
Создайте учебные видео с аватарами без лишних затрат и усилий
Сynthesia для видео с аватарами: инструкция по созданию обучающих материалов
Если коротко, здесь собрала мой рабочий подход к тому, как из текста сделать понятное обучающее видео с цифровым ведущим, без съемочной группы и нескончаемых согласований. Мы посмотрим на Synthesia как на инструмент, который ускоряет производство уроков, инструкций и вводных для сотрудников, и аккуратно разберем, что нужно подготовить заранее, чтобы не переписывать сценарии по четыре раза. Я покажу, где автоматизация на n8n и Make.com снимает рутину, как встроить видео в LMS и как при этом не нарушить 152-ФЗ, если в учебных примерах есть персональные данные. Важно, что это не магия и не хайп: просто последовательность шагов и несколько решений, которые экономят часы, а иногда недели. Материал подойдет тем, кто отвечает за обучение и коммуникации в компании, делает продуктовые гайды, умеет считать метрики и хочет, чтобы контент делался сам. Если вы интересуетесь ИИ-агентами, конвейерами контента и хотите понять, когда синтетический ведущий уместен, а когда лучше записать живое видео, вы в нужном месте. Я пишу с примерами и мелкими огрехами речи, как есть, потому что задача — рабочая, а не парадная.
Время чтения: ~15 минут
- Почему обучающие видео с аватаром экономят недели
- Что дает Synthesia и в каких кейсах я её беру
- Подготовка: сценарий, структура, данные и 152-ФЗ
- Пошаговый процесс сборки видео в Synthesia
- Автоматика вокруг видео: n8n, Make.com, LMS и Telegram
- Качество и метрики: как понять, что видео работает
- Подводные камни и как их спокойно обходить
- Быстрый чеклист и приемы, которые себя окупили
Почему обучающие видео с аватаром экономят недели
Когда компания быстро растет, внутренняя база знаний редко успевает за продуктом, а инструкции живут в документах и чатах, которые никто не перечитывает. Обучающее видео решает проблему скорости усвоения и удержания внимания, но классическая съемка упирается в организацию, студию, свет, голос и длительный монтаж, который ломается от одной правки формулировки. Цифровой ведущий с нейросетевым голосом дает иной ритм: я пишу текст, разбрасываю его по сценам, добавляю графику, и за несколько итераций получаю стабильный ролик, где обновить юридическую формулировку или дату релиза — дело минут. Это не про замену живых людей, а про рутинные объяснения, вводные и микрообучение, которые рационально делать синтетическими, чтобы эксперты тратили время на сложные вопросы. Я часто вижу, как synthesia видео вытесняет многостраничные регламенты и презентации, которые сотрудники открывают только перед аттестацией, потому что видео проще в потреблении. При этом экономится не только производство, но и сопровождение: один мастер-файл и версионирование, без PDF по папкам и версий с названиями наподобие final_final_2. Внутренний аудит и риск-офис тоже спокойнее: меньше человеческих ошибок при пересказе, больше единообразия формулировок, и проще доказать, что все слышали одно и то же. И да, для международных команд многоязычность важна: один сценарий — несколько языков, без найма дикторов на каждую локаль.
Цифровой ведущий хорош там, где важно единообразие и частые обновления, а не харизма конкретного спикера.
В этом подходе я люблю прозрачность: заранее понять, какой контент правда лучше сделать в Synthesia, а какой оставить в виде статьи или короткого скринкаста. Если задача — показать сложный интерфейс в динамике, то синтетический ведущий идет в паре с захватом экрана и подсветкой шагов, а если это объяснение политики безопасности, то достаточно статичных слайдов и уверенного голоса. Секрет экономии времени тут в дроблении на короткие сцены и грамотном сценарии, чтобы каждую правку можно было внести точечно, не перекраивая весь ролик. И еще один плюс, про который часто забывают: одинаковый темп речи и отсутствие паразитных слов снижают утомляемость и повышают внимание, особенно у новых сотрудников, у которых и так перегруз. Да, кофе иногда остывает, пока рендерится первая версия, но это лучше, чем ждать согласования съемочного плана неделями. Так что проблема решается не одним кликом, а подходом, который делает производство видео предсказуемым процессом с понятными сроками и качеством.
