
Как различные подходы влияют на эффективность AI-агентов?
Когда я объясняю, как устроена память у моделей, мне удобно сравнивать её с рабочим столом и тумбочкой рядом. На столе только то, что нужно прямо сейчас — это контекстное окно. В тумбочке лежит всё остальное — это внешняя память. В этой статье разложу по полочкам, когда расширять стол, а когда лучше подкрутить тумбочку, чтобы не утонуть в бесполезных штуках и счетах за вычисления. Покажу, как строить сборки на n8n и Make.com, какие метрики считать и где обычно тонко. Поговорим про RAG, сокращение контекста и дисциплину данных без мистики и хайпа. Тон простой: шаги, схемы и чуть иронии. Цель одна — чтобы процессы делались почти сами, а мы возвращали себе часы. Текст ориентирован на тех, кто хочет понять, как работает AI в прикладных задачах и чем отличается контекстное окно от внешней памяти, не путая это с контекстным меню окна.
Время чтения: ~15 минут
- Контекст держать в голове или выносить в тетрадь
- Что умеет контекстное окно и почему оно не бесконечно
- Внешняя память как привычка хранить факты отдельно
- Где что работает лучше: задачи и сценарии
- Инструменты и сборка пайплайна на n8n и Make.com
- Процесс внедрения и метрики без иллюзий
- Подводные камни и лайфхаки выживания
- Практические шаги на неделю
- Частые вопросы по этой теме
Один вопрос на кухне офиса, который всё меняет
Ближе к вечеру я поймала себя за странной сценой: кофе остыл, ноут шумит, а в чате спор про то, что лучше для ИИ — дать ему больше контекста или научить вспоминать из базы. Дальше по списку классика жанра: кто-то приводит кейс с длинными документами, кто-то показывает, как агенты сами находят факты и шьют отчеты, третий спрашивает, как работает AI в целом и почему он забывает начало разговора. А я смотрю в логи и вижу знакомое: токены улетают, задержки растут, model начинает путать имена, а воронка задач простаивает. И вот тут я всегда останавливаю разговор и предлагаю честно измерить, где нам нужен большой стол, а где достаточно аккуратно устроенной тумбочки рядом. Не потому что красиво звучит, а потому что это реальные деньги и SLA. Да и психика команды дышит ровнее, когда процессы прозрачны, а метрики честные. Я за решения, которые можно повторить, проверить и поддерживать без чёрной магии и героизма по ночам, иначе зачем мы всё это затеяли.
С этого ракурса вопрос выглядит проще: есть контекстное окно — ограниченная рабочая область модели, куда мы кладем промпт, историю и дополнительные фрагменты. Есть внешняя память — все то, что модель достает из хранилищ на лету: векторы, БД, кэши, справочники, логи. В жизни эти подходы не конкуренты, а партнеры, но баланс между ними решает скорость, стоимость и качество. В одном проекте вы выигрываете от большего окна, в другом — от дисциплины данных и грамотного RAG. И да, есть соблазн запихнуть в контекст всё, что попалось, но это как завалить стол бумажками и удивляться, почему он трясется. Ниже разберем, где окно тащит, где память, и какими простыми шагами построить устойчивую систему на n8n и Make.com, не забывая про 152-ФЗ и белую зону данных. Кстати, не путайте контекстное окно с контекстным меню окна — последнее вызывается правой кнопкой мыши и к ИИ имеет отношение только через интерфейс, хотя вопрос как вызвать контекстное меню окна звучит в техподдержке регулярно.
