
Выстраиваем эффективное управление IT-рисками для вашего малого бизнеса
Если коротко, я покажу, как собрать работающую систему управления ИТ-рисками за 5 шагов без лишней бюрократии и страха перед аббревиатурами. Это инструкция для владельцев и руководителей небольших компаний, руководителей ИТ и операционщиков, кто привык делать руками и хочет, чтобы процессы были прозрачны, метрики честные, а инциденты не прилетали ночью. Почему сейчас это особенно актуально. Мы живем в реальности, где облака мигрируют, сервисы периодически «встают», а персональные данные защищать приходится по полной, с 152-ФЗ в голове и на практике. У малого бизнеса нет роскоши длительных согласований и армии специалистов, зато есть возможность быстро внедрять решения. Я опираюсь на базу ГОСТ и ISO, объясняю простыми словами и добавляю автоматизацию на n8n и Make.com там, где она реально экономит часы. Кофе остынет, но процессы двинутся.
Время чтения: ~15 минут
- Почему ИТ-риски в малом бизнесе кусаются тише, но больнее
- Как уложить риск менеджмент в пять шагов и не утонуть в бумагах
- Шаг 1. Видим риски: инвентарь, контекст, угрозы
- Шаг 2. Считаем влияние: оценки без страха чисел
- Шаг 3. Выбираем ответы: меры, перенос, отказ
- Шаг 4. Встраиваем в процесс: роли, регламенты, n8n и агенты
- Шаг 5. Непрерывный мониторинг: метрики и разбор инцидентов
- Подводные камни и короткие кейсы
- Что забираем из этой статьи
- Если хочется продолжить эксперимент
- Частые вопросы по этой теме
Пожалуй, самая честная правда про управление рисками в менеджменте звучит скучно: не бывает волшебной кнопки, есть повторяемые шаги и дисциплина. В малом бизнесе это не минус, а подарок, потому что вы реально можете внедрить процесс за пару недель и увидеть эффект, а не писать полгода регламенты ради галочки. Я пришла к этому из внутреннего аудита и ИТ-рисков, и каждый раз вижу одну и ту же картину: проблема не в отсутствии стандартов, а в том, что всё воспринимается как «бумажная история», а не как способ вернуть себе время и снизить операционные ИТ-риски. Когда вы перестаете спорить с реальностью и начинаете считать простыми числами, скорость решений растет, а нервов тратится меньше.
Суть задачи понятна: риск менеджмент в ИТ должен защищать деньги, данные и время. Деньги теряются через простои и штрафы, данные утекают или портятся, время уходит на тушение пожаров. На горизонте маячат законы, подрядчики, внешние атаки, ошибки сотрудников, и всё это перемешано с вашими продуктами и дедлайнами. Здесь не нужен толмуд, нужна минимальная работающая система. Я пользуюсь ГОСТ Р ИСО 31000 для логики, опираюсь на Гост р менеджмент риска в терминологии, а в части ИБ смотрю на ИСО/МЭК 27001 и российский контекст с 152-ФЗ и практиками защиты ПДн. Дальше я покажу, как превратить это в пять конкретных шагов, как организовать процесс риск менеджмента и где автоматизация реально помогает. Будет без магии и хайпа, но с примерами, цифрами и парой ироничных ремарок.
Почему ИТ-риски в малом бизнесе кусаются тише, но больнее
Когда большой компании выключают один сервис, она переключается на резерв, а репутацию спасает пресс-служба. Малый бизнес часто молчит, закрывает ноутбук и едет в офис чинить руками, потому что резерва нет, а команда маленькая. ИТ-риски в таких условиях ведут себя коварно: на диаграммах они выглядят скромно, а в жизни легко превращаются в убыток за месяц. Три типичных источника боли: зависимость от одного-двух поставщиков, неочевидные риски ИТ инфраструктуры и человеческий фактор. Если к этому добавить требования по ПДн и контракты с клиентами, которые включают SLA, то картинка становится вполне конкретной. По моей практике, 70-80% инцидентов приходят не от хакеров, а изнутри, из незакрытых мелочей.
Вопросы менеджмента риска в малом бизнесе чаще всего упираются в отсутствие списка активов и понимания приоритетов. Никто толком не знает, где живет критичная таблица в облаке и кто к ней имеет доступ, как настроены резервные копии и когда последний раз тестировалось восстановление. Параллельно работают личные почты, файлы переехали в мессенджеры, админские пароли лежат в блокноте у одного спеца. Звучит банально, но именно так и начинается цепочка из операционных ИТ рисков. Дальше всё просто: падает база — встает выдача заказов — деньги не приходят — горят дедлайны — моральный дух утыкается в ноль.