Для повторяющихся инструкций, политик, регламентов и onboarding-модулей синтетический ведущий дает лучшую стоимость владения: правки стоят дешево по времени и не зависят от графика спикера.
Если коротко подвести микро-вывод, экономия возникает из трех компонентов: быстрый цикл правок, повторное использование сценариев и отсутствие логистики съемки. Я обычно добавляю сюда стандартные шаблоны визуального оформления, чтобы визуальный шум не крал силы у смыслов, и получаю стабильный конвейер. Это и будет мостиком к выбору инструмента.
Что дает Synthesia и в каких кейсах я её беру
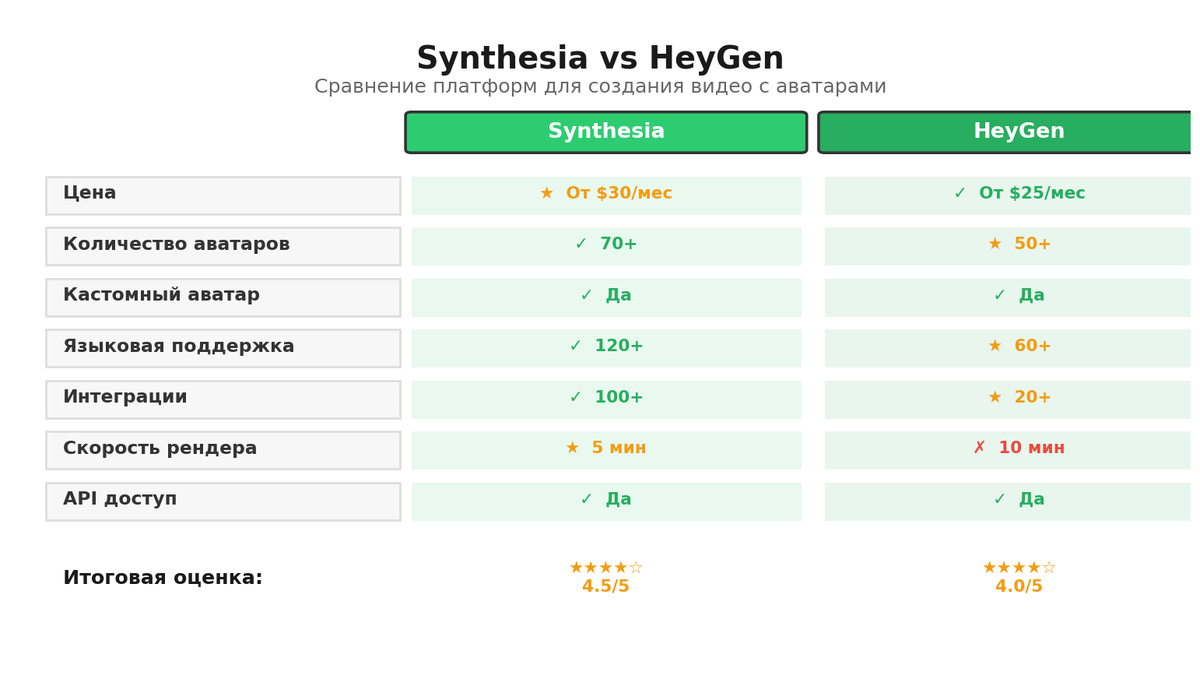
Synthesia — это платформа для синтетического видео с цифровыми аватарами и многими языками, где работа строится как в презентации: сцены, текст, голос, графика. Здесь больше 160 аватаров и 130+ языков, включая русский, что закрывает международные задачи без разнородных голосов и поиска дикторов. Мне нравится, что интерфейс не перегружен, а библиотека шаблонов покрывает типовые сценарии обучения сотрудников, вводные по продукту и стандарты безопасности, и это правда ускоряет. Для задач с брендбуком можно построить свой набор стилей и компонентов, чтобы синтетический ведущий не выпадал из фирменной айдентики и был похож на внутренние презентации. Отдельного внимания заслуживает возможность персонализации — кастомные аватары и озвучка своим голосом, если есть юридические основания и согласия, о которых мы поговорим чуть позже. Важно, что synthesia генератор видео имеет предсказуемую логику таймингов: вы задаете текст, и получаете понятную длительность сцены, что помогает проектировать темп обучения. В совокупности это дает инструмент, который я спокойно беру в работу, когда нужна скорость, стабильность и возможность дешево обновлять контент при изменениях процессов.
