
Мир языков — это не только слова и грамматика, но и акценты, отражающие историю, миграцию и культурные контакты. Команда BoldVoice решила взглянуть на это глазами искусственного интеллекта — точнее, его ушами. Результатом стал проект Accent Explorer: интерактивная 3D-визуализация, показывающая, как ИИ группирует акценты английской речи без всяких текстов или лингвистических подсказок.
🧠 HuBERT слушает, а не читает
В основе проекта лежит модель HuBERT — это аудио-фундаментальная нейросеть, обученная понимать структуру речи без транскрипций. Инженеры BoldVoice дообучили её на 25 000 часах речи от 200 носителей разных языков, не предоставляя модели ни текстов, ни расшифровок — только голос.
🎛️ Архитектура модели выглядит так:
- 🎧 Вход — чистая звуковая волна 16 кГц, без спектрограмм.
- 🧩 7 сверточных слоёв (CNN) извлекают признаки из аудио.
- 🧠 12 трансформерных слоёв формируют 768-мерное латентное представление — что-то вроде «внутреннего слухового образа».
- 🔊 На выходе — классификационная «голова» из 50 акцентов.
Итого: 94,6 млн параметров, неделя обучения на кластерe NVIDIA A100 и 30 млн звуковых фрагментов. Модель анализирует только звучание, а не смысл, и именно это делает результат особенно чистым — мы видим не лексику, а музыку речи.
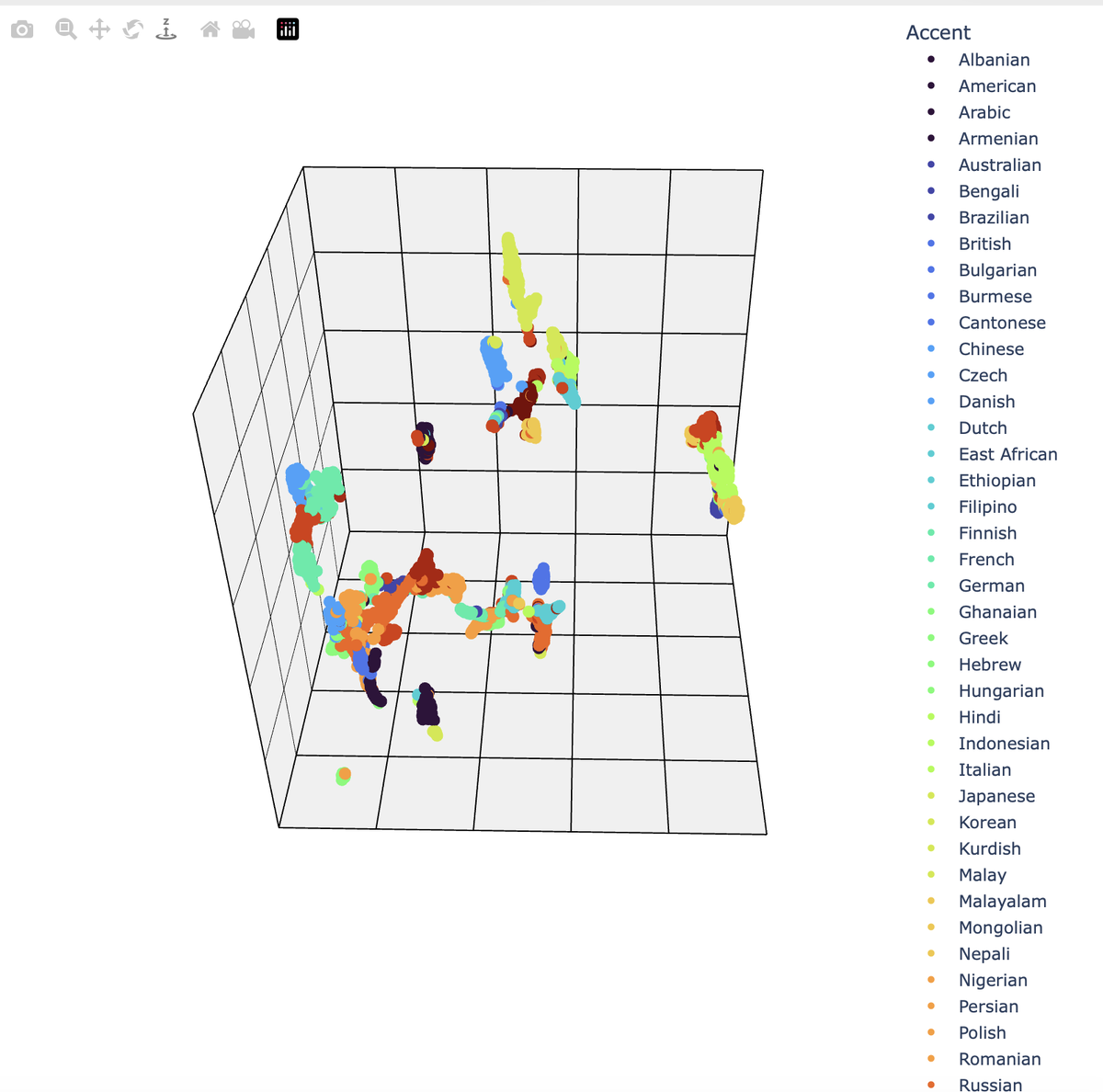
🗺️ 3D-карта акцентов: где Австралия встречается с Вьетнамом
После обучения исследователи применили метод UMAP для проекции многомерного пространства в трёхмерное — чтобы визуализировать, как ИИ видит «близость» между акцентами.
Результаты оказались неожиданными:
- 🇦🇺 Австралийский акцент оказался рядом с вьетнамским — возможно, из-за эмиграции и взаимодействия культур.
- 🇫🇷 Французский — рядом с нигерийским и ганским, что отражает колониальное прошлое.
- 🇮🇳 Внутри индийского субконтинента ИИ расположил южные языки (телугу, тамильский, малаялам) отдельно от северных (непальский, бенгальский) — почти как на реальной карте Индии.
- 🇰🇷 И, пожалуй, самое интересное: корейский и монгольский акценты образовали кластер, будто оживив старую гипотезу об «алтайском родстве языков».