На этом месте обычно спрашивают, как управлять рисками компании, если нет штата из пяти ИБ-специалистов и бюджета на дорогие системы. Ответ взрослый и скучный: сделать базовый процесс и автоматизировать рутину. Сначала — минимальный реестр активов и угроз с оценкой, затем — выбор мер, регламент реакции и пара метрик. Да, это звучит как учебник, но без этого любые красивые решения и ИИ-агенты будут латать последствия, а не устранять причины. Важный нюанс: в России мы живем с конкретными требованиями к ПДн, к защите информации и отраслевым регуляциям, и это нужно учитывать с первого дня, чтобы не тащить за собой юридический хвост.
Риск-менеджмент — это не «бумага», а короткая внятная договоренность в компании, как мы не теряем деньги, данные и время.
С точки зрения методологии ничего космического. Есть ГОСТ Р ИСО 31000, в части ИБ — ГОСТ Р ИСО/МЭК 27001, а если нужно, можно свериться с НИСТовской логикой, адаптируя под российские реалии. Главное — не копировать тома, а брать суть: контекст, оценка, обработка, мониторинг и постоянное улучшение. Дальше покажу, как это упаковать в пять шагов, пригодных для небольших команд. И да, кофе уже остывает, но вы его всё равно допьете, потому что дальше — самое прикладное.
Как уложить риск менеджмент в пять шагов и не утонуть в бумагах
Пять шагов выглядят предсказуемо, но в их простоте и сила. Первый — видим риски, то есть инвентаризируем активы и угрозы. Второй — считаем влияние и вероятность, без академических перегибов. Третий — выбираем ответы: принять, снизить, передать или отказаться. Четвертый — встраиваем в процессы и автоматизируем, чтобы система работала сама. Пятый — мониторим и улучшаем, фиксируем инциденты, считаем метрики, обновляем карту. В такой упаковке организация риск менеджмента перестает быть проектом на год и становится рутиной, которую реально тянуть небольшой командой без боли.
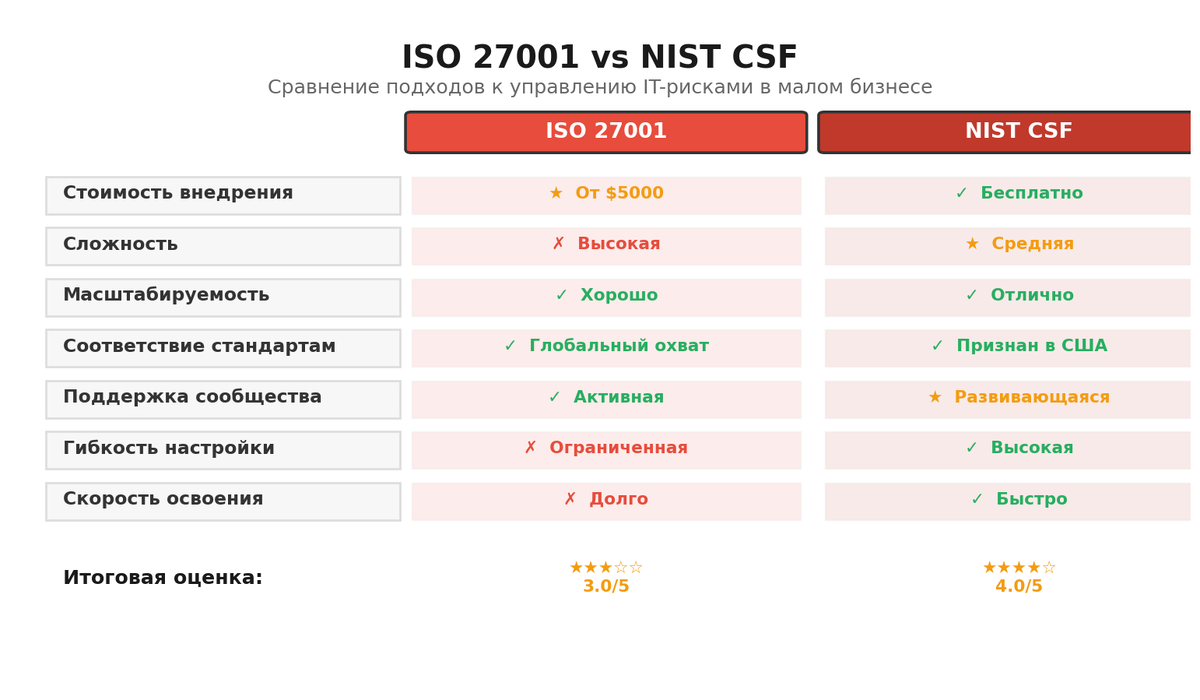
Теорией мы не ограничимся, но одну развилку обозначу. Обычно спорят: брать ли за основу ISO 27001 или смотреть на NIST CSF как на каркас. В малом бизнесе я рекомендую гибрид: цели и управление — из ISO, понятную карту функций Identify-Protect-Detect-Respond-Recover — из NIST. Документы и роли — по ГОСТ Р ИСО 31000, с поправкой на ваши масштабы. Итог — компактная система, где есть реестр рисков, регламенты, чек-листы, и автоматизация, которая поднимает события, собирает логи, шлет нотификации и ведет отчеты. Бумаги минимум, пользы максимум.