Есть ли у Synthesia ограничения, которые важно знать заранее, чтобы не разочароваться в последний момент? Да, и это нормально: сложная жестикуляция, эмоциональные нюансы и нестандартные ракурсы тут не самоцель, акцент на четкость подачи и чистую дикцию. Для роликов, где критична выразительность живого человека или демонстрация реальных объектов, я предпочитаю гибриды: синтетический ведущий для вводной и блок с экраном или реальной съемкой для демонстрации. Плюс я считаю важным технический контроль качества: проверить ударения, имена, терминологию, особенно в русскоязычных сценариях, где автоматические модели иногда ставят ударение не туда. Для таких случаев полезна фонетическая подсказка в тексте и замена синонимов, чтобы речь звучала естественно, без дерганий. И еще момент — работа с акцентами и локалями, если у вас международная аудитория: разные голоса лучше заходят в разных регионах, и это легко проверить в коротких тестах. Так что выбор Synthesia — это не религиозный выбор, а прагматичная связка задач и возможностей.
Инструмент силен там, где вам нужен масштаб, многократное переиспользование и быстрая локализация, а не художественная постановка.
Чтобы не потерять нить, сформулирую критерии, по которым я включаю Synthesia в стек: частые обновления контента, единство формулировок, наличие нескольких языков, ограниченный бюджет на съемку и необходимость встроиться в автоматизацию. Если большинство пунктов совпало, смыслы сходятся и можно переходить к подготовке сценария и данных. А если нет, то лучше выбрать другую форму, и это тоже хорошее решение, потому что инструмент не обязан закрывать все возможные задачи. В любом случае synthesia видео чаще всего выигрывает у длинных текстов там, где нужна устойчивая подача и контролируемый темп, и этот выигрыш виден по метрикам просмотра и тестам на усвоение.
Если сомневаетесь, возьмите один короткий модуль на 60-90 секунд и сделайте две версии: с живым голосом и с цифровым аватаром. Сравните удержание и ответы на контрольные вопросы.
Микро-вывод простой: Synthesia беру, когда важны скорость, масштаб и локализация, а эмоциональная выразительность не критична. Дальше решают подготовка и аккуратность с данными.
Подготовка: сценарий, структура, данные и 152-ФЗ
Самая дорогая часть любого видео — переделки из-за недоговоренностей на старте, поэтому я начинаю с рамок: цель урока, целевая аудитория, ключевые действия после просмотра и метрика успеха. Это превращается в структуру из коротких сцен по 15-25 секунд, каждая со своим микросмыслом, чтобы правки были атомарными и не тянули за собой весь ролик. Текст читаю вслух и сокращаю лишнее, стараясь говорить просто и по делу, без официальных оборотов: учебное видео должно звучать как грамотный коллега, а не пресс-релиз, иначе зритель теряется. Визуальные элементы подбираю заранее: скриншоты, диаграммы, иконки, чтобы не зависеть от случайных картинок в момент сборки, и кладу их в понятные папки, чтобы n8n потом мог автоматом подтянуть их по именам. Если есть термины, имена, названия отделов и продукты, заранее готовлю глоссарий и фонетические подсказки в тексте, чтобы синтезатор голоса произносил корректно и не сбивал темп. И еще один важный шаг — проверка источников данных, особенно если мы упоминаем клиентов, кейсы и любую информацию, из которой можно восстановить персональные данные. Тут лучше перестраховаться: обезличивать, агрегировать, а если нужно — брать согласия и фиксировать их хранение, чтобы соответствовать 152-ФЗ и внутренним политикам безопасности.
