
Вопрос о "силе ИИ" вызывает самые противоречивые оценки экспертов. Прежде всего, не всё ясно с самим определением "силы". Я подробно разбирал этот вопрос в одном из недавних сообщений. Я писал, что если оставить вне рассмотрения способность ИИ к сознательному опыту и переживаниям, самосознанию, то разница между слабым ИИ, который специализируется на одной задаче, и сильным ИИ, способным выполнять любую работу не хуже человека (и, даже, лучше) - весьма условна. Действительно, никто не мешает создать самых разных, специализированных ИИ, и заставить их координированно работать вместе, подобно тому, как это делал бы один общий (сильный) ИИ.
Поэтому, приходится вводить дополнительные критерии, требуя, чтобы сильный ИИ "действительно думал, как человек". А с критериями навыка "мыслить по-человечески" возникают огромные сложности, которые, пока, далеки от разрешения.
Напомню, что большие языковые модели ( LLM - large language models) - один из бурно развивающихся вариантов ИИ. Прежде, чем рассуждать об их потенциальной силе, следует, хотя бы кратко описать, на каких принципах они устроены.
Как работают LLM
В самом общем виде, LLM - это гигантская статистическая машина, которая учится предсказывать слова на основе огромного опыта чтения текстов.
Модель читает (в переносном смысле) миллиарды страниц из интернета: книги, статьи, форумы, инструкции и т.д. Она не «запоминает» текст дословно, а учится находить закономерности: какие слова часто идут вместе, как строятся предложения, как отвечают на вопросы и т.п.
Основная задача модели во время обучения — угадывать следующее слово в предложении. Например, если ей дать фразу:
«Сегодня на улице идёт…»
— она пытается угадать, что будет дальше: «дождь», «снег», «парад» и т.д.
Чем чаще она тренируется, тем лучше угадывает.
Внутри у модели — нейронная сеть (система математических уравнений с коэффициентами - параметрами модели), похожая по принципу обработки информации на человеческий мозг. Она состоит из слоёв «нейронов», которые обрабатывают информацию. Чем больше таких слоёв и нейронов — тем «умнее» модель (но и тем дороже её обучать и запускать). У современных LLM десятки и сотни миллиардов параметров, которые гибко настраиваются в ходе обучения.
Модель не работает с буквами или целыми словами, а разбивает текст на токены — это могут быть слова, части слов или даже знаки препинания.
Обрабатывая запрос, модель «помнит» только то, что написано в нём и, возможно, в предыдущих сообщениях диалога (в пределах так называемого контекстного окна — например, 4096 токенов). Она не помнит, что было вчера или неделю назад, если ей не напомнить.
В своём ответе модель пошагово выбирает наиболее вероятные слова одно за другим, основываясь на том, что уже написано. Это как собирать пазл, где каждый следующий кусочек подбирается по картинке, которую уже собрали.
Насколько нейросети LLM успешно имитируют мыслительный процесс человека? Способны ли они понимать текст, который генерируют?
- Модель не думает, как человек. Она не понимает смысл в привычном нам смысле — она просто очень хорошо угадывает, что «звучит правильно».
- Она не знает правду или ложь — только то, что часто встречалось в обучающих данных.
- Она не имеет целей, желаний или эмоций — всё, что она делает, — это математика и статистика.
Казалось бы, что такой поход с "угадыванием" не даст стоящих результатов. Действительно, нейросети придуманы в середине прошлого века, их математический аппарат с тех пор хорошо изучен. Но бурное практическое развитие они получили совсем недавно. Неожиданно оказалось, что размер имеет значение - при превышении некоторого порогового для модели числа параметров (условно, 200 млн), а также объёма обучающих данных, результаты обучения начинают поражать воображение! Модель демонстрирует впечатляющие результаты даже в областях, на которые она изначально и не была рассчитана – например, в написании компьютерных программ, решении логических задач, постановке диагнозов в медицине и т.п.
В документе “GPT-4 Technical report” ( OpenAI(2023), март 2023) приводятся достижения версии GPT-4 в сравнении с версией GPT-3.5 в прохождении самых разнообразных человеческих тестов и экзаменов. И эти достижения впечатляют!
GPT-4 демонстрирует результаты на человеческом уровне на большинстве этих профессиональных и академических экзаменов, в том числе на достаточно сложных экзаменах семейства GRE (Graduate Record Examination), которые необходимо сдавать для поступления в аспирантуру/магистратуру в вузах США и ряда других стран (в том числе —Канаде, Швейцарии и Австралии).
