
Что если обучение искусственного интеллекта подчиняется тем же законам, что и физика?
Исследователи из Alibaba и Шанхайской AI-лаборатории нашли формулу, которая описывает, как именно большие языковые модели “ломаются” от переизбытка знаний — и как не довести их до этой точки.
Работа под названием “How to inject knowledge efficiently? Knowledge Infusion Scaling Law for LLMs”(arXiv:2509.19371) открывает новый класс закономерностей — закон масштабирования инфузии знаний.
Это — своего рода Chinchilla 2.0, но не для подсчета токенов и FLOPs, а для определения, сколько именно знаний можно “влить” в модель, прежде чем она начнет забывать сама себя.
⚙️ Как “знание” ломает модель
До сих пор существовало простое правило: чем больше данных — тем умнее модель. Но это не так.
Учёные показали, что у каждой LLM существует “точка когнитивного коллапса” — критический порог, после которого память модели резко деградирует.
💥 Феномен “Memory Collapse”
Когда в модель вливают слишком много доменных фактов — она начинает терять уже существующие знания.
Как будто человек, заучивший список всех химических элементов, внезапно перестает помнить таблицу умножения.
🧩 Что показали эксперименты:
- 🧠 Модели объёмом от 137M до 3B параметров обучались с постепенным увеличением количества “влитых фактов” из Wikidata.
- 🔥 При достижении определённой частоты встраивания (injection frequency) производительность не просто переставала расти — она падала ниже базового уровня.
- 📉 Чем больше модель, тем раньше наступает коллапс — то есть, большие модели требуют меньше специализированных данных, чтобы достичь насыщения.
📏 Новый закон масштабирования
Чтобы формализовать этот эффект, авторы вывели уравнение, описывающее зависимость между частотой внедрения знаний (F) и качеством запоминания (P):
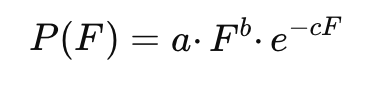
Первая часть уравнения (F^b) описывает рост — чем больше знаний, тем лучше.
Но экспонента (e^{-cF}) показывает, что после некой точки прирост превращается в разрушение.
Математически, оптимальная “доза знаний” определяется просто:
🪐 И вот ключевая находка — если построить зависимость F′ от вычислительных FLOPs (C = 6ND), то появляется устойчивая закономерность масштабирования:
То есть, мы можем предсказать оптимальный объём доменных данных для GPT-подобных моделей, обучаясь на “мини-моделях”.
🧬 Экспериментальная кухня
Чтобы доказать закон, команда обучила 7 моделей с нуля (от 137M до 3B параметров) на базе FineWeb-Edu и 58–100 миллиардов токенов.
Знания брались из Wikidata в виде триплетов (subject, relation, object), например:
(“Angel”, “color”, “white”) → “What is the color of Angel? The color of Angel is white.”
Оценка производилась не по BLEU или точности, а по perplexity-разбору — чем ниже перплексия у правильного ответа, тем лучше модель “помнит” факт.
📊 Визуализируя зависимость запоминания от частоты внедрения знаний, исследователи получили графики, где каждая кривая заканчивалась “обрывом” — точкой когнитивного коллапса.
🧩 Что это значит для будущего LLM
💡 1. Конец эпохи “корпусного максимализма”.
Не нужно вливать в модель всё подряд. Достаточно рассчитать оптимальную долю доменных данных — остальное только ухудшит память.
⚙️ 2. Прогнозирование без дорогостоящих экспериментов.
Теперь можно тренировать маленькую 300M-модель, определить её точку коллапса, и точно вычислить, сколько знаний можно влить в GPT-уровень модели. Это экономит миллионы GPU-часов.
🧠 3. Новый взгляд на “забывание” AI.
Катастрофическое забывание больше не случайность — это закономерное физическое свойство параметрического пространства.
Можно сказать, что у моделей есть “гравитация памяти” — чем тяжелее интеллект, тем быстрее он сплющивается под весом знаний.
🤔 Моё мнение
Это исследование — не просто про оптимизацию обучения, а про психологию искусственного интеллекта.
В каком-то смысле, оно повторяет путь человеческого мозга: если перегрузить сознание фактами, теряется гибкость и обобщающая способность.
Модель должна “знать ровно столько, чтобы понимать” — и именно это показывает закон инфузии знаний.
Он превращает обучение нейросетей из искусства эмпирики в инженерную науку, где можно рассчитать, сколько знаний мир поместит в память машины, прежде чем та начнёт забывать саму себя.
🔗 Источники
- 💬 Связанные исследования: Chinchilla Scaling Laws (Hoffmann et al., 2022)
- 🧩 Данные: FineWeb-Edu Dataset (HuggingFace)
- 🌐 База знаний: Wikidata Triples
🧮 Когда-нибудь мы научимся обучать модели так, как растим детей — не заливая в них знания, а выстраивая границы, за которыми начинается мудрость.