По юридической части я использую белую зону данных: примеры анонимизированы, имена изменены, и нет биометрии без законных оснований и оформленных согласий. Если вы создаете кастомный аватар сотрудника и клонируете голос, юридическая чистота обязательна: договоренности с носителем, цели использования, срок и право на отзывание, плюс хранение аудиоматериалов в защищенном контуре. В крупной компании это обычно проходит через службу безопасности и юристов, и это нормально, потому что на выходе вы получаете устойчивый процесс, а не риск на ровном месте. С этической точки зрения я отмечаю, что в видео используется цифровой ведущий, и это снижает ожидания от эмоциональности и повышает доверие к форме, потому что зритель знает, чего ждать. И да, никакой магии: как только вы снимаете серые зоны с данными, проект дышит свободнее, а правки превращаются в технику, а не в поле для согласований. В подготовке еще важно договориться о языке: если у вас много регионов, уточняйте локальные термины, чтобы не звучать чужеродно, особенно в продажах и поддержке. В итоге у вас получается компактный пакет: цель, структура сцен, сценарий, визуальные элементы, юридические заметки и список ударений, который реально экономит часы в продакшене.
Хороший сценарий — это не талант, а дисциплина: одна сцена — один смысл, простой текст, проверка вслух и глоссарий для ударений.
Чтобы не закапываться, я делаю маленький контрольный лист из четырех пунктов: одна фраза про цель урока, перечень действий после просмотра, список терминов и риск-чек на данные. Если в этих четырех пунктах наступает ясность, сборка идет быстро, а версия 1.0 чаще всего превращается в версию 1.2 с небольшими правками, а не переписывается с нуля. Это и есть тот момент, когда можно открывать инструмент и переходить к процессу.
Пошаговый процесс сборки видео в Synthesia
Рабочий цикл начинается с создания проекта и выбора шаблона, где у нас уже есть разметка сцен, сетка шрифтов и стили заголовков, чтобы не изобретать визуальные велосипеды. Я открываю библиотеку, выбираю подходящий шаблон для обучения, или создаю с нуля, если нужно точное попадание в брендбук, и сразу задаю формат кадра, длительность сцен и общую палитру. Дальше идет выбор аватара и голоса: ориентируюсь на аудиторию и тему, чтобы голос не резал слух, а визуал не спорил с контентом, и тут полезно сделать быстрый превью нескольких фрагментов. Текст ввожу сценами, добавляя паузы и разбиение по фразам, чтобы синтетический голос дышал естественно, и проверяю ударения, особенно в русских фамилиях и технических терминах. На каждом шаге добавляю графику: скриншоты, обводки, подсказки, и ставлю мягкую фоновую музыку на минимальной громкости, если это не мешает, хотя часто оставляю тишину ради концентрации. После первичной сборки делаю черновой рендер и смотрю на темп: если сцены длинные, режу, если текст плотный, разбиваю, потому что усвоение выигрывает от коротких микросегментов. И только потом включаю анимацию входа-выхода элементов, чтобы не тратить время на украшения до тех пор, пока смыслы не сели на место, иначе правки становятся дорогими.