Контекст держать в голове или выносить в тетрадь
Суть дилеммы без лирики
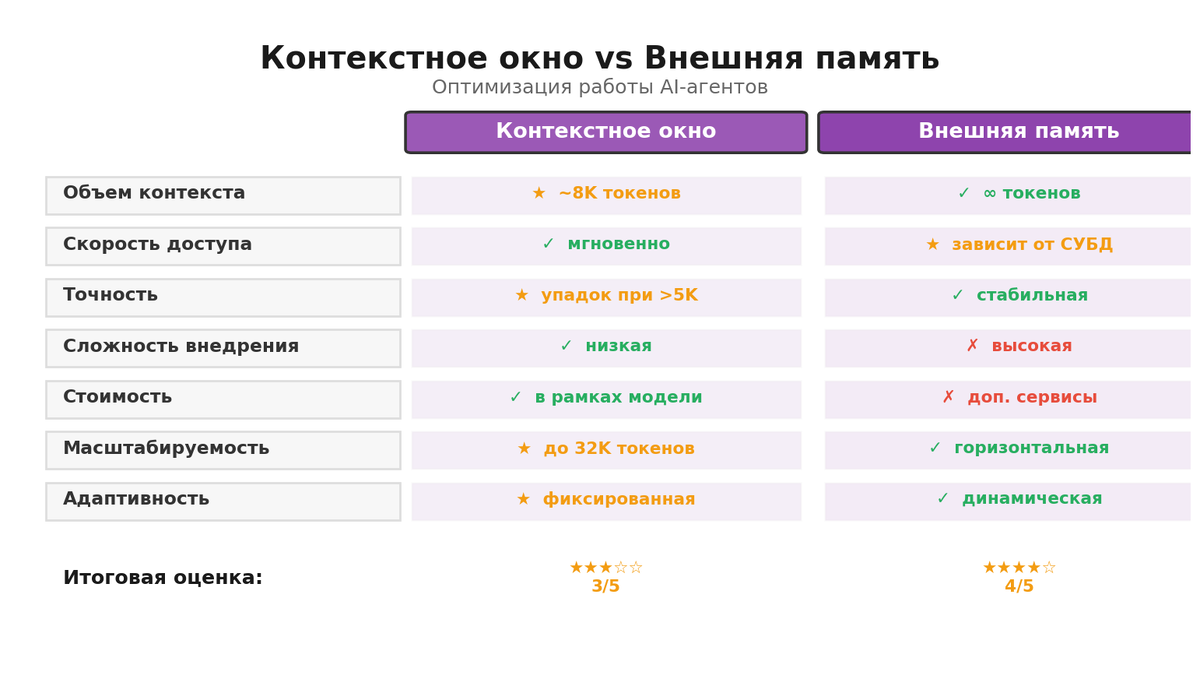
Если говорить строго, контекстное окно определяет объем токенов, который модель учитывает за один проход, и от этого зависит, насколько длинные документы, истории и инструкции она «держит в голове». Чем больше размер контекстного окна, тем реже мы теряем важные детали, особенно когда речь про разметку договоров, длинные чаты или анализ нескольких PDF подряд. Но расширение окна — это рост памяти, времени и счета, плюс эффект убывающей отдачи: добавили в три раза больше токенов, а качество выросло на проценты. Внешняя память решает обратную задачу: хранить много, отдавать мало и по делу, но появляется задержка на поиск и шанс промахнуться с релевантностью. В итоге спор не про идеологию, а про формулу: минимизируем токены в проходе и не теряем смысл. Если коротко, окно — про скорость ответа на уже положенные факты, память — про доступ к новым фактам в момент вопроса. Я не романтизирую ни один вариант, просто смотрю, где бутылочное горлышко и что быстрее чинится.
Почему это важно прямо сейчас
Модели растут, маркетинг шепчет про гигантские контексты, а бюджеты все равно считают минуты и мегабайты. К тому же живые задачи меняются: сегодня нам нужна ai оптимизация процессов в саппорте, завтра — оптимизация бизнеса с ai в логистике, послезавтра — ai оптимизация сайта по поиску и FAQ. Нельзя выбрать один паттерн и надеяться, что он прикроет все случаи, как универсальная отвертка. В реальности мы комбинируем: чуть расширяем окно, чтобы ответы были цельнее, и подключаем внешнюю память, чтобы знания были актуальными и проверяемыми. Плюс есть сценарии, где внешняя память обязательна по комплаенсу — хранить персональные данные внутри промпта никто не позволит, а внешние источники можно контролировать. И еще момент, про который часто забывают: как работают AI агенты для бизнеса зависит не только от модели, но и от инфраструктуры вокруг — индексы, кэши, очереди, мониторинг. Эти скучные вещи решают, будет ли агент помогать людям или он опять «думает» по три минуты.
Зрелая система — это не бесконечное окно и не «всезнающая» память, а договоренности: что хранить, что подгружать и что выбрасывать без жалости.