Теперь к полезной бытовухе. Чтобы шаги действительно поехали, нужны простые артефакты. Реестр активов, список угроз и уязвимостей, матрица рисков, политика резервного копирования, чек-лист обновлений, регламент реагирования на инциденты с номерами телефонов и конкретными ролями. Важно сразу назначить владельцев рисков и определить риск-аппетит: что приемлемо, а что нет. Когда все это упаковано в понятные формы и вшито в n8n или Make.com для напоминаний и сборов данных, процесс риск менеджмента начинает жить сам без постоянного ручного разгона.
Мини-правило: все документы должны существовать настолько, насколько они помогают команде действовать быстрее. Если бумага не двигает процесс — выкиньте или упростите.
Дальше мы пройдемся по каждому шагу. Покажу, как собрать реестр, как выбрать метод оценок, какие метрики ставить на дашборд и где автоматизация отрабатывает лучше живого человека. После этого у вас будет минимум для запуска и понимание, как растить систему без боли. А теперь — к шагу номер один, самому недооцененному.
Шаг 1. Видим риски: инвентарь, контекст, угрозы
Контекст и список активов
Начинаю с инвентаризации. Составляю список активов: системы, данные, интеграции, устройства, подрядчики, учетные записи, ключевые таблицы и дашборды. Для каждого — владелец, местоположение, критичность, наличие резервирования, контакт. Это скучно, да, но занимает 2-3 рабочих дня, если не пытаться описать Вселенную. Параллельно фиксирую контекст: какие законы на нас смотрят, какие договорные обязательства есть, какие сроки простоя критичны. Особенно внимательно отношусь к ПДн: где хранятся, кто обрабатывает, как защищаем согласно 152-ФЗ и локальным политикам. Этот шаг сразу поднимает на поверхность то, что обычно «знают все, но нигде не записано».
Карта угроз и уязвимостей
Дальше — угрозы. Разбиваю их на категории: технические сбои, ошибки персонала, кибератаки, сбои поставщиков, изменения в законодательстве. Для каждой категории быстро фиксирую 3-5 типовых сценариев и проверяю, что у нас уже есть против них. Например, риски ИТ систем: потеря базы из-за сбоя облака, шифрование из-за вредоносного ПО, утечка из-за настройки доступа по умолчанию. Риски в ИТ проектах: срыв сроков из-за зависимостей, провал интеграции из-за изменения API, человеческие ошибки на выкладке. Появляется список, который можно оценивать и закрывать, а не тревога общего характера.
Минимальная автоматизация
Чтобы не уронить это в эксель навсегда, ввожу простую автоматизацию. В n8n делаю сценарий: раз в неделю собираем метаданные по ключевым сервисам, проверяем доступность, срок действия доменов и сертификатов, статус резервных копий, отбираем критичные события из логов. В Make.com можно собрать опрос для владельцев активов с автонапоминаниями, чтобы они раз в месяц подтверждали актуальность. Результаты пишем в таблицу и в карточки задач. Я видела, как это экономит по 3-5 часов в неделю, просто потому что люди перестают искать в чате, где доступ к базе, и вспоминать, когда последний бэкап проверяли.
Если актив не записан и у него нет владельца — это уже риск. Пусть маленький, но он накопится ровно в тот момент, когда все будут заняты.
