
Продолжение исследований по теме влияния индексов на производительность СУБД
Предисловие
Каждый разработчик знает: если запрос медленный — нужно добавить индекс. Но что, если именно эти, на первый взгляд быстрые и «дешевые» запросы, становятся причиной деградации производительности всей системы под нагрузкой? В этой статье разбирается парадоксальная ситуация, когда следование классическим правилам оптимизации приводит к обратному эффекту, и объясняется, почему смотреть на стоимость одного запроса в отрыве от общей картины — опасно.
ℹ️Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
Задача
Провести сравнительный анализ влияния индекса на производительность СУБД в ходе нагрузочного тестирования с переменной нагрузкой.
План и сценарии нагрузочного тестирования
Изменение сценариев нагрузочного тестирования
Эксперимент-1 : Дополнительная тестовая таблица - без использования индекса
Тестовая таблица
CREATE TABLE pgbench_test
(
aid integer PRIMARY KEY ,
bid integer,
abalance integer,
filler character(84)
);
ALTER TABLE pgbench_test ADD CONSTRAINT "pgbench_test_bid_fkey" FOREIGN KEY (bid) REFERENCES pgbench_branches(bid);
INSERT INTO pgbench_test ( aid , bid , abalance , filler )
SELECT
id ,
floor(random() * 685 ) + 1 ,
floor(random() * (68500000 - 1 + 1)) + 1 ,
md5(random()::text)
FROM generate_series(1,1000000) id;
Изменение тестового сценария-1
select test.abalance
into test_rec
from pgbench_accounts acc
join pgbench_test test on (test.bid = acc.bid )
where acc.aid = current_aid ;
ℹ️План выполнения тестового запроса: cost = 21620.62
Gather (cost=1002.80..21620.62 rows=1460 width=4) (actual time=4.088..329.017 rows=1468 loops=1)
Workers Planned: 3
Workers Launched: 3
-> Hash Join (cost=2.80..20474.62 rows=471 width=4) (actual time=1.821..300.589 rows=367 loops=4)
Hash Cond: (test.bid = acc.bid)
-> Parallel Seq Scan on pgbench_test test (cost=0.00..19619.81 rows=322581 width=8) (actual time=0.692..263.390 rows=250000 loops=4)
-> Hash (cost=2.79..2.79 rows=1 width=4) (actual time=0.488..0.489 rows=1 loops=4)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts acc (cost=0.57..2.79 rows=1 width=4) (actual time=0.472..0.474 rows=1 loops=4)
Index Cond: (aid = 51440641)
Planning Time: 1.977 ms
Execution Time: 329.301 ms
(12 rows)
⚠️Метод доступа - Parallel Seq Scan on pgbench_test
Эксперимент-2 : Создание индекса
CREATE INDEX pgbench_test_idx ON pgbench_test ( bid );
ℹ️План выполнения тестового запроса: cost = 1546.55
Nested Loop (cost=14.51..1546.55 rows=1460 width=4) (actual time=0.894..366.050 rows=1468 loops=1)
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts acc (cost=0.57..2.79 rows=1 width=4) (actual time=0.217..0.227 rows=1 loops=1)
