
Собирайте данные с любых сайтов за считанные минуты
Я часто слышу фразу: парсинг сайта — это сложно и только для тех, кто дружит с Python. Я улыбаюсь, ставлю чайник и открываю n8n. Визуальный конструктор, где узлы соединяются линиями, а данные текут как вода в прозрачных трубках, снимает половину страха. В этой статье разберу, как я собираю структурированные данные без кода: новости, карточки товаров, цены конкурентов и Telegram-посты с открытых источников. Поговорим про законность, про 152-ФЗ и этику white-data, про устойчивость и как не упереться в капчу ночью. Если вы уже автоматизируете бизнес-процессы и хотите сократить ручной труд, вам будет комфортно. Если вы совсем новичок, тоже найдется опора: я даю простые шаги, а не магию за стеклом. И да, у меня n8n парсинг заработал с третьей попытки, потому что кэш и куки — вещь упрямая.
Время чтения: ~15 минут
- Почему вообще нужен парсинг без кода
- Что именно решает n8n в задаче сбора данных
- Инструменты и узлы, на которые я опираюсь
- Пошаговый процесс: от URL до таблицы
- Что получается на выходе и как это использовать
- Подводные камни и как я их обхожу
- Практические советы и мини-чеклист
- Частые вопросы по этой теме
Иногда я ловлю себя на привычке не читать новости вручную, а ждать, пока в табличке обновится дата и заголовок. Это уже не лень, это рациональность: когда парсинг данных с сайта настроен однажды, мозг освобождается для анализа и принятия решений. Похожая история с товарами и ценами: раньше делала срез раз в неделю, теперь у меня обновление каждый час и тревожные уведомления, если кто-то сильно сдвинулся. Мы живем в экосистеме, где скорость важнее пудры, а аккуратность важнее пафоса. Я стою за white-data, за честные метрики и прозрачные процессы, поэтому n8n для меня как швейцарский нож для офисных автоматизаций. Он не красивее всех на рынке, но он понятен, воспроизводим и не требует глубокого кода. А если нужна аналитика на уровне смыслов, то подключается ИИ и дополняет картину, не перетягивая одеяло. И да, если на сайте есть RSS, я сначала беру RSS, а прямой парсинг оставляю на случай, когда других вариантов нет.
Почему вообще нужен парсинг без кода
Мне часто пишут с одинаковым запросом: надо регулярно собирать информацию из открытых источников, руками уже тяжело, а бюджет на разработку ограничен. У каждого свой контекст: кому-то нужен парсинг сайтов конкурентов, кому-то нужно тянуть карточки товаров и доступность, кому-то важен парсинг веб сайтов СМИ для мониторинга упоминаний. Общий знаменатель один — повторяющиеся действия, которые лучше отдать машине. Я вижу две точки приложения усилий: оперативный контроль и историческая аналитика. Для первого важны скорость и триггеры, для второго — чистота данных и стабильность выгрузки. И здесь автоматизация на визуальном конструкторе экономит часы: выстраиваешь узлы, настраиваешь расписание, а дальше система бежит сама. При этом я всегда смотрю на правовую сторону и robots.txt: где-то данные брать можно, где-то лучше запросить API, а где-то, простите, не надо.
Сценарии, где выигрыш особенно заметен
Если коротко, то я люблю задачи, где вход структурируем, а выход помещаем в таблицу или базу. Это n8n парсинг новостей в медиа-мониторинге, загрузка прайсов и остатков, сбор отзывов с открытых страниц магазинов, выгрузка новых вакансий и кейсов. Часто встречается парсинг товаров с сайта с последующей нормализацией цен и категорий, где помогает простой узел Set и немного регулярных выражений. Бывают проекты с Telegram, и там уместен аккуратный парсинг телеграм n8n через бота, без попытки лезть в закрытые чаты. Для интернет-ресурсов с RSS я не спорю со здравым смыслом: если лента есть, берём её, это надёжнее и быстрее. Когда же RSS нет, работаем с HTML и, если нужно, с динамикой через браузерные узлы или внешние сервисы рендера. В любом случае я держу курс на белую зону и минимальные риски для клиента.