На выходе шага один у вас реестр активов и угроз, и это уже половина победы. Можно жить без идеальной детализации, главное — начать видеть картину. Дальше начнем считать, чтобы не спорить на ощущениях, а принимать решения цифрами. Я тут обычно говорю себе: стоп, не усложняй, бери простую шкалу, а потом дорастешь до сложных моделей, если понадобится.
Примечание: формально этот шаг укладывается в ГОСТ Р ИСО 31000 и в практику гост менеджмент риска, где важно определить контекст и критерии. Не надо переписывать стандарт, возьмите оттуда структуру мыслей и двигаемся дальше.
Шаг 2. Считаем влияние: оценки без страха чисел
Простая шкала, которая работает
Менеджмент оценки рисков не про высшую математику, а про сопоставимость. Я использую двухмерную матрицу 5×5: вероятность от редкой до почти неизбежной и влияние от минимального до критического. Влияние считаю в деньгах через простой подход: оценка простоя в рублях за час, оценка утечки через возможный штраф и репутационные потери, оценка исправления через трудозатраты команды. Если нужно, добавляю отдельную оценку для ПДн и регуляторных рисков. Вся магия — в том, чтобы договориться о правилах и применять их ко всем ситуациям одинаково. Иначе риски будут «кататься» в таблице в зависимости от настроения.
Чуть точнее, если хочется цифр
Иногда полезно пойти дальше матрицы и оценить годовой ожидаемый ущерб. Для этого беру частоту инцидента в год и средний ущерб на один инцидент, перемножаю и получаю ориентир. Это не строгая статистика, но она помогает сравнивать альтернативы. Например, купить дополнительную защиту за N рублей или смириться с редким простоем и вложиться в ускоренное восстановление. Кстати, так иногда рождаются ответы риск менеджмент на неприятные вопросы от собственников: почему тратим на резервирование, а не на маркетинг, и где возврат инвестиций. Когда есть число, разговор становится спокойнее.
Практический чек-лист оценок
Чтобы всё поехало, фиксирую критерии. Что для нас критично в рублях и часах, какой простой приемлем, какой нет, сколько стоит восстановление данных, какую минимальную защиту мы считаем «базой». Это и есть риск-аппетит. Записываю это в одну страницу и согласовываю с владельцами направлений. В российской реальности добавляю критерии по 152-ФЗ: если риск затрагивает ПДн, он автоматически растет в приоритете, потому что цена ошибки выше. Так решения становятся одинаково логичными в разных ситуациях, а не зависят от громкости заголовков в новостях.
Не бойтесь округлять. В малом бизнесе важна скорость договоренностей и повторяемость, а не псевдоточность.
Результат шага — у каждого риска есть число или цвет в матрице и понятная формулировка, почему он попал в приоритет или ушел в «наблюдение». Теперь можно выбирать меры, а не спорить про философию угроз. Дальше будет самое прикладное: какие ответы доступны и как их сочетать так, чтобы не переплатить и не усложнить жизнь команде.
Шаг 3. Выбираем ответы: меры, перенос, отказ
Четыре стратегии и их комбинирование
Классика проста: принять, снизить, передать, отказаться. Принять — если риск дешевле, чем его закрытие. Снизить — если меры реально уменьшают вероятность или влияние. Передать — когда часть ущерба уходит к подрядчику по договору или в страхование. Отказаться — выключить функциональность или изменить процесс. Обычно стратегия комбинируется. Например, снизить за счет 2FA и обучения, передать часть рисков провайдеру с прописанным SLA, а остаток принять, но держать восстановление в два клика. Это и есть управление рисками в менеджменте, только без громких слов.
База мер, которая выручает чаще всего
Есть набор практик, которые окупаются почти всегда. Надежное резервное копирование с периодическим тестом восстановления. Двухфакторная аутентификация на ключевых сервисах. Разделение прав доступа по ролям, минимум админов. Регулярные обновления и патчи, лучше на автопилоте. Обучение сотрудников распознаванию фишинга и аккуратной работе с ПДн. Документированные процедуры выкладки изменений. Это снижает риски ИТ технологий и инфраструктуры на порядок, без экзотики. Если проект с критичной финансовой нагрузкой, подключаем финансовый риск менеджмент: лимиты сумм, двойное подтверждение платежей, прозрачное логирование.