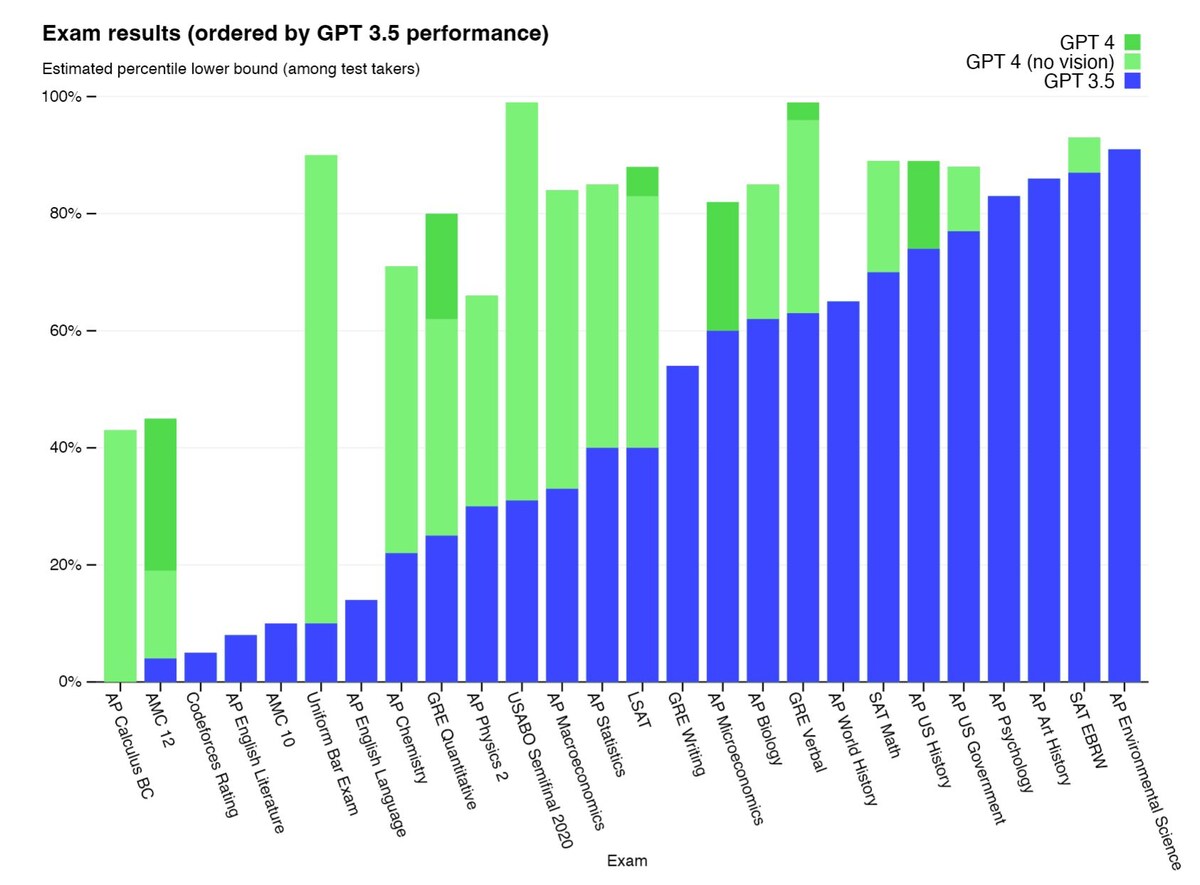
Примечательно, что он сдает имитационную версию Единого экзамена в адвокатуру (Uniform Bar Examination, UBE) с результатом топ 10% лучших тестируемых, сразу в несколько раз улучшив достижение GPT-3.5. И это, действительно, свидетельствует о переходе «количества в качество».
Может ли GPT эволюционировать в сильный (общий) ИИ?
Многие эксперты сходятся во мнении, что по-настоящему серьёзные проблемы самого разного рода в связи с эволюцией ИИ встанут перед человечеством тогда, когда он достигнет уровня «сильный ИИ». Напомню, что согласно разделяемому мною определению С.Рассела и П.Норвига «утверждение, что машины действительно мыслят (а не просто имитируют мыслительные процессы), называется гипотезой сильного искусственного интеллекта».
ChatGPT и ему подобные модели именно что имитируют мышление, причём, уже довольно искусно, о чём говорит и прохождение пресловутого теста Тьюринга, и сдача прочих профессиональных тестов. Но это не делает их «сильными».
Здесь уместно вспомнить одно из 9 возражений Тьюринга, а именно, возражение леди Лавлейс: «Аналитическая машина не претендует на то, чтобы создавать что-то действительно новое. Машина может выполнить все то, что мы умеем ей предписать» (курсив леди Лавлейс). Либо, в другой редакции, «машина никогда не сможет создать ничего подлинно нового». Сам Тьюринг парировал это возражение крайне неубедительными аргументами типа “ничто не ново под Луной» и «нельзя сказать, что машина никогда не сможет ничем поразить человека – меня, например, она постоянно поражает, и, вообще, чтобы «поражаться», необходим «умственный творческий акт», на который вы просто можете быть не способны!».