Что важно учесть до старта
Перед тем как тянуть HTML, я делаю мини-аудит: есть ли публичный API, чист ли источник с точки зрения 152-ФЗ, не тянем ли мы персональные данные, как ведёт себя robots.txt. Затем прикидываю частоту и объём: раз в сутки или раз в 10 минут, 100 карточек или 100 тысяч. От этого зависит архитектура пайплайна и аккуратность лимитов. Важная мелочь — целевой формат: CSV, Google Sheets, Notion, Postgres или просто JSON-архивы. Чем раньше это проговорить, тем меньше переделок и странных ручных патчей потом. И последнее — кто будет сопровождать: если это команда без разработчиков, делаю узлы максимально прозрачными и подписанными по смыслу. Даже если кофе остыл, а n8n упорно не видел один атрибут, я не сдаюсь — просто меняю селектор, проверяю сэмпл и иду дальше.
Белый парсинг — это не техника, а позиция: брать только открытое, уважать правила сайта и не заливать сервер из пушки.
Что именно решает n8n в задаче сбора данных
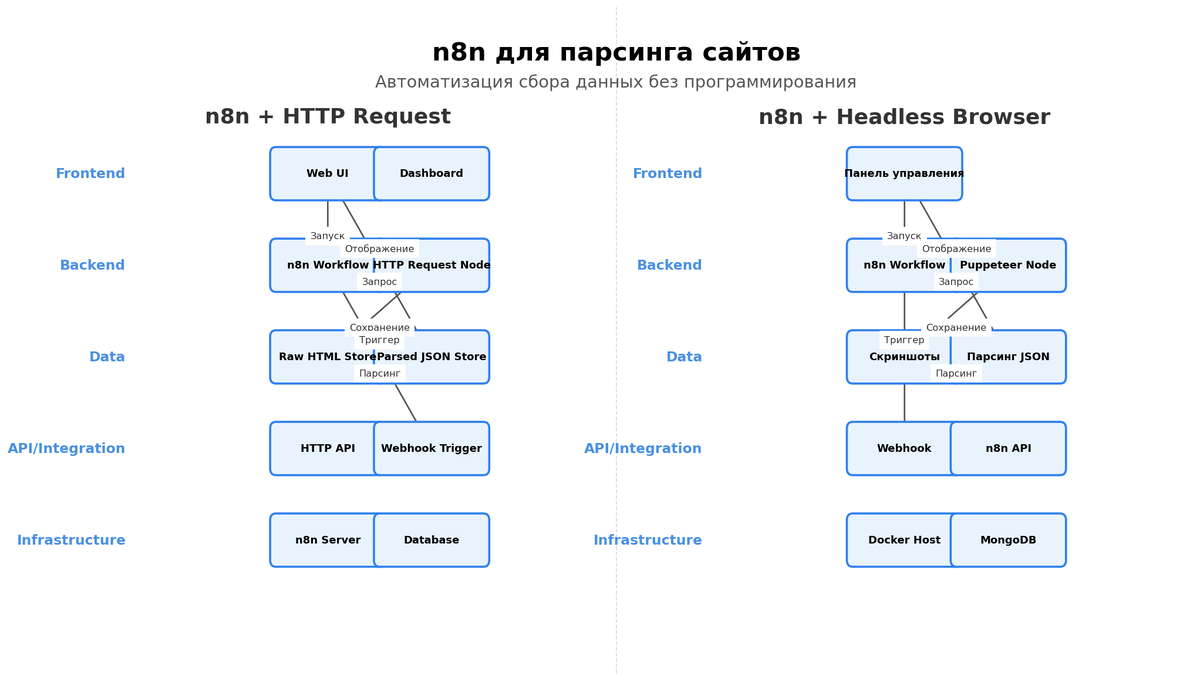
n8n — это визуальный редактор процессов с открытым исходным кодом, который стабильно закрывает типовые задачи получения и обработки данных. У платформы больше 400 интеграций, что для меня означает не просто разнообразие, а возможность собрать конвейер без внешних костылей. Где-то я беру HTTP Request и HTML Extract, где-то включаю Google Sheets, Telegram и ИИ узлы для нормализации текста. Важно, что вся логика в узлах видна и повторяема: любой член команды может открыть воркфлоу и понять, что за чем. Если сравнивать с конкурентами, у Make.com больше готовых коннекторов, у Zapier привычнее интерфейс, у n8n гибкость и возможность тонкой кастомизации. По последним открытым данным сообществ, у n8n активная база пользователей растёт, и это показывает, что платформа не нишевая, а вполне мейнстрим. Для корпоративных сценариев мне нравится, что его можно развернуть локально и жить спокойно, соблюдая требования по данным.