Что умеет контекстное окно и почему оно не бесконечно
Как устроено окно на практике
Контекстное окно LLM — это общий бюджет токенов на вход и выход, и в него приходится вмещать всё: системные инструкции, историю диалога, пользовательский запрос и любые вставки. Расширять окно можно, но цена понятна: растут задержки и потребление, а локальные развёртывания упираются в память GPU или CPU. Я видела, как команды радуются при переходе на «большое окно», а потом выключают половину логирования, потому что времени на одно сообщение стало уходить больше, чем на ручной разбор письма клиента. Есть техники, которые помогают жить экономнее: сегментация истории, фильтрация несущественных сообщений, рекап краткими саммари, Selective Context и другие способы убрать избыточность. Встречный риск — слишком сжали и потеряли цепочки фактов, и модель начинает отвечать красиво, но мимо сути. Поэтому я всегда поднимаю вопрос метрик: какой процент токенов уходит на «обязательные» части, какой — на сам вопрос и какой — на полезные вставки. Без этого разговор про контекстное окно превращается в кофейную философию.
Где окно сильнее памяти
Есть сценарии, в которых большие окна объективно лучше: длинные юридические документы, исследовательские заметки, протоколы совещаний с перекрестными ссылками, сложные промпты с таск-листами для агента. В таких задачах окно даёт цельность — модель не теряет нить, видит табличные сноски и не натыкается на холодный вызов внешней памяти в середине рассуждения. Даже в диалогах поддержка чувствует разницу: меньше повторы, меньше «напомните детали», больше вкусных ответов с первого раза. При этом стоит не путать: когда люди спрашивают про контекстное окно GPT, контекстное окно LLM или deepseek контекстное окно, они часто имеют в виду общий принцип, а не конкретный маркетинговый размер. Да, иногда мелькают фразы вида контекстное окно gpt 5 — я бы относилась к таким обещаниям спокойно и проверяла реальными замерами. Бумага терпит всё, а вот инвойс от облака — не очень.
Важно не путать термины: «контекстное окно» — это про память модели, «контекстное меню окна» — элемент интерфейса, который вызывает пользователь. Смешение этих понятий приводит к комичным тикетам в техподдержку, я видела такое не раз.
Ограничения, о которых лучше помнить
Даже при большом окне модель не становится архивом и не обязана помнить всё, что вы ей скормите. Внутри работает внимание на фрагментах, плюс есть позиционное кодирование, из-за которого дальние части контекста могут терять точность. Методы позиционного расширения и параллелизма помогают, в индустрии появляются решения уровня Helix Parallelism, которые эффективнее используют железо. Но даже с этим, если вы подаете плохо структурированный текст и не делаете нормальную разметку, окно тратится на мусор. Поэтому для длинных документов я предпочитаю строгую схематику: разбивка на семантические блоки, явные маркеры секций, оглавление в начале промпта и сжатие повторов. Чуть больше усилий на подготовку — и окно работает как хороший стол: все под рукой, но ничего лишнего. И да, если вы работаете с чувствительными данными, не забывайте, где они у вас оказываются — в логах, в истории, в отладочных демо. Тут уже включается white-data-зона и требования 152-ФЗ, без компромиссов.
Внешняя память как привычка хранить факты отдельно
Что я называю внешней памятью
Внешняя память — это весь слой за пределами окна: поисковые индексы, векторные базы, реляционные БД, KV-кэши, файловые хранилища, графовые БД. В популярном паттерне RAG модель не «знает» всего, а запрашивает фрагменты по релевантности: мы кодируем документы в эмбеддинги, храним, а на запрос выдаем 3-8 лучших кусочков. Этот подход масштабируется, даёт контроль версий и отлично обновляется без переподготовки модели. Но он добавляет задержку и требует дисциплины данных: нормализация, дедупликация, обновление индексов, контроль стоп-слов и валидаторы качества. Я обычно использую Postgres с pgvector или Qdrant, плюс аккуратные пайплайны на n8n и Make.com для загрузки, очистки и пересчета эмбеддингов. Еще пригодится кэш на популярные вопросы, иначе трафик векторного поиска съедает время на ровном месте. Если коротко, внешняя память — это не «прикрутили базу», это отдельный продукт внутри вашего решения.