Вопрос «новизны» знания не так прост, как кажется. Я считаю мир вокруг нас объективно существующим, и человек является его частью. Знания, в общем смысле, - совокупность наших представлений о том, как этот мир «на самом деле» устроен. По мере человеческой эволюции эти знания уточняются и усложняются, всё более приближаясь (хочется верить) к истинному пониманию «сути вещей». Новыми (а, по сути, доступными) для человека определённые знания становятся, когда он в состоянии их воспринять, в соответствии с древним принципом «готов ученик – придёт учитель». Для образного представления, можно принять, что некто составил для человека самый полный и подробный перечень всевозможных сведений «обо всём». Обо всём что было, есть и будет. Что-то типа пресловутых «хроник Акаши». В таком перечне есть ответы на все вопросы, которые человек способен задать сейчас или в неопределённо далёком будущем. Человек, по мере своего развития, постепенно подключается ко все более глубоким слоям этого «реестра знаний», пользуясь мозгом, как своеобразным «интерфейсом» (в соответствии с представлениями панпсихизма).
А вопрос, который следует обсуждать, состоит в том, способен ли ИИ на такой, человеческий, способ получения нового знания? И есть ли разумная альтернатива этому способу, пользуясь которой ИИ превзойдёт человека в познавательной деятельности? Пока представляется, что ИИ, максимум, может в своей «познавательной деятельности» использовать человека (манипулируя им) как отмычку к «ларцу знаний».
В процессе обучения языковой модели мы «скармливаем» ей гигантский массив данных, который содержит огромное количество смысловых связей и ассоциаций. Настройка параметров нейросетевых алгоритмов позволяет GPT находить нужные связи и ассоциации на уровне усреднённого, среднестатистического человека. Ключевой момент в том, понимает ли нейросеть те понятия, которыми оперирует? Доступен ли ей смысл либо она его просто удачно угадывает, и если в обучающих данных такого смысла нет (скажем, он подразумевается, но явно не сформулирован), то и нейросеть не сможет его «сгенерировать»?
Подробный ответ на этот вопрос занял бы слишком много места. Дискуссия ведётся более сорока лет в связи с мысленным экспериментом "китайская комната" Джона Сёрла. (я рассматривал его здесь).
Моя позиция состоит в том, что создание сильного ИИ с необходимостью предусматривает воссоздание всей палитры процессов, входящих в понятие «субъективного опыта». И мышление здесь – лишь составная часть этого опыта, которую, в индивидуальном сознании, просто нельзя считать полноценной без остальных частей. И чтобы стать «сильным» и научиться «действительно» мыслить, ИИ, с необходимостью, должен пройти весь тот путь, который проходит средний человек, обучаясь и накапливая жизненный опыт. Можно лишь ускорить эти процессы, но нельзя их ничем заменить! А для этого такой ИИ должен быть «воплощён» в мире, то есть иметь неограниченную (по крайней мере, такую же, как и любой человек) возможность взаимодействовать с окружающим миром. Получать любую доступную информацию, влиять на происходящее, добиваясь нужного для себя результата и т.п.
Может ли всё это делать нейросеть типа GPT в том виде, в котором она существует и эволюционирует? Очевидно, нет!
На мой взгляд, «сила» такого ИИ возможна, гипотетически, лишь в специально сконструированном мире, в котором ИИ будет частью некоей экосистемы (как модно сейчас выражаться). На это обратил внимание Элиезер Юдковский, один из признанных экспертов в области ИИ:
«Вероятно, ИИ появится в мире, полностью охваченном глобальной компьютерной сетью. Но уже сегодня есть ряд новейших технологий, которые явно пригодятся будущему ИИ в его мировой сверхдержаве: облачные вычисления; сенсорные устройства с подключением к интернету; военные и гражданские беспилотники; автоматизация исследовательских лабораторий и производственных предприятий; электронные платежные системы и цифровые финансовые средства; автоматизированные системы анализа информации и системы принятия решений. Этот активный технологический багаж будущий ИИ приберет к рукам с дискретной скоростью, что явно поспособствует его восхождению к вершине власти…»
Поэтому, я уверен, что GPT-подобные модели – это не дорога к сильному ИИ (на это его создатели и не ориентировались!), а шаг к построению нового «дивного» мира цифровых технологий, где такие ИИ будут играть центральную роль. И сила субъективного опыта и переживаний ему совсем не нужна для тех целей, ради которых его разрабатывают.
О том, как именно ИИ способен изменить социально-экономический ландшафт нашей цивилизации я буду писать в следующих статьях.