Чем n8n удобнее готовых парсеров
Есть программы специализированные, которые обещают бесплатный парсинг сайтов или даются как программа для парсинга сайтов из коробки. Они хороши, пока вы в рамках их шаблонов, а когда нужно что-то особенное, начинаются ограничения. В n8n я сама выбираю стратегию: RSS где доступно, прямой HTML там, где нужно, а для динамических страниц подключаю рендер. Важная деталь — обработка ошибок: можно ловить коды ответов, ретраить, ставить паузы и вести лог. Это сильно снижает ручные вмешательства и делает процесс живучим ночью и в выходные. А ещё я люблю визуальное ветвление: условия, фильтры, ветки для разных результатов, это экономит время анализа. Профессиональная деформация, конечно, но мне спокойнее, когда вижу весь поток данных в одном окне.
Где граница с классическим кодом
Я не буду спорить, что парсинг сайтов на Python даёт максимум гибкости, а парсинг сайтов питон откроет любые двери. Но не во всех проектах это оправдано. Если у вас 5 источников, регулярные задачи и команда без разработчиков, n8n закрывает 90 процентов потребностей. Когда сценарии требуют хардкорной работы с селениумом и сложной авторизации, я могу подключить внешний сервис или модуль, но стараюсь оставлять сердце процесса в n8n. Важно, что платформа дружит с внешними API и умеет аккуратно собирать и раздавать JSON. А если через полгода нужно добавить ещё одну ветку или пункт назначения, это делается за минуты, а не недели. В общем, разница в том, что вы получаете гибкий конструктор, а не монолитный скрипт в единственной голове.
Если хочется посмотреть, как я подхожу к архитектуре и кейсам, у меня есть ежедневные заметки и разборы в телеграме. Ссылка аккуратно спрятана в тексте ниже, без фанфар.
Инструменты и узлы, на которые я опираюсь
Я люблю минимализм: меньше узлов — выше устойчивость. В типовой схеме для парсинга сайта я беру HTTP Request для запроса, HTML Extract для выборки, Set для нормализации полей, IF для проверок и Google Sheets или Postgres для хранения. Для уведомлений — Telegram или Email. Иногда добавляю Split In Batches, когда важно не давить на источник и идти порциями. Если нужно разбирать JSON или собирать массивы, помогает Function Item с парой строк на JS, но часто и без этого можно. Отдельный тип узлов — расписания и триггеры, которые запускают сбор по времени или по приходу события. И ещё одна вещь, которую недооценивают: логирование. Я всегда сохраняю метку времени, статус ответа и ключевые поля, это помогает разруливать странности и делать честную аналитику.
Для Telegram и новостных источников
Если говорить про парсинг телеграм n8n, корректный подход — через бота и публичные каналы, где доступность гарантирована. Структура простая: триггер по расписанию, узел Telegram для получения новых сообщений, фильтрация по ключевым словам, хранение. Для новостных сайтов у меня часто два варианта: RSS как золотой стандарт и прямой HTML, если ленты нет или она бедная по полям. В обоих случаях удобно запускать ИИ узел для нормализации тональности, категоризации или извлечения сущностей. Это уже не просто сбор, это аналитика без эксцесса и попыток заменить голову нейросетью. И да, n8n парсинг новостей живёт стабильно, если не пытаться забирать слишком часто и уважать лимиты.
Обойтись без кода и остаться гибкой
У n8n есть мощь в простоте: узлы можно комментировать, группировать и снабжать цветом, чтобы через месяц не вспоминать, что я там имела в виду. Я всегда добавляю ветку ретраев с паузой, чтобы конвейер сам себя лечил от временных сбоёв. Если сталкиваюсь с отложенными ответами, использую Wait и повтор на интервале. Для динамической подгрузки иногда подключаю внешние рендеры, но это уже редкость и по ситуации. А ещё приятно, что платформа дружит с self-host, и можно держать конфиденциальность внутри контура. Мне, как человеку из ИТ-рисков, это добавляет спокойствия.