Когда память выигрывает у окна
Если у вас растущий корпус знаний, живые данные и требования к отслеживаемости, внешняя память незаменима. Клиентская база, тарифы, графики поставок, справочники по продукту, внутренние регламенты — все это меняется чаще, чем релизы моделей. Вы не сможете держать актуальность, просто расширяя окно, оно не для этого. Память хорошо работает там, где нужен быстрый доступ к узким фактам и источнику правды: ссылка на документ, версия, дата, автор. Плюс появляется объяснимость: откуда модель взяла ответ, какие кусочки контекста использовала, что можно перепроверить. Для аудита и ИТ-рисков это золото, извините за эмоцию. Отдельным бонусом идет комплаенс: персональные данные и коммерческую тайну вы храните в контролируемых хранилищах, а не таскаете через промпты. Тут и 152-ФЗ, и внутренняя политика безопасности вздохнут спокойнее.
Внешняя память — это про доверие к ответу: источник виден, версия известна, а обновление происходит без пересборки всей системы.
Что может пойти не так
Память любит порядок. Если вы кормите индекс разнородными документами без разметки, будете страдать от нерелевантных фрагментов. Если забываете пересчитывать эмбеддинги после обновлений, получите «призраков» — ответы на основе старых версий. Если не делаете кэширование, покупаете лишнюю секунду задержки на каждом вопросе, а это чувствуется в потоке. Ошибки чаще всего не в модели, а в окружении: просроченные индексы, плохие правила разрезки текста, отсутствие контекстных подсказок в промпте, которые помогают модели правильно встроить найденные фрагменты. Тут помогает простая дисциплина: расписания обновлений, канареечные индексы, быстрые smoke-тесты релевантности и прозрачная телеметрия. Да, скучно, зато предсказуемо.
Где что работает лучше: задачи и сценарии
Длинные документы, отчеты и юридические тексты
Для многостраничных документов расширенное контекстное окно даёт чувство цельности: модель видит таблицы, примечания, перекрестные ссылки и понимает логику от начала к концу. Я добавляю в начало промпта шапку с якорями секций, делаю сжатые саммари по главам и оставляю в окне только нужные кусочки, выстраивая их в правильном порядке. Если документ огромный, комбинирую: часть кладем в окно, часть достаем из внешней памяти по ссылкам, чтобы не держать лишнюю массу. В отчетах и разметке юридического массива это спасает и деньги, и нервы, особенно когда сроки вчера, а перепроверка обязательна. И да, не забывайте про токен-эллининг: таблицы переводим в компактный текст, повторяющиеся преамбулы выносим в ссылки, а не в лоб кладем в промпт. Делать меньше, но умнее — хороший принцип.
Поддержка, поиск и сайт
В поддержке и на сайтах почти всегда выигрывает внешняя память плюс аккуратный промпт. База знаний растет, а модель учится извлекать ровно то, что нужно. Это даёт ощутимую ai оптимизация сайта: быстрый поиск по FAQ, подсказки в форме, автогенерация ответов с цитатами источников. В связке с CRM и тикетами удобно держать историю клиента вне окна, а в самом ответе использовать краткие фрагменты, отобранные векторным поиском. И ещё одна бытовая деталь: если вы храните шаблоны и гайды в версии, проще объяснить, почему вчерашний ответ отличался от сегодняшнего — менялась база, а не характер модели. Внутренние агенты поддержки отлично работают на RAG, окно им нужно только для логики диалога и инструкций. Результат — меньше шансов на галлюцинации, меньше «простыней» в промптах и лучше объяснимость.
Маршруты, логистика и планирование
В задачах маршрутизации модель не должна «знать» всю карту мира, ей нужен доступ к актуальным данным. Поэтому оптимизация маршрутов с помощью AI строится на внешних источниках: графы дорог, окна доставки, ограничения по тоннажу, пробки. Мы подготавливаем данные, делаем хороший solver или агент, который поднимает нужные факты на лету, а окно тратим на постановку задачи и правила выбора. Здесь большой контекст будет медленной роскошью, а вот чистая память и быстрый поиск — тот самый усилитель. В реальном проекте у меня n8n с третьей попытки перестал падать на этапе агрегации расписаний, после чего задержка упала на 40 процентов, а водитель перестал звонить диспетчеру каждые полчаса. Ошибочка в конфиге была смешная, но эффект на цепочку — огромный.