Чтобы процесс не превращался в ручной труд, я завожу именование файлов и сцен по паттерну, который потом подхватывает n8n: сцена_01_введение, сцена_02_шаг1 и так далее, а изображения складываю в папки по модулям, чтобы автомат мог собирать отчеты. Для многозадачности помогает дублирование проекта: на основе одного сценария делаю версии для разных регионов, меняю голос и локальные скриншоты, и у меня появляется набор роликов, которые отличаются только там, где действительно нужно. Перед финальным рендером запускаю пару внутренних просмотров: даю коллегам из функции, которую обучаем, посмотреть и отметить, где текст звучит слишком сложно, или где нужно добавить подсказку. По времени это быстрее, чем кажется: на вторую-третью итерацию уходит меньше часа, а на рендер можно спокойно поставить чайник, потому что здесь уже шанс больших правок минимален. Готовое видео экспортирую в нужном разрешении, даю осмысленные названия файлов, и сразу забираю статический превью-кадр, чтобы не тратить время на обложку позже. После чего отдаю ролику версию и фиксирую изменения в коротком changelog, чтобы через месяц не вспоминать, почему там именно так.
Пока смыслы не закрепились, не вкладывайтесь в эффектность — экономьте внимание на структуру, ударения и темп.
Небольшой переход: теперь у нас есть видео, и самое интересное — встроить его в контур автоматизации, чтобы оно не лежало мертвым грузом в папке, а работало в связке с каналами и LMS.
Автоматика вокруг видео: n8n, Make.com, LMS и Telegram
Когда ролик готов, я подключаю вокруг него простую, но полезную автоматику: n8n или Make.com собирают метаданные, переносят видео в нужные каталоги, обновляют карточку в LMS и уведомляют нужные каналы. Типовой поток выглядит так: загрузка финального файла в хранилище, парсинг имени и версии, создание записи в базе контента и публикация в нужные пространства знаний, чтобы люди не искали обновления в переписке. Вторая ветка делает разогрев: короткий анонс в рабочий Telegram с понятной формулировкой, кому смотреть и зачем, и ссылкой на модуль в LMS, а также ставит напоминание группе через неделю для тех, кто не дошел. Я люблю мягкий онбординг: не пинговать всех подряд, а работать по сегментам и событиям, например, если человек получил доступ к системе, но не прошел базовый модуль, то бот аккуратно напоминает и предлагает короткий пересказ. Третья ветка собирает метрики: выгрузка просмотров, прохождение теста и обратная связь, а n8n складывает все в единую таблицу, чтобы потом считать корреляции и строить графики. Технически это несложно, но важна дисциплина имен и версий, иначе автомату не за что зацепиться и начинается ручная работа, которой мы как раз хотели избежать. И еще я добавляю триггеры на обновления: если меняется регламент, появляется новая версия документа, или выходит релиз, автоматика ставит задачу на пересборку видео и пингует ответственную роль, чтобы не забыть.
Для интеграции с LMS полезно иметь единый идентификатор модуля, который живет дольше, чем видео, потому что ролики будут обновляться, а курс остается тем же. Здесь удобно связать карточку в LMS, хранилище файлов и запись в базе n8n по этому идентификатору, и тогда обновление становится простым: заменили файл, поправили changelog, все остальные точки подтянулись автоматически. Если вы ведете журнал анонсов, бот в Telegram может собирать варианты формулировок и делать ротацию, чтобы не повторяться дословно, и тут хорошо работает маленький языковой агент, который подставляет тезисы по шаблону. Отдельно отмечу приватность: если вы публикуете обучающие ролики с внутренними данными, держите раздачу по закрытым каналам и используйте аудит логов, чтобы не гонять ссылки наружу случайно. Удобно, когда у вас есть отдельная страница в базе знаний, где собраны все видео по теме с версионированием и короткими глоссариями — это снижает вопросы в чатах поддержки. И да, иногда n8n падает на странных файлах, так что я делаю резервный ручной сценарий — банальный чек-лист действий, который можно выполнить без автоматики, если вдруг ночь и никого нет на связи.
Если вы хотите посмотреть, как такие конвейеры живут в бою, я периодически разбираю кейсы и делюсь схемами в моем пространстве про автоматизацию — это блог на promaren.ru и спокойные заметки в телеграм-канале. Там без хайпа и без навязчивости.
Микро-вывод по автоматике простой: не нужно строить космический корабль, достаточно связать хранение, LMS, уведомления и сбор метрик, и у вас появляется цикл, где ролик живет, обновляется и измеряется. Далее остается мерить пользу и делать тонкие правки.