Про деньги и ИИ на практике
Как управлять финансовыми рисками в малом бизнесе. Разделить платежные роли, ввести лимиты и двойное подтверждение, логировать все транзакции, раз в неделю смотреть дашборд отклонений. Как ИИ помогает управлять финансовыми рисками. Агенты могут мониторить аномальные операции и поднимать вопросы, но решения остаются за человеком. Важно помнить про российскую специфику: хранение данных, правовые основания обработки, требования к ПДн. Если речь о страховании, выбирайте страховщика, который корректно покрывает ИТ-инциденты для вашего масштаба, а в договорах с подрядчиками аккуратно фиксируйте ответственность и сроки восстановления. Сухо, но работает.
Подсказка: в договоре с критичным подрядчиком пропишите конкретные RTO и RPO, каналы эскалации и контакт ответственного. Это уменьшает риски ИТ компаний по цепочке поставок.
После выбора мер записываю, кто что делает и к какому сроку, и сразу вшиваю это в задачи команды. Автоматизация пригодится уже на следующем шаге. Если решений получилась гора, делю их на треки: быстрые победы на неделю, средние на месяц и фундаментальные на квартал. Так все видят прогресс, а не бесконечный список хотелок.
Шаг 4. Встраиваем в процесс: роли, регламенты, n8n и агенты
Роли и регламенты без бюрократии
Система без закрепленных ролей всегда рассыпается на первом инциденте. Я назначаю владельца процесса, владельцев активов, ответственных за резервные копии и обновления, и одного координатора по инцидентам. Документы делаю короткими: политика резервного копирования на 1 страницу, регламент реакции на инцидент на 2 страницы с чек-листом. В регламент включаю номера телефонов, канал в корпоративном мессенджере, критерии эскалации. Это не про формальность, это про скорость действий в 2 часа ночи. В российском контексте добавляю раздел про ПДн: как действуем, кого уведомляем, какие журналы ведем.
Автоматизация на n8n и Make.com
Здесь начинается экономия часов. В n8n настраиваю опрос владельцев активов, проверку статуса резервных копий через API, мониторинг сроков доменов и сертификатов, сбор логов по ключевым событиям, интеграцию с почтой и мессенджером для уведомлений. В Make.com подключаю формы для инцидентов, триаж заявок и автоназначение задач. Простые ИИ-агенты решают рутину: классифицируют инциденты по шаблонам, вытаскивают ключевые факты из логов, проверяют, что карточка события содержит все обязательные поля. Всё это работает в white-data-зоне, с учетом 152-ФЗ, без отправки персональных данных куда попало. Я люблю, когда процессы прозрачны: в итоге у меня есть дашборд со статусами и метриками, и никто не бегает с вопросом «где бэкапы».
Метрики и видимость
Чтобы система жила, нужны две-три метрики. Среднее время обнаружения и реакции, доля инцидентов, закрытых по регламенту, процент успешных тестов восстановления. Можно добавить простой индекс зрелости: есть ли документ, назначен ли владелец, автоматизирован ли контроль. Метрики живут не на слайдах, а в задачах и n8n-нотификациях. Как банки управляют рисками — они меряют и дисциплинируют процесс через метрики, нам полезно брать этот подход в упрощенном виде. Прозрачность снимает эмоции: все видят, где мы молодцы, а где нужно подкрутить. Это и есть управление рисками ИТ проекта как часть операционной рутины.
Автоматизируйте напоминания и сбор фактов, а решения оставьте людям. Так и скорость, и качество останутся на уровне.
На выходе шага — процесс работает сам: напоминания приходят, статусы обновляются, инциденты заводятся по одному и тому же шаблону, а регламенты не пылятся. Это тот момент, когда уже можно переключить внимание на улучшения и углубить мониторинг.
Шаг 5. Непрерывный мониторинг: метрики и разбор инцидентов
Ритм и повестка
Мониторинг — это не про «смотрим на графики», а про ритм. Я ставлю еженедельный короткий слот на 20-30 минут: проверяем метрики, смотрим открытые риски и инциденты, принимаем решения по блокерам. Ежемесячно — обновляем реестр, раз в квартал — делаем разбор одного-двух инцидентов по методике пост-мортем. Важная деталь: фиксируем, что менять в процессах, а не ищем виноватых. Ошибки персонала — неизбежная часть жизни, задача менеджмента риска — превращать их в улучшения, а не в охоту на ведьм. Такая регулярность держит операционные ИТ риски в тонусе и не дает накопиться «залежам» незакрытых пунктов.