Окно — про логику и цельность, внешняя память — про факты и актуальность. Разделяйте и побеждайте.
Инструменты и сборка пайплайна на n8n и Make.com
Базовая архитектура
Типовая схема выглядит так: сбор данных — очистка и нормализация — нарезка на фрагменты — эмбеддинги — индекс — кэш — служебные метрики. На n8n удобно строить ETL: вход из Google Sheets, Яндекс Облако, S3-совместимые хранилища, файловые папки, CRM и 1С. Дальше цепляю обработку текста, парсинг PDF, удаляю повторы, отмечаю заголовки. Эмбеддинги считаю батчами, кладу в Postgres с pgvector или в Qdrant, а в Make.com строю тонкие сценарии для контентных обновлений и кросс-интеграций, где важна человеческая логика с правилами. Исходящие ответы идут в чат-боты, формы на сайте, почту, мессенджеры. Внутри промпта оставляю роль, стиль, краткую историю и вставки-факты из памяти. Даже при приличном окне стараюсь класть только то, что точно нужно для конкретного шага — меньше токенов, меньше сюрпризов.
Тонкости промптов и кэшей
Промпт не должен превращаться в склад. Делаю короткую шапку-роль, явные правила ответа, формат вывода и несколько проверок на источники. Историю диалога держу не лентой, а саммари с ключами, добавляю маркеры задач для агента. Внешняя память подгружает 3-6 фрагментов, а для популярных запросов включаю кэш на уровне индекса или приложений. Результаты, которые пригодятся другим, кладу в KV-кэш на короткое время, чтобы не дергать поиск. Дополнительно создаю «черный список» фраз, которые вызывают лишние блоки документов, чтобы не засорять окно очевидным. Если задать простые правила, токен-экономика станет предсказуемой, а агент перестанет паниковать и забывать, где он был минуту назад. Глупо, но приятно, когда ответ прилетает быстро и без фокусов.
Российские реалии и инфраструктура
Из практики хорошо живут Postgres с pgvector, Qdrant, ClickHouse для логов, очереди RabbitMQ или Kafka, и S3-совместимые хранилища для сырья. В облаках смотрим на зоны хранения и обработку персональных данных, чтобы не вывалиться за периметр. Логи и метрики держим на своем, потому что white-data-зона — это не лозунг, а привычка. Инструменты разные, принципы одинаковые: чистые данные, предсказуемые пайплайны, нотации и версии. Если вдруг вы экспериментируете с интерфейсами вроде Cursor или Google AI Studio, помните, что как работать с Cursor AI и google ai studio как работать — это про удобство песочницы, а не про архитектуру памяти. Важно, как работает AI-ядро в вашей задаче и что вы делаете вокруг него: кэш, индексы, промпт-инжиниринг, мониторинг. Тут романтика заканчивается, начинается ремесло.
Процесс внедрения и метрики без иллюзий
Как собирать прототип без боли
Начинаю с узкой задачи и короткого потока данных. Описываю вход, выход и ограничения, формулирую допуски по качеству и скорости, а потом строю первую версию: минимальный промпт, небольшой индекс, простая логика агрегации. Дальше прогоняю набор тестов: эталонные вопросы и ответы, заведомо сложные случаи, пустые и конфликтующие данные. Меряю долю попаданий, среднее время и распределение задержки, стоимость на одну сессию, размер окна и долю вставок от внешней памяти. Если вижу, что окно «пухнет», ищу, чем его заменить: саммари, пересбор, кэш. Если промахи в релевантности, чиню разрезку и скоринг векторами, иногда меняю модель эмбеддингов. Этот цикл может казаться скучным, но он честно показывает, где деньги и качество утекают. Я не продлеваю страдания команд, мы быстро доводим систему до стабильного уровня и только потом расширяем ее на соседние задачи.
Какие метрики работают на земле
Мне помогают несколько простых величин: токены на запрос и ответ, токены на «обязательную часть», доля вставок из памяти, попадание в эталон по смыслу, задержка p50 и p95, и стоимость на тысячу запросов. Для агентов добавляю шаги в цепочке, глубину рассуждения и число обращений к памяти на одну задачу. Отдельно считаю долю «пустых» вставок, когда поиск возвращает релевантные по форме, но бесполезные по сути фрагменты. Визуально это видно в логах, а в цифрах помогает бальная шкала с ручной разметкой на небольшой выборке. И да, метрики качества — это не только автоматические оценки, иногда нужен человеческий взгляд. Глаз наставника спасает от красивых графиков, за которыми прячется странная логика. Я всегда выделяю час в неделю на разбор нескольких кейсов руками, иначе система начинает жить «в вакууме».