Качество и метрики: как понять, что видео работает
Я смотрю на эффективность через призму простых, но показательных метрик: удержание по сценам, доля досмотров, время до первого просмотра после анонса и результаты контрольных вопросов, привязанных к сценам. Если удержание падает на конкретной сцене, это сигнал, что там перегруз текста, сложная формулировка или неподходящий визуал, и правка делает чудеса без капитального ремонта. Второй слой — поведенческие метрики: сколько вопросов ушло в поддержку по теме после публикации и насколько снизилась доля ошибок, если это процессное обучение, и это легко смотреть по данным из тикет-систем, если наладить теги. Третий слой — опросы на 2-3 вопроса через пару дней: спрашиваю не про «понравилось», а про уверенность в выполнении конкретного действия и про то, что осталось неясным, чтобы поймать реальную боль. Для международных версий я сравниваю реакции и ударения: иногда достаточно заменить голос или упростить примеры, чтобы метрики вернулись в норму, и не надо паниковать. И еще я люблю A/B на коротком отрезке: две версии интро на 20 секунд, разные подачей, чтобы проверить, что лучше удерживает, и потом перетаскиваю победителя в основной модуль. Это не академическая наука, просто добросовестная гигиена контента, которая дает предсказуемое качество и спокойную совесть.
При анализе важно помнить, что синтетический ведущий — это инструмент, а не цель, и если он мешает восприятию в конкретной аудитории, лучше сделать озвучку без аватара или перейти на скринкасты с акцентом на действия. Внутренние метрики должны совпадать с внешними требованиями: если у вас есть обязательные модули по ИБ, проверяйте соответствие регуляторным формулировкам и версионирование документов, чтобы при аудите не бегать и не искать актуальную версию. Я держу маленькую таблицу соответствий: версия видео, версия политики, дата вступления в силу и ссылка на источник, чтобы все было прозрачно, без памяти на удачу. Когда метрики падают, я начинаю с простого: меняю разбивку текста, добавляю визуальный акцент и убираю лишнее, и только потом трогаю голос и аватара, потому что чаще всего дело в смыслах. Иногда помогает добавить краткие текстовые подсказки рядом с аватаром, чтобы глаз цеплялся за ключевые формулы, но тут важно не перегрузить кадр и оставить дыхание. Через пару циклов правок ролик стабилизируется, и дальше он просто живет с небольшими обновлениями по мере изменений в процессах.
Измеряем не красоту видео, а полезность: что человек понял, что сделал иначе и какие ошибки перестали повторяться.
Итого в микро-выводе: меряем удержание, поведение и уверенность, храним соответствия с документами и делаем правки на уровне сцен. Это держит качество на уровне без героизма и ночных марафонов.
Подводные камни и как их спокойно обходить
Первый камень — ударения и дикция на русском: синтетические голоса стали лучше, но все равно иногда ставят акценты не туда и путают фамилии, так что глоссарий с фонетикой и тестовый прогон спасают. Второй — избыточная анимация: хочется оживить кадр, но переездов и эффектов легко становится слишком много, и внимание уходит в декорации, а не в смысл, поэтому правило простое — меньше украшений, больше ясности. Третий — юридическая часть с кастомными аватарами и голосами: без согласий и понятных границ использования лучше не начинать, а при работе с внешними спикерами фиксируйте срок, площадки и право на отзыв, чтобы потом не чистить архив в панике. Четвертый — ожидания от эмоциональности: синтетический ведущий звучит ровно, и это плюс для усвоения, но минус для вдохновения, так что для мотивационных выступлений выбирайте живого спикера, а для инструкций — спокойно оставайтесь в цифровом формате. Пятый — интеграции: иногда LMS ведет себя капризно с кодеками и метаданными, поэтому держите опорные пресеты экспорта и не экспериментируйте в проде, а сначала тестируйте на коротком фрагменте. И конечно, помним про приватность: внутренние примеры обезличиваем, доступы ограничиваем, логи смотрим, чтобы не случились неловкости (у меня была такая попытка однажды, вовремя поймали).
