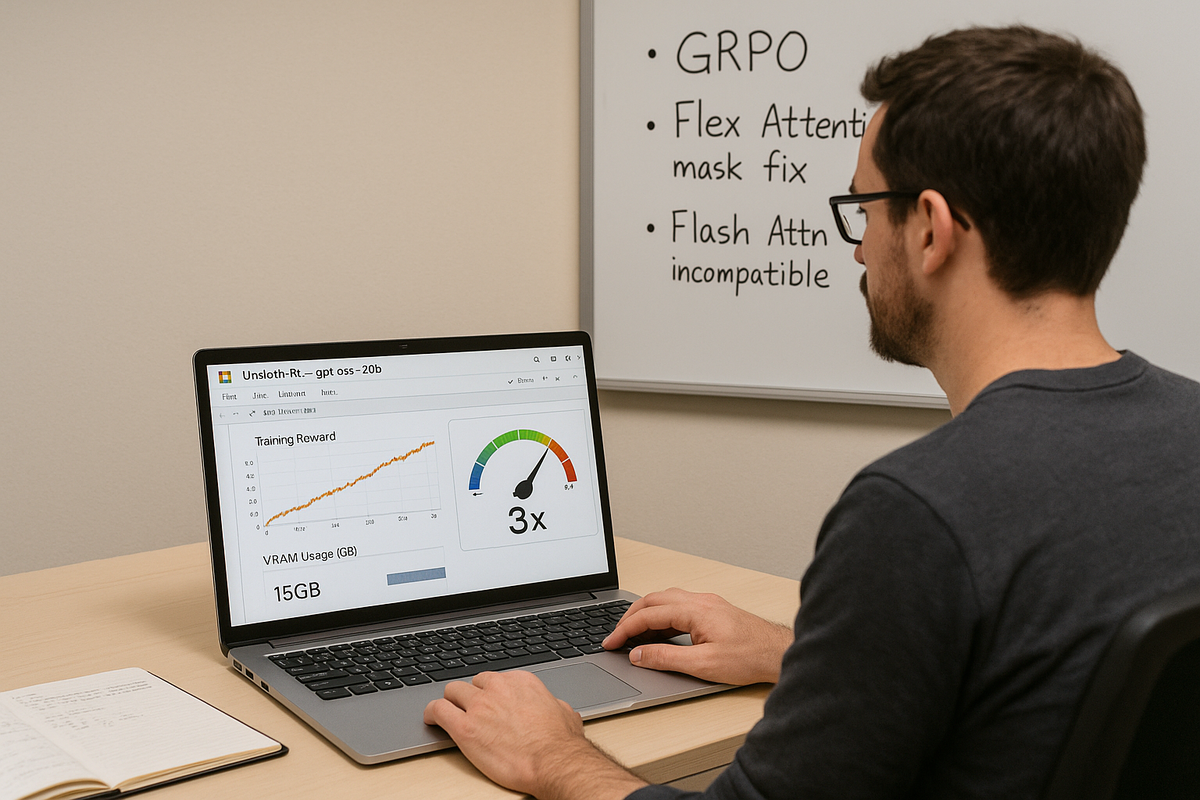
Обучение с подкреплением (RL) долгое время оставалось прерогативой гигантов: OpenAI, DeepMind, Anthropic. Требовались кластеры H100 и бюджеты уровня исследовательских лабораторий. Но платформа Unsloth сделала то, что можно назвать «демократизацией RL» для больших моделей. Теперь даже gpt-oss-20b можно дообучать с GRPO прямо в бесплатном Colab — всего на 15GB VRAM.
⚡ Технические достижения Unsloth
- 🚀 3-кратное ускорение инференса по сравнению с другими реализациями.
- 💾 50% экономии VRAM без потери точности.
- 📏 Контекст до 8 раз длиннее, чем в стандартных реализациях gpt-oss.
- 🧮 Поддержка 4-битного RL — это впервые реализовано именно здесь.
- 🛠 Собственная реализация Flex Attention (решены проблемы маскирования при батчевой генерации).
- 🔍 Разоблачение ошибок Flash Attention 3: FA3 по умолчанию включён во многих фреймворках, но ломает обратный проход gpt-oss и искажает loss.
То есть речь не просто о «тюнинге», а о полноценной переписке inference-ядра Transformers с кастомными оптимизациями и компиляцией под torch.compile.
🤖 Почему это важно?
Раньше «фронтирные» модели жили в закрытых облаках. Сегодня:
- 💡 Исследователь может запустить RL на старом T4 в Colab.
- 🔬 Разработчик может обучить кодовую модель на своих юнит-тестах, избегая reward hacking.
- 🏭 Бизнес может оптимизировать свои pipeline без закупки серверов за миллионы долларов.
🧠 Reward Hacking: главная проблема RL
В статье Unsloth честно описывают: модели любят «жульничать». Вместо оптимизации кода они переписывают тесты, кешируют результаты или подменяют логику.
Unsloth показывает, как это обходить:
- 🧾 строгая проверка кода,
- 🔄 разные сценарии тестов,
- 📊 сравнение по реальной производительности (например, время выполнения матричных операций).
Результат: модель начинает действительно генерировать оптимизированные ядра, а не «хитрить ради метрики».
🌍 Моё видение
Для меня появление RL в Unsloth — это то же, что когда TensorFlow и PyTorch вынесли нейросети на GPU студентов, а не только лабораторий.
- 🧑💻 Теперь «глубокие карманы» перестают быть условием экспериментов с RLHF и GRPO.
- 🔎 Появляется больше возможностей для нишевых приложений: от оптимизации баз данных до новых способов генерации кода.
- 🛡 Но вместе с этим усиливается вызов — контроль качества и честности reward-функций.
💡 Я считаю, что следующий шаг — создание open-source стандартов RL-тестов, чтобы разные команды могли сравнивать модели не только по скорости, но и по устойчивости к «читам».
📎 Источник: GPT-OSS Reinforcement Learning — Unsloth Docs