Метрики — ваши очки. Без них каждая гипотеза выглядит правдой, пока не ударит по счёту за вычисления.
Про данные и закон
Если в вашей задаче присутствуют персональные данные, сразу договоритесь, где они находятся в каждый момент времени. Пользовательский вход, лог, очереди, индекс, кэши, ответы — проверьте всё и зафиксируйте. В окне держите только то, что необходимо для обработки запроса, лишнее не таскайте. Внешнюю память стройте на хранилищах с понятной зоной данных, правами доступа и аудитом действий. Анонимизация и маскирование — не опция, а привычка. И еще один момент: ревизии и версии документов не просто «для порядка», а для объяснимости и проверок. Когда вы знаете, откуда пришел фрагмент, проще ответить на любой вопрос безопасности. Тут без шуток, я предпочитаю скуку в обмен на предсказуемость, и команда потом благодарит.
Подводные камни и лайфхаки выживания
Типовые ошибки
Первое — «всё класть в промпт». Это дорого, медленно и ломает качество на длинных цепочках. Второе — «один индекс для всего». Разные домены требуют разных стратегий разрезки и скоринга, иначе релевантность качает. Третье — отсутствие кэшей и правил фокусировки, из-за чего на простые вопросы тратится столько же ресурсов, сколько на сложные. Четвертое — слепая вера в размер окна или в магию эмбеддингов: и то, и другое работает только в контексте процесса. Пятое — игнор истории запросов: частые вопросы можно выносить в ускоренные пути, не дергая память каждый раз. И последнее — романтика без измерений, когда тесты «на глазок» заменяют реальную валидацию. Тут я иногда вздыхаю, делаю глоток холодного кофе и включаю режим терпеливого аудитора.
Полезные приемы
Работают простые вещи: структурируйте вход на уровне формы, просите пользователя указывать тип задачи и источники, используйте явные маркеры для ключевых фрагментов. Настройте тройку индексов для разных типов контента и держите метатеги рядом с текстом. Делайте канареечные обновления и периодически проверяйте топ ответов вручную, иначе промахи будут копиться. Используйте короткие саммари вместо длинной истории, когда видно, что диалог уходит в сторону. Добавляйте кэш на уровне вопросов, а не ответов, если важнее стабильная релевантность, чем формулировка. И всегда имейте аварийный путь ответа: «Я не нашла точного фрагмента, вот два близких документа» — это честнее и полезнее, чем красивый, но неверный текст.
Простое правило: если вы сомневаетесь, класть ли фрагмент в окно, спросите себя, будет ли без него ответ логически неполным. Если нет — в память.
Практические шаги на неделю
Чтобы не оставлять разговор в теории, вот короткая программа, как сделать, чтобы работал c AI ваш сценарий без лишнего шума. Она не претендует на энциклопедию, но помогает быстро увидеть эффект и найти узкие места. Да, местами захочется углубиться, я подумала, нет, лучше так — шаг за шагом и без спешки. Список не заменяет архитектуру, но даёт нормальный старт.
- Карта задачи. Запишите 5-7 типовых запросов, желаемые ответы и ограничения по времени. Отдельно отметьте, где нужны ссылки на источники и версии документов.
- Мини-инфраструктура. Поднимите простую векторную базу: Postgres + pgvector или Qdrant. Настройте два индекса: для длинных статей и для справочников коротких фактов.
- Подготовка данных. Сделайте разрезку текстов с явными заголовками, удалите повторы, добавьте метатеги источник-версия-дата. Прогоните эмбеддинги батчами, сохраните контрольный отчёт.
- Промпт и окно. Соберите шапку роли, формат ответа и короткую историю в 5-7 предложений. Вставляйте из памяти только 3-6 фрагментов с пояснением их роли в ответе.
- Кэш и замеры. Включите кэш популярных вопросов, соберите p50/p95 задержки, токены на запрос и на ответ, долю вставок из памяти. Отметьте 3 гипотезы, что улучшить.
