
Выстраиваем систему управления рисками для IT в вашем бизнесе
Я люблю говорить о рисках не как о страшилке, а как о рутине, которую можно приручить. В этой статье я разложу по полочкам, как малому бизнесу управлять айти-рисками без лишней бюрократии и дорогих игрушек. Покажу, где слабые места, что автоматизировать в первую очередь, и как выстроить базовую систему на n8n или Make.com, чтобы не ловить инциденты на слух. Разберемся с ISO 31000, аккуратно посмотрим на NIST CSF, сопоставим это с российскими реалиями и 152-ФЗ, а затем соберем рабочую схему: инвентаризация, контроль доступа, резервные копии, мониторинг и план реагирования. Я дам пошаговый чек-лист на месяц внедрения, с примерами из практики, мелкими бытовыми деталями и без хайпа. Материал подойдёт руководителям, продактам, операторам персональных данных, консультантам и всем, кто хочет, чтобы процессы были предсказуемыми, а метрики честными.
Время чтения: ~15 минут
- Почему малый бизнес чаще ловит айти-риски
- Система управления рисками без бюрократии
- Инструменты, которые тянут на себя львиную долю рутины
- Как я собираю контур контроля за 2 недели
- Каких эффектов ждать и как их считать
- Что пойдет не так и как подстелить соломку
- Чек-лист на месяц внедрения
- Последняя точка на карте
- Если хочется продолжить
- Частые вопросы по этой теме
Я часто вижу одну и ту же картину: бизнес растет быстрее, чем меняется его айтишная основа. База клиентов уже в десятках тысяч, интеграций больше десятка, а список критических сервисов живет в чьей-то голове и в одном Google-доке с прошлогодней датой. Утро начинается нормально, кофе слегка остыл, и тут прилетает тикет: платежи не проходят, CRM не отдает API, маркетинг ругается, потому что сегменты зависли. Виновата не судьба, а накопившиеся мелочи: забытые обновления, слишком широкие права доступа, резервные копии, которые не восстанавливаются, и автоматизации, которые работают, но никто не понимает как. В такие моменты риски айти превращаются из абстракции в простой вопрос: сколько часов вы сегодня потеряете и сколько рублей утечет мимо кассы.
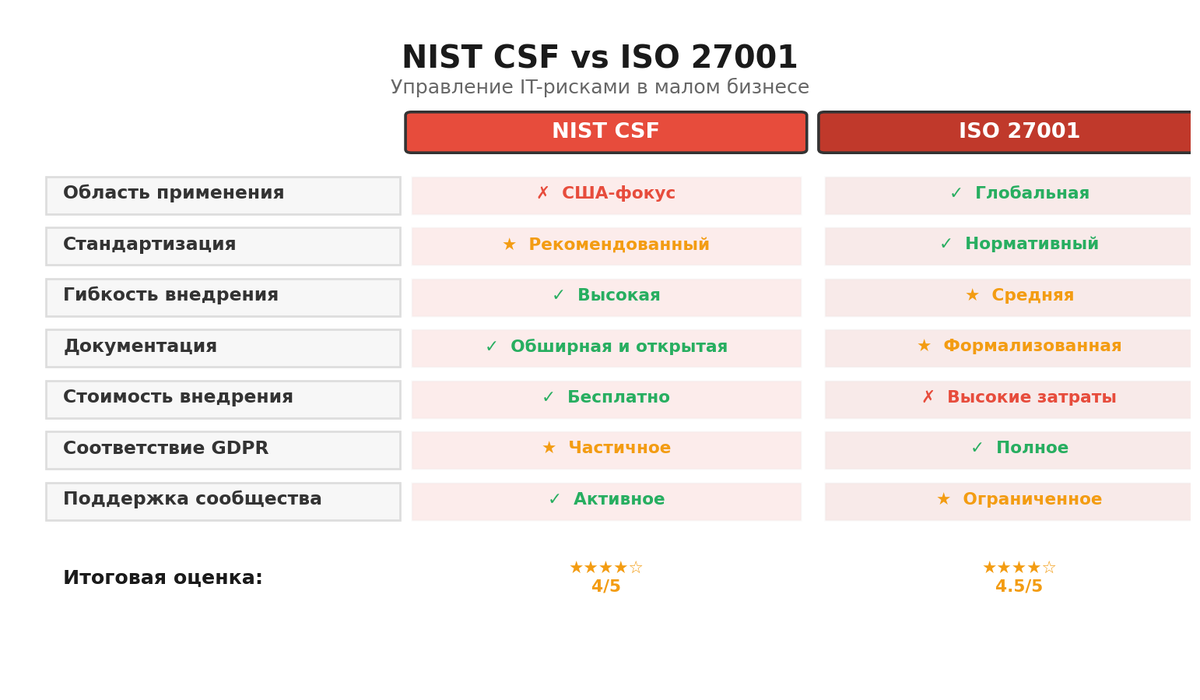
Мне близка позиция, где риски айти компаний раскладываются на язык инфраструктуры, людей и операций. Да, угрозы меняются, но уязвимости часто родом из дисциплины: не хватает инвентаризации, не хватает прозрачности процессов, не хватает практичности в выборе инструментов. Стандарты есть, и они полезны, но бизнесу нужна не стопка документов, а живой контур: что считать критичным, какие метрики смотреть каждое утро, что автоматизировать, чтобы экономить часы, а не тратить их на бесконечные чаты. Под это и подстроим подход: адаптируем ISO 31000, возьмем пару идей из NIST CSF, пройдемся по 152-ФЗ и построим компактную, но честную систему управления рисками, которая не мешает работать, а помогает дышать ровнее.