Чем проще конвейер, тем легче его чинить в понедельник утром, когда отчёт ждут к девяти.
Пошаговый процесс: от URL до таблицы
Когда мне приносят задачу парсинг сайта n8n, я начинаю с прототипа на одном URL, а не со всего каталога. Беру страницу, открываю DevTools и проверяю, где лежат нужные поля, какие классы и структуры повторяются. Затем делаю узел HTTP Request и сохраняю сырые ответы для эталона. После этого переставляю HTML Extract, настраивая CSS селекторы или XPath так, чтобы они были устойчивыми к мелким правкам верстки. Дальше идёт чистка: Set приводит названия, даты и цены к единым форматам, а Function Item, если нужно, убирает валютные символы и конвертирует строки в числа. Прежде чем записывать в хранилище, я ставлю IF для проверки на дубликаты и пустые поля. И только после этого разрешаю запись в Google Sheets, Notion или базу, которую выбрали на старте.
Списком, как это выглядит в n8n
Чтобы было проще, держу короткий план, от которого редко ухожу:
- Формула 1: Request — тянем страницу и сохраняем эталонный ответ.
- Формула 2: Extract — достаём нужные элементы по селекторам и проверяем на пустоты.
- Формула 3: Normalize — приводим типы и значения к нормальной форме.
- Формула 4: Deduplicate — сравниваем с прошлой выборкой, не пишем повтор.
- Формула 5: Store — сохраняем и ставим лог с меткой времени и источником.
Если нужно обойти десятки страниц, добавляю цикл по пагинации, где следую ссылке next или формирую URL из параметров. Это несложно, если сайт дружелюбно отдаёт номера страниц и не меняет схему на каждой пятой. Когда дело доходит до оповещений, я выставляю небольшой буфер: агрегирую новые элементы за 15 минут и отправляю одним сообщением, чтобы не шуметь. И да, всегда оставляю ручной запуск для дебага, потому что «спрятанные» баги любят тишину ночи.
Про альтернативы для динамики
Если HTML рендерится на клиенте и сервер не отдаёт контент без браузера, можно подключить внешний рендер или API страницы, если оно есть и публично. Иногда встраиваю промежуточный сервис как прокси, где страница отрисовывается, и уже готовый HTML идёт в n8n. Это компромисс, который позволяет не уходить в полноценную разработку с Selenium. Для сайтов, которые дают RSS, я честно предпочитаю его — упрощает и ускоряет весь поток. А если есть официальный API, беру его в первую очередь, потому что это стабильность и уважение к источнику. Знаю, звучит скучно, но скука тут полезна.
Если у сайта есть API или RSS — это не ограничение, а подарок. Берите подарок, а не ломайте забор.
Что получается на выходе и как это использовать
На выходе у меня всегда структура, которая понятна не только мне: таблица с полями и метаданными, либо база, где выдержана схема. Это может быть витрина для BI, сводная табличка для аналитика или просто архив JSON с версионированием. В проектах, где важно сравнение, я добавляю вычисляемые поля: разница цен, дельта остатков, тренды появления новостей. Иногда сверху ставлю тонкую автоматизацию: отправить уведомление, если цена упала больше чем на 7 процентов, или если вышло больше 10 упоминаний бренда за час. Для Telegram есть свой паттерн: группа-репозиторий, куда падают новые структурированные записи, и отдельный канал с тихими дайджестами. Плюс ИИ узел для быстрого резюме, если это действительно помогает экономить время, а не имитировать умную жизнь.
Про кейсы и цифры
Из реальных историй отрасли есть показательные примеры. Например, автоматизация сбора профилей кандидатов через разные источники сокращала ручную работу с часов до минут на день, при том что устойчивость процесса выросла за счёт ретраев и очередей. В ecom похожая картина: обработка заказов и уведомлений интеграцией в n8n давала прирост по скорости реакции и снижала человеческие ошибки. Для медиамониторинга n8n парсинг новостей позволяет обходиться без тяжёлых абонентских инструментов, при этом фокусироваться на ценности: скорость и точность отбора. Это не то чтобы магия, просто убрали лишнее и стандартизировали поток. И да, я измеряю экономию времени, а не количество узлов — иногда 6 узлов бьют по эффективности любые реляции.