🧭 Эта карта не просто красива — она слышит историю человечества через интонацию.
🔊 Анонимный голос, но живой акцент
Для демонстрации команда BoldVoice использовала собственную модель голосовой стандартизации. Она превращает оригинальные записи в нейтральный голос, сохраняя акцент, но убирая особенности тембра, пола и микрофона.
Это не просто технологическое изящество:
- 🕵️ Оно анонимизирует участников, защищая их личность.
- 🧠 И делает акценты чистыми для восприятия, убирая посторонние факторы.
Да, такая нормализация вносит мелкие артефакты, но зато позволяет буквально услышать различия между кластерами.
🧬 Когда ИИ становится лингвистом
Меня лично поражает то, что модель без знаний о языках, фонетике или географии смогла уловить закономерности, о которых лингвисты спорили десятилетиями.
ИИ, который не знает, что такое “Англия” или “Южная Азия”, сам открывает, что тамильский и телугу ближе друг к другу, чем телугу и хинди.
Это открывает новую ветвь прикладной фонетики: «аудиолингвистика через эмбеддинги».
Мы больше не обязаны анализировать звуки вручную — нейросеть делает это за нас, формируя карту человеческой речи в многообразии её мелодий.
💭 Моё видение
Accent Explorer — это не просто визуализация. Это новая форма аудио-антропологии.
ИИ становится зеркалом человеческой истории — не текстовой, а звуковой. Он показывает, что язык — это не дерево родства, а сеть влияний, где география, колониализм, миграция и культура сплетаются в единую звуковую ткань.
И если задуматься, этот проект — шаг к чему-то большему:
- 🌐 глобальные ИИ-акценты могут стать основой для адаптивных ассистентов, которые говорят “по-человечески”, подстраиваясь под культурный фон;
- 🎤 а преподавание произношения наконец может перейти от «правильных звуков» к реалистичным акцентным моделям, где ИИ объясняет, как вы звучите миру.
🔗 Источники и ссылки
- 🌐 Официальный проект: https://accent-explorer.boldvoice.com/
- 🧠 Модель: boldvoice/hubert-accent-identifier
- 🎧 BoldVoice: boldvoice.com
💬 ИИ не только учится понимать нас — он впервые начинает нас слушать. И, кажется, слышит глубже, чем мы сами.