Почему малый бизнес чаще ловит айти-риски
Ограниченные ресурсы, теневая автоматика и человеческий фактор
Малый бизнес уязвим не потому, что он маленький, а потому что у него планирование часто побеждает пожаротушение только на бумаге. Бюджеты ограничены, специалисты совмещают роли, процессы зависят от пары ключевых людей, которые знают как именно крутится прод, и что где падает при очередном маркетинговом запуске. В результате появляются тени — автоматизации, написанные на коленке, вебхуки без логирования, доступы по принципу «добавила на всякий случай», и временные решения, которые живут годами. Я встречала отделы, где нода n8n с бета-плагином висела на арендованном VPS без мониторинга, и все молились, чтобы никто не тронул обновления. Риски айти в такой среде не теоретические, они операционные: где тонко — там рвётся в будний день к обеду.
Поверх этого ложится человеческий фактор. Сотрудники не обязаны быть экспертами по безопасности, но фишинговые письма, избыточные права в облачных хранилищах и невинные переносы данных в личные мессенджеры создают ту самую зону риска, которую редко видно глазами. Единственная защита — не разовые лекции, а минимизация влияния ошибки: многофакторная аутентификация, преднастроенные роли, понятная политика паролей, и запрет на чувствительные данные там, где их быть не должно. В малом бизнесе это решается быстрее, чем в крупном, если разделить ответственность и явно показать, где и зачем мы защищаемся.
Третье — ошибка в масштабе. Мы привыкли думать, что киберпреступники идут на крупняк, но статистика утечек рассказывает обратное: чем меньше защита, тем проще проникновение, и тем быстрее монетизация. Для малых компаний это не только про прямой ущерб от простоев, но и про репутацию в нише, судебные риски и истории с регулятором. И да, здесь вспоминается 152-ФЗ: если вы оператор персональных данных, то у вас не только моральная, но и юридическая ответственность, и организационные меры обязательно должны быть. Это звучит сурово, но на практике все упирается в дисциплину и регулярность.
Без видимости нет управления: пока вы не видите активы, данные и интеграции в одном месте, вы не управляете рисками, вы угадываете.