Проверка готовности к худшему
Раз в квартал я запускаю короткую тренировку восстановления. Берем критичную базу, поднимаем копию, проверяем целостность и скорость. Если не получается с первого раза, это не провал, это сигнал для процесса. Параллельно смотрю у подрядчиков: у них есть план B, прописанные RTO и RPO, окно на обслуживание. Даже простая проверка контактов эскалации уже снижает риски ИТ инфраструктуры. В списке контроля держу в первую очередь ПДн: где живут, кто доступен, как журналируются действия, как закрывается доступ при увольнении.
Дашборд и сигнализация
Дашборд с 5-7 виджетами закрывает большинство вопросов. Ключевые риски с цветами, метрики MTTD и MTTR, статус резервных копий, список инцидентов с приоритетом, карта активов с владельцами. Настраиваю пороги, при которых идет уведомление в общий канал и эскалация владельцу процесса. Это не SIEM уровня банка, но этого достаточно, чтобы не просыпаться от внезапного «ничего не работает». А если внезапно всё же громко, то у нас есть регламент и контакты, и мы знаем, как управлять рисками проекта в конкретной ситуации.
Подсказка: держите все уведомления в одном месте, но разделяйте уровень критичности. Иначе вы быстро устанете и перестанете реагировать.
На этом шаге процесс становится циклом. Вы что-то улучшили, замерили эффект, обновили реестр, переставили приоритеты. Так выглядит взрослая организация риск менеджмента. Она не идеальна, но предсказуема, а это для малого бизнеса дороже совершенства.
Подводные камни и короткие кейсы
Самая частая ошибка — пытаться описать всё и сразу. В итоге тратим недели на формулировки, а простейшие дыры остаются. Вторая — перекладывать ответственность на «чудо-сервис». Любая платформа хороша постольку, поскольку она вшита в ваши процессы и данные. Третья — забывать про людей. Если команда не понимает, зачем это, риск-менеджмент превратится в скучную табличку. Еще один болючий момент — переоценка подрядчиков: кажется, что они все контролируют, а по факту SLA плавающие, а эскалация через общий почтовый ящик. Я бы сказала, что 1-2 часа на проверку договоров и контактов экономят дни, когда что-то действительно падает.
Короткий кейс из практики. Небольшой e-commerce, команда 12 человек, один ИТ-специалист. Резервные копии были, но их не тестировали, а доступ к CRM был у пяти менеджеров с одинаковым паролем. Внедрили 2FA, разделили роли, настроили автоматический тест восстановления раз в две недели, добавили в регламент карту эскалации и телефон подрядчика. Через месяц случился сбой облака, восстановление заняло 40 минут вместо дня. Потери в деньгах — на уровне допустимого, нервы — целее обычного. Еще один случай: интеграция с платежным провайдером изменила API, и в прод улетели ошибки. После короткого пост-мортема добавили отдельный чек на стенде и регламент выкладки. С тех пор выкладки перестали быть лотереей.
И чуть про инвестиции времени. На старт ушло около 25-30 часов моей работы и по 3-5 часов от владельцев активов. Автоматизация на n8n сэкономила потом 2-3 часа в неделю, а Make.com убрал рутину в коммуникациях. Это как с уборкой: сначала тяжело и неочевидно, потом дышится легче. Я, честно, пару раз думала «ай, потом», но каждый раз возвращалась к дисциплине и видела, как падает шум и растет предсказуемость.
Практические советы на старт за 10 дней:
- Соберите список из 20-30 ключевых активов, назначьте владельцев, отметьте критичность.
- Опишите 10 типовых угроз и сразу привяжите к активам.
- Оцените риски по матрице 5×5, договоритесь об одном риск-аппетите на страницу.
- Выберите 7-9 базовых мер: 2FA, бэкапы с тестом, разграничение доступа, обновления, регламент инцидентов.
- Настройте в n8n три сценария: проверка бэкапов, мониторинг сертификатов, ежемесячный опрос владельцев активов.
- Сделайте короткий регламент реагирования с контактами и сценариями эскалации.
- Запустите еженедельный 30-минутный слот мониторинга и первый мини-пост-мортем.
Если эти шаги сделаны, вы уже на голову выше среднего. Дальше можно докручивать контроль доступа, расширять мониторинг, подключать агентскую помощь для разбора логов и аномалий. Важно не потерять ритм и не попытаться «перепрыгнуть через лестницу». Медленно — тоже быстро, если стабильно.