Интеграции после сбора
Часто сбор — это только первый шаг. Дальше нужны витрины данных, дашборды, иногда — синхронизация с CRM или таск-трекером. Тут как раз удобно, что n8n интегрируется с Google Sheets, Notion, несколькими базами и мессенджерами. Можно настроить ветку enrichment: подтянуть дополнительные поля из другого источника, сделать скоринг, присвоить категорию. А для текстов — пройтись ИИ узлом и сделать короткий summary без фантазий. В итоге получается знающий конвейер, который сам себя кормит и чуть-чуть думает, но без иллюзий про искусственный интеллект как серебряную пулю.
Собрать мало — важно, чтобы эти данные кто-то использовал. Хорошо, если этим «кто-то» станет ещё и алгоритм.
Подводные камни и как я их обхожу
Первый камень — частота и нагрузка. Если вы делаете бесплатный парсинг сайтов с частотой 10 секунд, вы не герой, вы потенциальная проблема для владельца ресурса. Я распределяю запросы, использую Split In Batches и настраиваю паузы. Второй камень — динамика и обфускация: меняются классы, подгружаются блоки, неожиданно вступает в игру капча. Здесь помогает аккуратная деградация: сначала RSS или API, потом HTML, и только если необходимо — рендер. Третий камень — дубликаты и грязные поля. Я ставлю проверку на уникальные ключи, нормализую даты и валюты, чищу HTML из описаний. Четвёртый — правовые риски. Смотрю robots.txt, условия использования и 152-ФЗ, избегаю персональных данных без правового основания, не лезу в закрытые зоны. Пятый — сопровождение. Документирую узлы, оставляю заметки прямо в нодах и веду короткий README рядом с воркфлоу.
Про капчу и блокировки
Есть сайты, которые защищаются агрессивно и имеют на это право. Возможные варианты: снизить частоту и имитировать поведение обычного пользователя в рамках этики, использовать официальные API, если они доступны, либо отказаться. Сервисы распознавания капчи существуют, но к ним обращаюсь только в легальных сценариях и после проверки условий источника. Если цель — устойчивый процесс на месяцы, лучше идти белым путём и не воевать с сайтом. Иногда достаточно переехать на ночной сбор и добавить экспоненциальный бэкофф, чтобы всё работало снова. И да, запись логов помогает понять, где мы перегнули.
Про качество данных
Никакая программа для парсинга сайтов не спасёт, если на входе хаос. Поэтому я всегда формирую минимальный словарь полей: название, URL, дата, цена, источник, статус извлечения. Это помогает сравнивать яблоки с яблоками, а не запутываться в десятке похожих колонок. При сравнении разных магазинов или СМИ выстраиваю словари соответствий и использую простые правила конвертации. И если команда меняется, новый человек быстро понимает, что где. Это скучные вещи, но именно они экономят недели на исправлениях потом. Уроки аудиторских будней, что уж.
Чистые данные дешевле, чем кажется. Грязные данные дороже, чем хочется признать.
Практические советы и мини-чеклист
Собрала короткий набор шагов, который у меня чаще всего работает, даже когда проект стартует на салфетке. Это не догма, а рабочий протокол, который спасает от сюрпризов уже на первой неделе. Я начинаю с «почему», продолжаю «чем», а заканчиваю «как будем сопровождать». Так меньше хаоса и больше контроля над ожиданиями. И да, лучше потратить лишние полчаса на документирование селекторов, чем потом искать, куда пропала цена. Ниже — последовательность, которую легко перенести в ваш процесс, даже если вы идёте малым шагом.
Шаги, которые не подводят
- Шаг 1. Проверить API и RSS, прочитать robots.txt, зафиксировать частоту и объём сбора.
- Шаг 2. Сделать прототип на одной странице, сохранить эталонные ответы и селекторы.
- Шаг 3. Настроить нормализацию полей, проверку на дубликаты и логи статусов.
- Шаг 4. Добавить ретраи, паузы и Split In Batches для нагрузки и устойчивости.
- Шаг 5. Описать README к потоку и настроить мониторинг ошибок для команды.