Как распознать слабые места до инцидента
Самая честная диагностика — ответить на пять простых вопросов. Где лежат критичные данные и кто к ним имеет доступ. Какие сервисы невосстановимы в течение часа и что у вас по RTO и RPO. Какие внешние интеграции критичны для выручки и кто ими владеет. Где журналируются события доступа и действий администраторов. Как выглядит ваш базовый playbook на случай инцидента и кто нажимает на паузу платежи. Если хотя бы два ответа заставили вас открыть мессенджер и спрашивать коллег, значит картина не собрана, и вы двигаетесь на ощупь. Не страшно, главное — не затягивать.
Я обычно начинаю с карты активов: таблица с системами, владельцами, типами данных, интеграциями и степенью критичности. Это не идеальная CMDB, и не надо ей притворяться, но это дает общую картину: что держится на локальном железе, что в облаке, где SaaS, где самопис, а где вообще хрупкий no-code. Следом — инвентаризация учеток и прав: проще всего пройтись по группам и ролям, отсекая лишнее. В параллель — аудит резервного копирования: что копируется, куда, с каким шифрованием, и когда последний раз вы делали тестовое восстановление. И, конечно, журналирование: доступы, изменения в критичных системах, попытки входа — без этого мы потом ищем иголку в стоге сена.
Сигнал, что пора что-то менять: у вас больше 5 критичных сервисов без автоматических алертов, и хотя бы один из них управляется «через знакомого». Тут шанс на нежданный простой близок к 100% в горизонте квартала.
Этот блок я всегда заканчиваю простым тезисом: риски айти компаний уменьшаются, когда появляется прозрачность и ритм. Не сразу, без чудес, но ровно с того дня, когда владелец каждого актива обозначен, резервное копирование проверено восстановлением, а инциденты имеют имя, канал и регламент.
Система управления рисками без бюрократии
Как адаптировать ISO 31000 под маленькую команду
ISO 31000 — не про толщину папки, а про логику: определить контекст, оценить риски, выбрать меры, мониторить и улучшать. Для небольших команд я это сжимаю до трёх артефактов: реестр рисков, карта активов и годовой план мер. Реестр — это таблица с пятью колонками: описание риска простыми словами, последствия в рублях и часах, вероятность в горизонте года, текущие меры контроля и владелец. Для оценки достаточно шкалы 1-5 и согласованного определения, что есть «критично». Никаких сложных формул в первый месяц, главное — договориться о языке и критериях.
Контекст — это ваши обязательства по 152-ФЗ, требования клиентов и реальность инфраструктуры. Если вы оператор персональных данных уровня обезличивания, это одно, если вы обрабатываете финансовые транзакции — другое. Полезно наложить NIST CSF как чеклист функций: Identify, Protect, Detect, Respond, Recover. Да, это международная модель, но она хорошо ложится на практику: увидеть активы, защитить доступ, обнаружить инцидент, отреагировать, восстановиться. В малом бизнесе важно не распыляться: выберите 2-3 приоритета на квартал и двигайтесь без фанатизма.
Ключевой момент — аппетит к риску. Он должен быть явным: какой простой допустим для фронтового сайта, какая потеря данных недопустима ни при каких обстоятельствах, и какой объем ручной работы команда готова терпеть. Здесь без эмоций, только числа и сценарии. Если вы не готовы жить с потерей часа CRM, значит резервирование и мониторинг приоритетны. Если вы принимаете риск редкого простоя маркетинговых витрин, это один набор мер. Честность на этом шаге экономит деньги и нервы.
Не все риски надо «убить». Часть достаточно принять и наблюдать, часть — разделить с провайдером, часть — застраховать, а часть — минимизировать до приемлемого уровня.