Если любите копнуть глубже в стандарты и сравнения подходов, у меня есть спокойные разборы и наблюдения на сайте, где я аккуратно сверяю ISO, NIST и российские требования с практикой. Я периодически делюсь и необычными решениями с автоматизацией и ИИ-агентами, и это помогает тем, кто не хочет жить только в таблицах. Для знакомства можно заглянуть в мои заметки на сайте MAREN, а за живыми мини-разборами и практикой приходить в телеграм-канал — там спокойный темп и примеры без хайпа.
Что забираем из этой статьи
Я осознанно держала фокус на простых шагах, потому что именно они двигают систему в небольших командах. Практический каркас выглядит так: вы собираете реестр активов и угроз, оцениваете риски простой матрицей, выбираете меры с привязкой к деньгам и времени, вшиваете все в короткие регламенты и автоматизацию, а потом задаете регулярный ритм мониторинга. На каждом шаге вы минимизируете риски ИТ технологий и инфраструктуры, не перегружая команду и сохраняя прозрачность. В российском контексте это означает внимательное отношение к ПДн и договорам, а также к реальности вашего стека и поставщиков.
Если сверяться с ключевыми стандартами, то мы держим логику ГОСТ Р ИСО 31000, подтягиваем практики ИСО/МЭК 27001 и адаптируем понятные функции защиты из NIST CSF. На практике это не про бумагу, а про договоренности, дисциплину и автоматизацию. Я искренне верю, что вопросы менеджмента риска решаются быстрее, когда мы перестаем спорить про идеальную модель и начинаем считать и проверять регулярно. А еще полезно помнить, что идеал не нужен, нужна предсказуемость. Возвращайте себе время через рутину, которую вы контролируете. И пусть кофе будет теплым, хотя бы в половине случаев.
Если хочется продолжить эксперимент
Если хочется структурировать эти знания и собрать у себя маленькую, но крепкую систему, начните с первого шага и одной-двух автоматизаций. Для тех, кто готов перейти от теории к практике и любит аккуратные сравнения подходов, я регулярно публикую заметки и разборы у себя на сайте MAREN. А за живыми примерами, короткими инструкциями и идеями для n8n, Make.com и ИИ-агентов можно заглядывать в мой телеграм-канал — там спокойно, по делу и без магии. Я пишу простыми словами, проверяю всё на себе и люблю, когда контент делается сам, а люди возвращают себе время.
Частые вопросы по этой теме
С чего начать, если вообще ничего не сделано
Соберите список активов и назначьте владельцев, затем опишите 10 типовых угроз. Оцените по простой матрице и выберите 7-9 базовых мер, которые снизят риски быстро. Запустите два сценария автоматизации для контроля бэкапов и сертификатов.
Какие стандарты брать в основу для малого бизнеса
Логику — из ГОСТ Р ИСО 31000, безопасность — из ИСО/МЭК 27001, функции защиты — из NIST CSF с адаптацией под российские реалии. Берите суть и упрощайте до масштаба вашей команды.
Как понять, что мер достаточно и не переплачиваем
Сравнивайте стоимость мер с ожидаемым ущербом и держите риск-аппетит на одной странице. Если мера не уменьшает вероятность или влияние измеримо, возможен отказ или перенос ответственности на подрядчика.
Что автоматизировать в первую очередь
Контроль резервных копий и тестов восстановления, мониторинг сертификатов и доменов, напоминания владельцам активов, шаблоны инцидентов и эскалации. Это экономит часы и снижает вероятность человеческих ошибок.
Как управлять рисками при инвестировании в ИТ-проекты
Считайте сценарии: стоимость простоя, вероятность технических сбоев, риски интеграций. Задайте лимиты и критерии стоп-решений, фиксируйте SLA подрядчиков, держите RTO и RPO в договорах.
Нужен ли отдельный специалист по рискам
Не обязательно. В небольшой компании роль владельца процесса может взять операционный или ИТ-руководитель, при необходимости привлекая экспертизу точечно. Важнее ритм и автоматизация, чем должность в визитке.
Что делать, если подрядчик подвел
Поднимайте прописанную эскалацию, фиксируйте инцидент и фактические показатели, применяйте договорные механизмы. Пересматривайте модель отказоустойчивости и диверсифицируйте поставщиков при критичном влиянии.