🧨 Kimi представили новую модель - Kimi-Linear-48B-A3B-Base
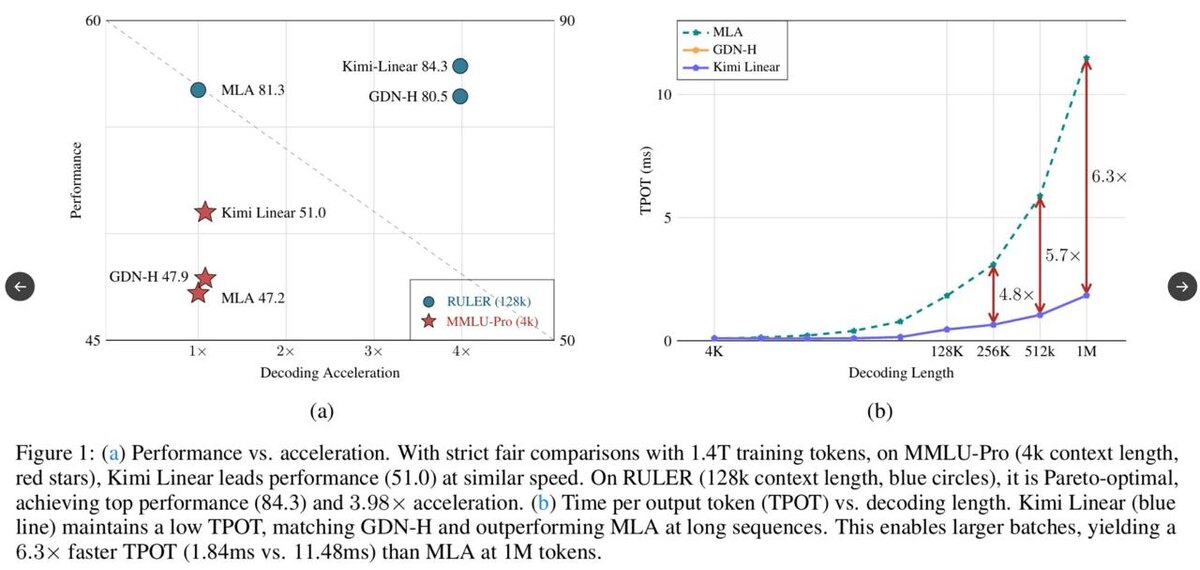
Модель хороша тем, что даёт почти уровень больших LLM на длинных контекстах, но при этом заметно экономит память и работает быстрее за счёт линейной архитектуры.
Что улучшили:
- требует до 75% меньше памяти на KV-кэш
- до 6.3× быстрее декодирование на длинных контекстах
Как устроена:
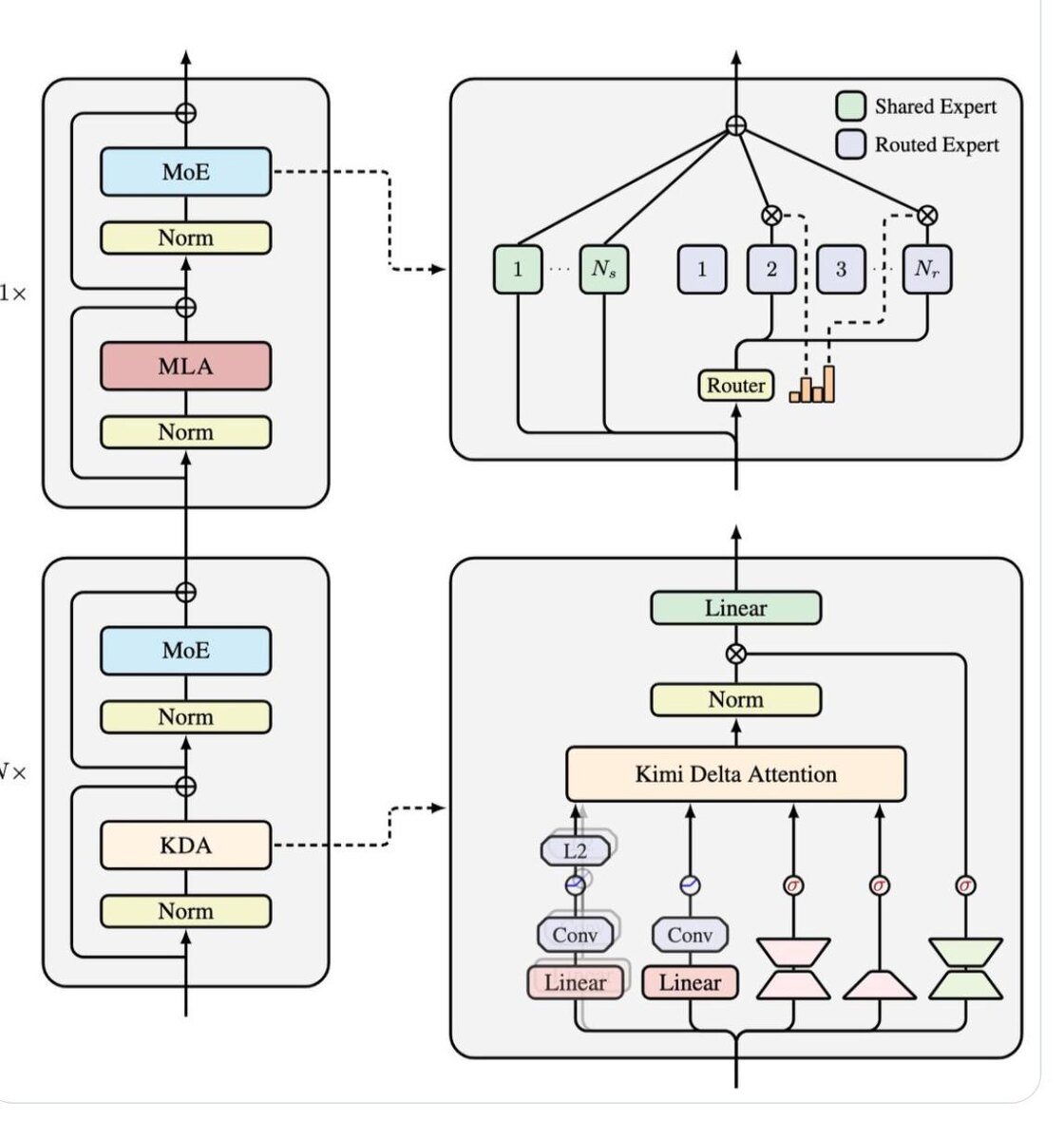
- гибридный подход: Kimi Delta Attention + MLA
- модель хорошо оптимизирована под длиннный контекст и высокую пропускную способность
По бенчмаркам модель обгоняет и MLA, и GDN-H, включая задачи с длинным контекстом. В задачах на рассуждения и длинную RL-генерацию Kimi-Linear показывает заметно лучшие результаты, чем MLA.
Архитектура модели пример того, как линейные attention-архитектуры выходят на уровень, где они конкурируют с классическими решениями не только по скорости, но и по качеству.
🟠Github: github.com/MoonshotAI/Kimi-Linear
🟠Hf: https://huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Instruct
#Kimi #llm