Минимальный набор ролей и ритм встречи
Я определяю двух владельцев: владелец риска и владелец контроля. Первый отвечает за решение, закрываем ли мы риск, переносим, уменьшаем или принимаем. Второй — за конкретные меры: настроить MFA, задеплоить алерты, провести тест восстановления. На старте это часто одни и те же люди, и ничего страшного. Важно назначить еженедельный слот 30-40 минут, где вы смотрите на метрики, инциденты и изменения в реестре. Раз в квартал — ревизия аппетита к риску и приоритетов. Ритм строит систему без дополнительных денег.
Документы держите в живом виде: таблицы в защищенном пространстве, доступ по ролям, журналы изменений включены. Рядом — короткие регламенты: кто делает что при инциденте, кто общается с клиентами, где новости статуса. Никаких многостраничных политик в первый месяц. Сначала минимальные артефакты, которые работают, потом — расширение. И да, суммарно это занимает меньше времени, чем вы тратите на один серьезный простой.
Инструменты, которые тянут на себя львиную долю рутины
Где автоматизация спасает часы, а где лучше не трогать
Автоматизация — не серебряная пуля, но она отлично снимает рутину. В части мониторинга и интеграций я использую n8n или Make.com: оба позволяют быстро собирать сценарии без тяжелого кода, подключать API облаков, мессенджеров и внутренних систем. Для малых команд отлично заходит связка: Zabbix или легкий облачный мониторинг для инфраструктуры, n8n для оркестрации событий и уведомлений, Telegram-бот для алертов и команд, и S3-совместимое хранилище в Yandex Cloud или VK Cloud для резервных копий. На безопасность — Kaspersky или Dr.Web с централизованным управлением, плюс обязательная MFA и управление паролями в корпоративном менеджере. Главное — не строить дворец: берите минимум, который закрывает Identify-Protect-Detect-Respond-Recover.
Есть зоны, где я автоматизирую осторожно. Разграничение прав — через родные средства платформ, без самодельных костылей на вебхуках. Резервное копирование — через зрелые решения, где есть логика ротации, шифрование и проверка целостности, а не через self-made скрипты на один сервер без аудит-трейла. Логи — лучше централизовать в стеке, который вы понимаете: от простых облачных сервисов до собственного ELK, если есть компетенции. И еще правило: автоматизация должна быть наблюдаемой. Если вы не видите, когда ваш сценарий упал, значит вы просто добавили еще одну точку отказа.
Пример простого стека для малого бизнеса
Я соберу базовый стек так. Инвентаризация и реестр рисков — таблица в защищенном пространстве Yandex 360 с разграничением прав. Мониторинг доступности и задержек — Zabbix или Managed Service провайдера плюс вебхуки в n8n. Оркестрация алертов и runbook-автоматика — n8n, где узлы принимают события, записывают их в журнал, уведомляют в Telegram и создают карточки инцидентов. Резервные копии — Object Storage с версионированием и шифрованием, проверка восстановления по расписанию, отчеты в общий канал. Безопасность конечных точек — Kaspersky Security Center, параллельно — регулярное обновление ОС и ключевых приложений. Логи аутентификации и админ-активности — в централизованный лог-стэк. Сделать это можно за пару недель без тяжелого вендор-лока, и это уже снимает большую часть операционных рисков.
Автоматизация хороша там, где она делает невидимое видимым: показывает, что упало, где, когда, и что уже сделано для восстановления.
Если хочется посмотреть подход шире, у меня есть разборы и сравнения на сайте — аккуратно оставлю ориентир внутри фразы: на основном сайте MAREN собраны материалы про управление, зрелость и практики автоматизации. Это часть контекста, без агрессивных призывов.