Спокойная точка в конце страницы
За годы внедрений я перестала ждать от моделей чудес и стала ценить аккуратные системы. Контекстное окно — это про ясную голову модели здесь и сейчас, где важно удерживать нить и не разваливаться на длинных задачах. Внешняя память — про факты, источники и актуальность, где важнее достоверность и контроль версий, чем скорость одного шага. Вместе они дают устойчивость: окно держит логику, память кормит фактами, а сборка на n8n и Make.com клеит это в понятный поток. Чтобы такую систему обслуживать, нужны метрики, дисциплина данных и привычка измерять токены, задержки и попадание в эталон, а не спорить, чья «магия» сильнее. Где-то вы расширите окно и сразу почувствуете пользу, где-то выключите лишние вставки и выиграете в скорости, а где-то перестанете тащить в промпт всё подряд и получите больше, делая меньше. Ничего героического, просто ремесло и бережное отношение к ресурсам. Если дорожить временем команды и прозрачностью процессов, ai оптимизация в реальной жизни перестает быть лозунгом и начинает работать как обычная хорошая инженерия.
Продолжение разговора
Если хочется структурировать эти знания и увидеть рабочие сборки, я регулярно разбираю такие кейсы в своём пространстве заметок и примеров. В заметках на сайте promaren.ru можно спокойно посмотреть, чем я занимаюсь и как подхожу к автоматизации без лишних обещаний. А в моём телеграм-уголке t.me/promaren чаще появляются разборы нестандартных AI-решений и заметки по n8n и Make.com, которые пережили прод. Для тех, кто готов перейти от теории к практике, такие материалы обычно становятся картой местности, где видно, что улучшать завтра утром. Никакой гонки, только шаги, которые экономят часы.
Частые вопросы по этой теме
Как понять, что пора увеличивать размер контекстного окна, а не подключать внешнюю память
Признак простой: ответ рвётся на куски, модель теряет нить диалога, а нужная информация уже у вас «на столе». Если же не хватает фактов, источники часто обновляются и требуются ссылки, лучше двигаться в сторону памяти и RAG. Иногда выигрыш даёт гибрид: короткое окно с сильной дисциплиной вставок.
Что делать, если ограничение контекстного окна не позволяет положить весь документ
Разбивайте документ на семантические блоки, делайте саммари по главам и подавайте только релевантные фрагменты. Остальное храните во внешней памяти и подтягивайте по ссылкам. Это быстрее, дешевле и часто точнее, чем пытаться запихнуть всё в один проход.
Как работают AI агенты, и влияет ли на них окно
Агенты — это цепочки действий с логикой планирования, и им важно и окно, и память. Окно держит план и текущий шаг, память подает факты и контекст задачи. Чем лучше вы разделите эти роли, тем меньше «блужданий» и повторов в цепочке.
В чём разница между контекстным окном нейросети и контекстным меню окна
Контекстное окно нейросети — это бюджет токенов, который модель учитывает при ответе. Контекстное меню окна — элемент интерфейса, который пользователь вызывает, например, правой кнопкой мыши. Совпадение в словах, но области вообще разные.
Нужно ли гнаться за модными размерами, например «контекстное окно GPT» или «deepseek контекстное окно»
Смотрите на метрики вашей задачи и стоимость. Большое окно полезно для длинных последовательностей, но без дисциплины данных легко получить потери по скорости и бюджету. Любые заявления про «контекстное окно gpt 5» я бы проверяла только тестами на ваших кейсах.
Если мы используем разные интерфейсы и студии, это меняет подход
Нет, фундамент один и тот же: экономия окна, аккуратные вставки из памяти, кэш и измерения. Неважно, где вы экспериментируете — open ai как работает, google ai studio как работать, kling ai как работать или как работает galaxy ai — логика памяти и окна остаётся той же. Интерфейс помогает, архитектура решает.
Как работать с AI так, чтобы система не расползалась по сложности
Фиксируйте правила: что держим в окне, что в памяти, как кэшируем, как валидируем и как мерим качество. Делайте короткие итерации и добавляйте сложность только после стабилизации. Тогда ai оптимизация процессов происходит не за счет чудес, а за счет простых и повторяемых шагов.