Есть еще риск переспама: слишком много видео подряд, когда людям не до них, и тут помогает календарь и правило малых доз, чтобы не утомлять и не обесценивать важные модули. Я распределяю анонсы и ставлю «окно тишины», если параллельно идет крупное внедрение, и это дает лучший отклик, чем бомбардировка. Иногда из камней вылезает несовпадение языка и культуры в локалях: шутка, понятная в одном регионе, звучит странно в другом, поэтому нежные вещи убираю и держу нейтральный тон, чтобы не отвлекать. Визуально опасен перегруз мелким текстом на экране: зрителю сложно, если ему одновременно смотрят в глаза и показывают таблицу, поэтому я выношу таблицы в отдельные сцены и даю ведущему паузу. И наконец, синтетический голос лучше воспринимается с правильной скоростью: стандарт обычно ок, но я иногда замедляю на пару процентов для технических уроков, чтобы мозг успевал зафиксировать шаги. Эти мелочи убирают сопротивление и делают просмотр спокойным, а это как раз то, чего мы хотим от учебного видео.
Оставьте эмоции там, где они по делу, а инструкции сделайте чистыми и ритмичными — так люди меньше ошибаются и быстрее действуют.
Микро-вывод: большая часть рисков проясняется на старте и снимается дисциплиной сценария, юридической чистотой и тестами на коротких фрагментах. Дальше — техника.
Быстрый чеклист и приемы, которые себя окупили
Ниже — компактные шаги, которые я использую в каждом проекте, чтобы идти без зигзагов и не тонуть в деталях на поздних этапах. Они простые, но дисциплина в них дает тот самый эффект, когда ролики делаются предсказуемо и правятся без боли. Часть пунктов может показаться избыточной, но практика показывает, что именно они спасают, когда срочно приходит апдейт регламента или локальная команда просит версию на другом языке. Пусть это будет ваш рабочий лист, который лежит рядом и не дает сбиться, когда кофе остыл, а рендер пошел со второй попытки. Я иногда добавляю к ним свои пометки в скобках, если вижу, что команда начинает усложнять, хотя смысл не меняется. В общем, без пафоса, чистая польза.
- Цель и результат: сформулируйте одну цель модуля и одно действие, которое сотрудник должен уметь после просмотра, и повесьте это над сценарием.
- Структура сцен: разбейте материал на сцены по 15-25 секунд, один смысл — одна сцена, и проверьте текст вслух, убирая сложные обороты.
- Глоссарий и ударения: соберите список терминов, имен и сложных слов, добавьте фонетические подсказки в сценарий, чтобы голос не сбивался.
- Юридическая чистота: обезличьте примеры, проверьте согласия для кастомных аватаров и хранение исходников, зафиксируйте версии документов.
- Шаблон и стиль: выберите шаблон Synthesia, настройте шрифты и палитру под бренд, подготовьте набор типовых сцен для повторного использования.
- Мини-превью: соберите 2-3 сцены, сделайте тестовый рендер, проверьте темп и ударения, прежде чем собирать весь ролик.
- Интеграции и метаданные: задайте паттерн имен файлов и сцен, чтобы n8n или Make.com могли автоматически обновлять LMS и таблицы метрик.
- Сбор фидбэка: перед финалом дайте ролик 2-3 носителям темы, задайте им один вопрос: что непонятно и что вы бы сократили.
- Версионирование: зафиксируйте changelog, подключите напоминания на пересмотр при изменении регламентов или релизов.
- Локализация: для международных аудиторий сделайте короткие тесты с разными голосами и посмотрите удержание до 30 секунды.
Эти шаги закрывают 80% рисков и дают управляемый процесс, где synthesia генератор видео становится частью конвейера знаний, а не отдельным проектом со своей жизнью. Дальше остается просто работать по ритму и не усложнять, когда не требуется.