Как я собираю контур контроля за 2 недели
Неделя первая: видимость, данные и быстрые выигрыши
День 1-2: инвентаризация активов. Я прошу владельцев сервисов перечислить приложения, базы, интеграции и внешние зависимости. Сразу фиксирую владельца и критичность. День 3: классификация данных в разрезе 152-ФЗ — где ПДн, где коммерческая тайна, где общедоступные данные. День 4: раздаю роли и минимизирую доступы — убираю лишние права, включаю MFA, проверяю сервисные учетки. День 5: включаю базовый мониторинг доступности и ошибок, завожу алерты в Telegram-бот, настраиваю quiet hours и эскалации. День 6: проверяю резервы — делаю восстановление на тестовую среду и фиксирую время. День 7: быстрые регламенты — кто дежурит, кто решает приоритезацию, как выключаем интеграцию при подозрении на инцидент. Это уже снимает часть остроты, и команда начинает дышать свободнее.
Здесь же я прохожу по цепочке платежей и CRM: какие вебхуки критичны, где логируются события, как мы видим задержки. Если на n8n есть хрупкие сценарии, я добавляю узел повторной отправки, ограничение по ретраям, запись в отдельную таблицу для расследований. Каждую точку отказа я либо дублирую, либо строю вокруг нее алерт с понятным действием. И да, иногда на третий запуск узел ругается, но это лучший момент для исправлений, чем в бою. Я не стесняюсь оставлять пометки и мелкие правки прямо в процессе, иногда считаю это даже полезным.
Неделя вторая: план реагирования и риск-метрики
День 8-9: описываю playbook по инцидентам. Сценарии простые: подозрение на фишинг, падение платежного шлюза, недоступность CRM, нарушение в обработке ПДн. Для каждого — кто отвечает, какие шаги предпринимаются, как фиксируются действия. День 10: финализирую реестр рисков и согласую аппетит. День 11: встраиваю метрики — MTTD, MTTR, доступность, доля автоматических восстановлений, доля закрытых доступов. День 12: довожу журналирование действий администраторов. День 13: делаю тестовую «учебную тревогу» на одном сценарии и замеряю время. День 14: корректирую регламенты, распределяю дежурства. На этом базовый контур контроля готов, а дальше начинается нормальная жизнь — мониторинг, ревизии и постепенное улучшение.
В два шага: сначала сделайте так, чтобы все падения были видны, потом — чтобы на большинство падений было автоматическое действие или понятная инструкцию в одном месте.
Не забудьте про коммуникации. Отдельный канал статусов, короткие апдейты во время инцидента, одна точка правды — это снижает шум и ускоряет восстановление.
Каких эффектов ждать и как их считать
Метрики, которые честно отражают зрелость
Люблю простые числа, потому что они сразу показывают динамику. Доступность по критичным сервисам в процентах — не для красоты, а как индикатор архитектуры и дисциплины. MTTD — среднее время обнаружения инцидента, и MTTR — среднее время восстановления. Доля инцидентов, закрытых без ручного вмешательства — показатель качества автоматизации. Среднее время восстановления из резервной копии — в отдельной строке, потому что это всегда болит. Доля сотрудников с включенной MFA — показатель привычек безопасности. Эти метрики не требуют сложной системы, их можно собирать в простых таблицах и ботом раз в неделю.
Финансовый эффект считается грубо, но полезно. Возьмите среднюю выручку в час по сегменту, умножьте на среднее время простоя и на количество подобных инцидентов за период. Добавьте трудозатраты на расследования и ручные обходные решения. Теперь посмотрите, сколько инцидентов стало заметно раньше, сколько закрывается автоматически, и сколько часов перестали улетать в ручную проверку. Другая часть — снижение вероятности редких, но дорогих событий: тут я предпочитаю консервативные оценки, чтобы не рисовать фантастические ROI. Главное — видеть тренд вниз по потере часов и вверх по доле автоматизации.