Если ваша цель парсинг сайтов онлайн без сложной инфраструктуры, начинайте с Google Sheets как витрины и лёгких уведомлений в мессенджер. Когда станет тесно, переедете в базу без боли. Для сравнительного анализа или мониторинга рынка я аккуратно добавляю итерацию по сегментам, чтобы не повесить всё на один процесс. И да, если вдруг вы растёте и нужен более тонкий контроль, всегда можно соседним контуром подключить парсинг веб сайтов на языке разработки. Просто делайте это там, где выгода очевидна, а не из любви к красивому коду.
Если хочется глубже, у меня на сайте аккуратно собраны статьи, схемы и разборы. Можно начать с раздела про автоматизацию — ссылка ниже встроена в текст, без «жмите сюда».
Тихое резюме без фанфар
n8n для парсинга сайтов стал для меня способом держать процессы прозрачными и экономить часы, не увлекаясь лишней сложностью. В нормальном сценарии это несколько узлов, понятные селекторы, аккуратный контроль частоты и логирование. Дальше подключается смысл: витрины, простые правила, иногда ИИ для тонкой нормализации. Я видела, как такие конвейеры снимают рутину с команд, не ломают инфру и дают результат, который можно показать финансам и руководству без оправданий. При этом остаётся важная основа — белый подход: уважение к источникам, законность, никакой гонки за коротким результатом ценой репутации. Если вы давно присматриваетесь к автоматизации, возможно, стоит начать с малого: взять один источник, настроить аккуратный поток, пережить первую неделю мониторинга и получить свой первый спокойный отчёт. Потом станет легче, честно сказала, а тянуть уже будет система.
Неброское приглашение к практике
Если хочется структурировать знания и собрать свой первый устойчивый поток, возьмите один сценарий и сделайте его вместе со мной по шагам. Я регулярно разбираю рабочие кейсы, делюсь картинками воркфлоу и вещами, которые экономят время, в моём телеграме — это удобный способ не теряться и поддерживать темп, без суеты и маркетинговых чудес. Заглянуть в мои материалы, схемы и практики можно на сайте MAREN — там всё спокойно разложено по полочкам, чтобы внедрять и не бояться. Ссылки встроены в текст естественно: можно открыть разборы в телеграм-канале MAREN или посмотреть структурированные статьи и примеры на сайте MAREN. Если готовность высокая, начните сегодня с прототипа и дайте себе право на две попытки, это нормально.
Частые вопросы по этой теме
Можно ли легально собирать данные с любого сайта
Нет. Я ориентируюсь на публичность данных, robots.txt, условия использования и 152-ФЗ. Персональные данные без правового основания не трогаю, закрытые зоны обходятся стороной, а при наличии API или RSS выбираю их как приоритет.
Что делать, если сайт динамический и без RSS
Проверить публичные API, затем попробовать рендер через внешний сервис, и только если это оправдано — добавить его в конвейер. Часто помогает снижение частоты и точный выбор селекторов. Важно сохранять устойчивость и не перегружать источник.
Подходит ли n8n вместо парсинга сайтов на Python
В большинстве типовых задач да, особенно когда нужна прозрачность и поддержка командой без разработчиков. Для сложной авторизации или нетривиальной динамики кодовые решения остаются сильнее, но n8n можно использовать как оркестратор поверх них.
Как избежать банов и капчи
Снижать частоту запросов, использовать Split In Batches, уважать лимиты и правила источника. При необходимости — переходить на RSS или API. Сервисы распознавания капчи рассматриваю только в легальных сценариях и с осторожностью.
Куда лучше складывать результат
Для быстрых стартов годится Google Sheets или Notion. Для регулярных больших потоков удобнее базы данных и витрины для BI. Важно заранее определить схему полей и политику хранения, чтобы не превратить процесс в склад разноформатных CSV.
Можно ли настроить нотификации в мессенджер
Да, стандартный паттерн — агрегировать новые записи за небольшой интервал и отправлять дайджест. Это снижает шум и помогает не пропускать важное. Я часто использую Telegram и простые фильтры по ключевым словам.
Зачем подключать ИИ, если можно обойтись без него
ИИ полезен на этапе нормализации текстов, категоризации и быстрых резюме. Он не замена сбору, а тонкая надстройка, которая экономит время на чтении и разметке. Если пользы нет, я его просто отключаю, без драм.