Короткое резюме без фанфар
Синтетический ведущий — это про скорость, единообразие и обновляемость, а не про трюки ради трюков, и в обучении эта тройка играет главную роль. Мы разобрали, как решить проблему долгих съемок и сложных согласований, используя сценную структуру, ясный сценарий и аккуратную работу с голосом, и почему именно это экономит недели в сопровождении. Synthesia дает удобный интерфейс, многоязычность и библиотеку шаблонов, а в паре с автоматизацией на n8n и Make.com превращает видео в элемент понятного конвейера: загрузка, публикация, уведомления, метрики и плановое обновление. Важные нюансы — ударения на русском, юридическая чистота с кастомными аватарами и отсутствие лишней анимации, которая крадет внимание, и здесь помогают глоссарий, тестовые прогоны и дисциплина версий. По метрикам я смотрю удержание, ответы на контрольные вопросы и снижение ошибок в процессах, а не абстрактные лайки, и это позволяет честно оценивать пользу и не спорить вкусовщиной. В быту это выглядит несложно: короткие сцены, простые фразы, предсказуемые шаблоны и ясные имена файлов, чтобы автоматика не спотыкалась, и один-два цикла правок для шлифовки. Если где-то осталась неопределенность, это нормально, я сама иногда правлю формулировки на втором круге и думаю: нет, лучше так — и от этого видео только выигрывает.
Спокойное приглашение для тех, кому откликнулось
Если хочется структурировать эти знания и посмотреть живыми глазами на рабочие схемы автоматизации вокруг обучающих роликов, я периодически разбираю кейсы и публикую разметки в своем спокойном пространстве про автоматизацию и AI-решения. Про жизнь инструментов, сценарии и нестандартные связки я пишу в блоге на promaren.ru, а короткие заметки и наблюдения выходят в моем телеграм-канале, где мы обсуждаем практику без магии и хайпа. Никакой гонки за вниманием, только рабочие вещи и немного иронии, чтобы легче дышалось в плотном графике.
Частые вопросы по этой теме
Можно ли полностью заменить живые обучающие видео на синтетические
Полностью — редко есть смысл, потому что мотивационные и культурные сообщения лучше звучат в живом формате. Синтетический ведущий идеален для инструкций, вводных, повторяющихся регламентов и модулей, где важны точность формулировок и частые обновления.
Как справиться с неправильными ударениями и сложными терминами на русском
Готовьте глоссарий с фонетическими подсказками и тестируйте короткие сцены до сборки полного ролика. Иногда помогает заменить слово синонимом, чуть перестроить фразу или выбрать другой голос, который лучше держит ударения.
Что с юридической стороной при создании кастомных аватаров сотрудников
Нужны оформленные согласия, четкие цели использования, срок и условия отзыва, плюс безопасное хранение исходников. Если данных достаточно для биометрии, соблюдайте требования 152-ФЗ и внутренних политик безопасности, и фиксируйте версии документов и видео.
Как встроить видео в существующую LMS без ручной рутины
Используйте n8n или Make.com для присвоения версий, загрузки файлов, обновления карточек курсов и публикаций анонсов. Дисциплина именования файлов и единый идентификатор курса делают процесс предсказуемым и безболезненным.
Подходит ли Synthesia для сложных демонстраций интерфейса
Да, но лучше как гибрид: цифровой ведущий для смысла и структура, плюс скринкасты для действий. Так вы сохраняете темп и ясность, а зритель видит именно то, что нужно нажимать и где искать.
Как определить оптимальную длину сцен и всего ролика
Сцены по 15-25 секунд помогают держать внимание и удобно править, а весь ролик лучше укладывать в 3-6 минут для одного микросмысла. Длинные курсы разбивайте на главы, чтобы сохранять ритм и управляемость.
Что делать, если аудитория международная и реакция на голос разная
Сделайте короткие A/B тесты на первых 30 секундах с разными голосами и темпами, и выберите по удержанию. Иногда разница в 5-10% решает судьбу всей локализации, и лучше поймать это на раннем этапе.