Пример эффекта на одном канале
В одной компании мы сократили MTTD с 45 минут до 6 за счет нормального мониторинга и алертов в Telegram, и MTTR с 2 часов до 35 минут за счет готовых playbook и автоматики перезапуска. Резервное восстановление показало, что реальный RTO был не 60 минут, как считали, а 2 часа 20 минут — после исправлений уложились в 50 минут. По выручке это сэкономило 1-2 рабочих дня в месяц. На капитальные вложения мы не лезли, все делалось на существующих сервисах и легких интеграциях. Не магия, просто видимость и дисциплина.
Считать стоит не только деньги, но и внимание команды. Чем больше автоматизации снимает рутину, тем больше времени остается на развитие продукта, а не на героизм.
Что пойдет не так и как подстелить соломку
Классические ловушки в малых командах
Первая ловушка — переавтоматизация без наблюдаемости. Сценарии крутятся, но никто не видит, когда они упали и почему, логи в разных местах, один узел ломает всю цепочку. Вторая — надежда на «мы и так маленькие, нас никто не тронет». Тронут, если случайность и слабая защита пересекутся. Третья — резервное копирование без восстановления: ротация есть, но никто не пробовал подняться из бэкапа, а когда попытались — нужных ключей нет, или скорость канала все сломала. Четвертая — размытая ответственность: инцидент происходит, а кто принимает решение — непонятно, в итоге теряются драгоценные минуты. Пятая — расслоение между IT и бизнесом: разные словари, разные ожидания, никакого общего аппетита к риску.
Есть и менее очевидные вещи. Доступы подрядчиков — временные, но почему-то вечные. Секреты и ключи — в переписке, а не в закрытом хранилище. Переезд в облако — без настроек сетевой сегментации и базовых политик. Журналирование — выключено из жалости к диску. Тут помогает чек-лист и регулярная ревизия, без геройства. Риски айти уменьшаются не хакерскими феями, а маленькими, но упорными исправлениями.
Как сгладить последствия и поделить риски
Часть рисков разумно делить с провайдерами — пусть SLA и ответственность за слой, который вы не тянете сами, будут прописаны прозрачно. Часть — страховать: киберстрахование на рынке развивается, и для некоторых сценариев это адекватная подстраховка. Но основа неизменна: наблюдаемость, резервирование, обучение, регламенты. Добавлю про кадры: минимальные тренинги по фишингу и цифровой гигиене экономят часы расследований. По опыту, одно-три занятие в квартал уже заметно меняют картину.
Вы не обязаны решать все риски сами. Но вы обязаны знать, где они, каковы последствия и кто рядом с вами в случае беды.
Чек-лист на месяц внедрения
Практические шаги без перегруза
Зафиксирую последовательность, которую я даю командам. Это не догма, а дружелюбный маршрут на 4 недели. В каждой неделе найдется день, когда n8n попросит перезапуск, а кофе опять остынет — ничего, едем дальше, прогресс важнее идеала.
- Неделя 1. Активы и доступы: собрать карту систем и интеграций, назначить владельцев, включить MFA, урезать лишние права, завести реестр рисков с 10-15 позициями.
- Неделя 2. Наблюдаемость: подключить мониторинг доступности и ошибок, настроить алерты в Telegram, собрать runbook на 3-4 типовых инцидента, включить журналирование действий админов.
- Неделя 3. Резервы и данные: проверить резервное копирование, сделать тест восстановления, классифицировать данные по 152-ФЗ, ограничить распространение ПДн в сторонних сервисах.
- Неделя 4. Отладка и ритм: провести учебную тревогу, отмерить MTTD и MTTR, завести еженедельную встречу по рискам, зафиксировать аппетит и SLA, обновить реестр рисков.
- Постоянно. Обновления и обучение: регулярные патчи ОС и приложений, короткие тренинги по фишингу, ревизия доступов, проверка ключей и секретов.
Куда заглянуть по дороге: готовые разборы и схемы по автоматизации я время от времени обсуждаю в своем пространстве — когда уместно, упоминаю деликатно. В рабочих заметках я ссылаюсь на материалы на promaren.ru и обсуждения в телеграм-канале MAREN — без навязчивости, просто как источник примеров и дискуссий.
