в команде и от честной картины того, что у нас есть и как оно защищено. И когда в следующий раз что-то пойдет не по плану, вы не будете искать пароли в старой переписке, а просто откроете журнал, выполните шаги и вернете систему к жизни. Это лучшая мотивация продолжать и беречь то, что вы строите каждый день.
Если хочется продолжить вместе
Тем, кто хочет структурировать знания и попробовать рабочие шаблоны автоматизации, удобнее всего смотреть живые разборы и мини гайды в моем канале о практической автоматизации и управлении ИТ рисками. А на сайте я собрала примеры процессов и материалы, которые помогают внедрять это без лишнего шума. Берите идеи, адаптируйте под себя, двигайтесь небольшими шагами — так устойчивость становится привычкой, а не проектом на один раз. Никакой магии, только прозрачные процессы и уважение к вашему времени.
Частые вопросы по этой теме
С чего начать, если нет времени и людей
Начните с таблицы активов и включения 2FA, это дает быстрый эффект за вечер. Затем назначьте владельцев активов и поставьте напоминания на ежемесячные проверки, автоматизируйте через n8n простые оповещения.
Какие метрики важнее всего в начале
Время восстановления, доля активов с бэкапом и 2FA, количество инцидентов в месяц. Эти числа просты в сборе и хорошо отражают динамику без тяжелых систем.
Нужны ли дорогие решения для малого бизнеса
Нет, базовые меры и дисциплина закрывают 80% проблем. Дополнительно можно подключить легкие инструменты мониторинга и скрипты автоматизации, чтобы снизить ручную работу.
Как безопасно использовать ИИ и агентов
Давайте им роль ассистентов: анализ логов, классификация событий, черновики уведомлений. Доступ к данным ограничивайте, персональные данные защищайте и исключайте принятие критичных решений без человека.
Как часто пересматривать риски и политику
Минимум раз в полгода или при заметных изменениях в инфраструктуре. Чек лист ежемесячных проверок поможет не пропускать мелочи, которые превращаются в инциденты.
Что делать, если инцидент уже случился
Зафиксировать событие, ограничить распространение, восстановить из бэкапа, провести разбор без обвинений и обновить меры. Важно документировать шаги и корректировать процесс, чтобы не повторять ошибки.
Как распределять ответственность между подрядчиками и командой
Определите владельца каждого актива и четкие границы в договоре с подрядчиком. Доступы выдавайте по минимуму, логи оставляйте у себя и обязательно закрывайте учетные записи после завершения работ.