Index Cond: (aid = 51440641)
-> Bitmap Heap Scan on pgbench_test test (cost=13.94..1529.17 rows=1460 width=8) (actual time=0.669..365.312 rows=1468 loops=1)
Recheck Cond: (bid = acc.bid)
Heap Blocks: exact=1407
-> Bitmap Index Scan on pgbench_test_idx (cost=0.00..13.57 rows=1460 width=0) (actual time=0.355..0.356 rows=1468 loops=1)
Index Cond: (bid = acc.bid)
Planning Time: 2.634 ms
Execution Time: 366.419 ms
(10 rows)
⚠️Стоимость плана выполнения тестового запроса после создания индекса снизилась на 93%
⚠️Метод доступа - Bitmap Index Scan on pgbench_test_idx
Сравнительный анализ производительности СУБД в ходе нагрузочного тестирования в эксперименте-1 и эксперименте-2
Операционная скорость
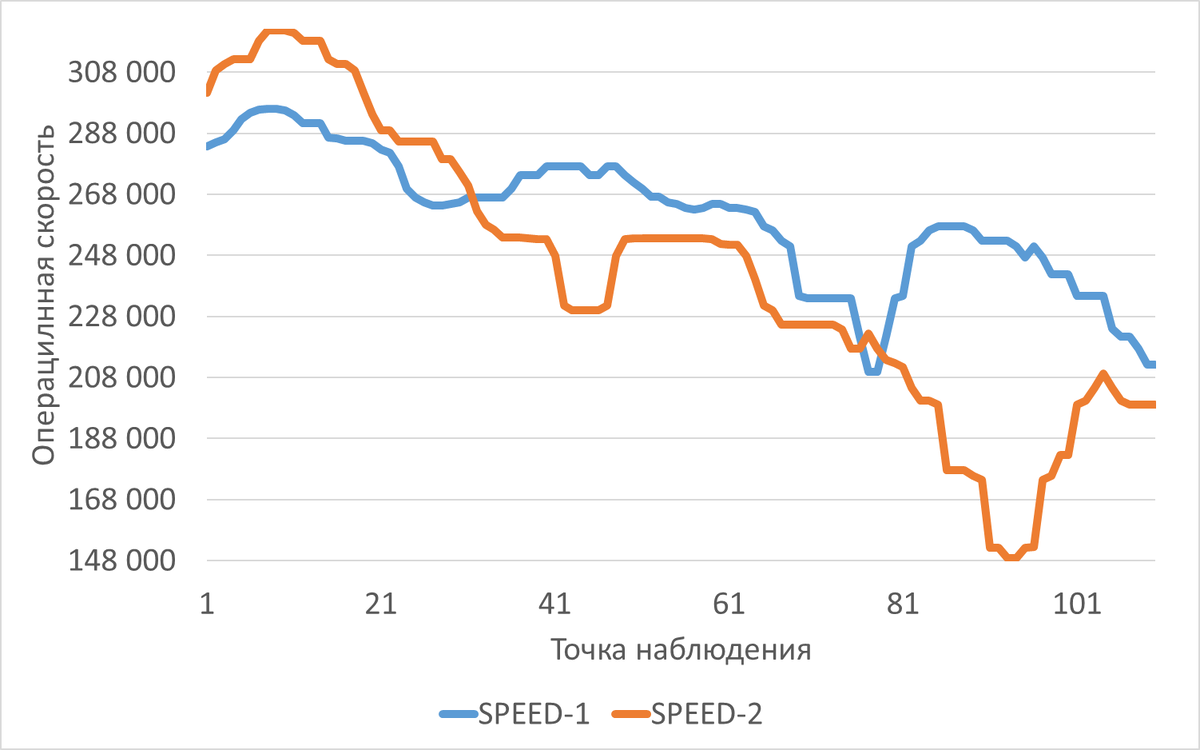
Результаты
- До нагрузки 8 соединений производительность СУБД при использовании индекса(эксперимент-2) превышает производительность СУБД без использования индекса (эксперимент-1) в среднем на 7%.
- С ростом нагрузки после 8 соединений производительность СУБД при использовании индекса(эксперимент-2) ниже производительности СУБД без использования индекса (эксперимент-1) в среднем на 13%.
💥Причины снижения производительности при использовании индекса, в эксперименте-2
1. Увеличение нагрузки на подсистему ввода-вывода
- Без индекса: Sequential Scan читает данные большими последовательными блоками
- С индексом: Index Scans создают случайный доступ к диску
2. Конкуренция за буферный кэш
- Индекс занимает место в shared_buffers
- Вытесняет полезные данные из кэша
- Каждое соединение читает разные части индекса → больше промахов кэш
3. Блокировки в системных каталогах
- При использовании индекса PostgreSQL обращается к системным каталогам
- Увеличивается конкуренция за pg_index, pg_class
- Особенно заметно при многих одновременных соединениях
4. CPU overhead
- Обработка индекса требует больше CPU операций
- Bitmap Index Scan + Bitmap Heap Scan сложнее чем простой Seq Scan
- При росте соединений CPU становится узким местом
Вывод
⚠️Наличие в плане выполнения метода доступа Seq Scan - не является надежным признаком необходимости создания индекса для таблицы.
⚠️Возможны сценарии нагрузки при которых создание индекса ведёт к снижению производительности СУБД , даже при выполнении SELECT.
ℹ️Seq Scan — это не "зло", а инструмент планировщика.
Наличие Seq Scan в плане запроса — это сигнал к дальнейшему исследованию, а не автоматическое руководство к действию по созданию индекса. Это индикатор того, что планировщик счел полное сканирование таблицы наиболее эффективным путем.
Задача — понять, почему он так решил, и является ли это решение правильным для вашей конкретной рабочей нагрузки и данных.