Последняя точка на карте
Если отойти на шаг, то картина простая. Малому бизнесу не нужна большая система рисков, ему нужна честная видимость, понятные правила и минимальная автоматизация, которая бережет время. Мы обозначили, почему проблемные места возникают именно в маленьких командах, и как превратить стандарты в практику: ISO 31000 как логика, NIST CSF как карта функций, 152-ФЗ как наша реальность, где данные защищены не словами, а рутиной. Я показала, каким стеком инструментов можно закрыть большую часть операционных айти-рисков, и как за две недели собрать контур контроля, который не будет хрупким. Дальше все решает ритм: еженедельный взгляд на метрики, квартальная ревизия аппетита и неторопливое, но упорное уменьшение доли ручного труда.
Я по-хорошему мечтаю, чтобы контент и процессы делались сами, а люди возвращали себе часы. В рисках это значит одно: вы заранее видите, что важно, автоматически получаете сигнал, и действуете по заранее согласованной схеме. Никакой магии: просто дисциплина, прозрачность и дружелюбная автоматизация. И немного спокойствия в голосе, когда кто-то пишет «что-то не так». Возможно, это и есть главный эффект — к команде возвращается ощущение управляемости. Ну, и пусть кофе остынет — зато вечер пройдет без авралов.
Если хочется продолжить
Если чувствуешь, что этой схемы достаточно, чтобы начать, это уже половина дела. Я периодически разбираю рабочие кейсы, схемы на n8n и Make.com и подходы к управлению рисками без лишней помпы — упоминала это выше и повторю мягко: часть заметок и методических материалов живет на сайте MAREN, а живые обсуждения и разборы проходят в телеграм-канале MAREN. Можно просто заглянуть, взять идеи и адаптировать их под свою реальность — без обещаний чудес, только практика и цифры.
Частые вопросы по этой теме
С чего начать, если нет вообще ничего
Начните с карты активов и владельцев, затем включите MFA и базовый мониторинг доступности. Параллельно заведите реестр рисков на 10-15 пунктов и назначьте еженедельную встречу на 30 минут. Этого достаточно, чтобы сдвинуть систему с места.
Можно ли обойтись без стандартов и все равно жить спокойно
Можно, если у вас есть логика, которая их заменяет: видимость, оценка, меры, мониторинг. Но стандарты удобны как чеклист и общий язык — они не мешают, если не превращать их в бюрократию. Лучше использовать их как рамку и не перегибать.
n8n или Make.com — что выбрать для оркестрации
Выбирайте по компетенциям и доступности интеграций. n8n хорош, когда хочется гибкости и контроля, Make.com удобен для быстрых сборок. Важно одно: сценарии должны быть наблюдаемы, с логами и алертами о падениях.
Как часто проверять резервные копии
Минимум раз в месяц делайте тестовое восстановление и фиксируйте время. После существенных изменений в инфраструктуре проведите внеплановую проверку. Это дешевле, чем один неудачный реальный инцидент.
Нужно ли киберстрахование малому бизнесу
Это разумная опция, когда вы понимаете профиль угроз и можете оценить последствия редких, но дорогих событий. Оно не заменяет базовых мер, но снижает финансовую турбулентность. Решается по ситуации и бюджету.
Какие метрики смотреть каждую неделю
MTTD, MTTR, доступность по критичным сервисам, доля инцидентов с автозакрытием, состояние резервного восстановления и доля сотрудников с MFA. Этого набора обычно достаточно, чтобы понимать динамику зрелости.
Как вписать требования 152-ФЗ в повседневную работу
Классифицируйте данные, ограничьте доступы, включите журналирование и обучайте сотрудников основам цифровой гигиены. Регламенты держите короткими и понятными, а проверки — регулярными. Это не отдельная вселенная, а часть каждодневной рутины.