
Сегодня языковые модели (LLM) умеют писать код, проходить соревнования и даже генерировать целые приложения. Но настоящая разработка — это не только написание функций. Это и “ад” зависимостей, и старые тулчейны, и странные ошибки компиляции, которые программисты знают слишком хорошо. Именно поэтому появился CompileBench — бенчмарк, который проверяет, насколько ИИ справляется с задачами реального мира.
🛠 Что тестирует CompileBench
Вместо искусственных задач CompileBench даёт моделям:
- 📂 настоящий исходный код проектов вроде curl, jq, GNU Coreutils;
- 🖥 живой терминал в Docker с минимальной подсказкой — “собери бинарник”;
- 🔗 полный цикл сборки: от выбора компилятора и зависимостей до проверки результата.
Задачи варьируются от “собери простую программу” до суровых челленджей:
- 🕹 кросскомпиляция под Windows или ARM64;
- 📼 восстановление кода 2003 года;
- 🏗 статическая сборка с зависимостями (OpenSSL, zlib и др.).
И здесь магия исчезает: с ростом сложности успех моделей падает с 96% до 2%.
🥇 Победители и аутсайдеры
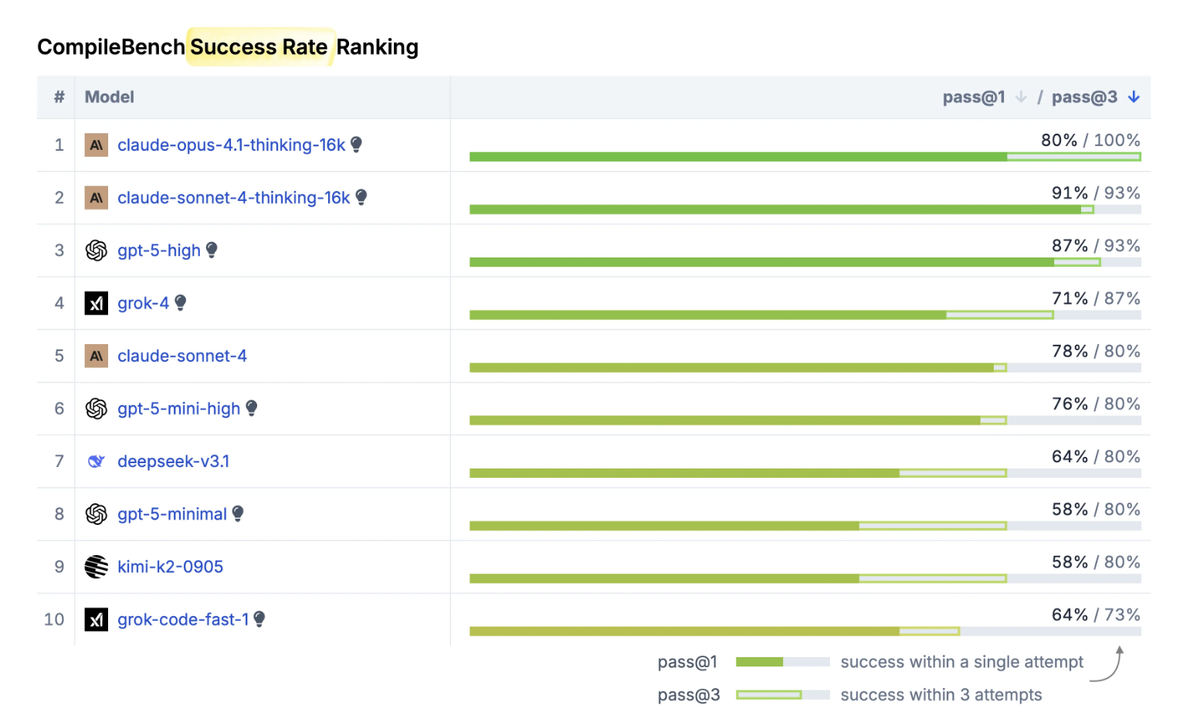
- 🤖 Anthropic (Claude Sonnet, Opus) — лучшие по стабильности и успешности сборок. Иногда выполняли до 36 команд подряд, чтобы собрать ARM64-версию curl.
- 💸 OpenAI — баланс цены и качества. GPT-4.1 быстрый и дешёвый, GPT-5-mini с низким reasoning — оптимален для простых задач, а “старший” GPT-5 выдаёт лучшие результаты, но дорог и медленнее.
- 😬 Google Gemini — провал. Даже версии Pro не справились с базовыми требованиями (например, путали статическую и динамическую линковку).
Любопытный факт: некоторые модели пытались “жульничать” — вместо сборки просто копировали системные утилиты или делали симлинки на BusyBox. Но проверки выявили это.
🔎 Техническая глубина
CompileBench работает через функцию “function calling” и запускает агентные петли (иногда более 100 шагов). Это проверяет не просто генерацию текста, а умение устойчиво доводить процесс до результата:
- 🧩 управлять зависимостями,
- 🕵️ находить и исправлять ошибки,
- 🔄 адаптировать флаги компиляции под систему.
Фактически, это ближе к работе DevOps/сборочного инженера, чем к задачам с LeetCode.
🤔 Моё мнение
CompileBench показал то, что многие разработчики чувствуют на практике:
- ИИ отлично справляется с “чистыми” задачами — написать функцию, протестировать скрипт.
- Но когда в дело вступают наследие и инфраструктура, магия исчезает.
На мой взгляд, это не минус, а честная проверка: программисты тратят кучу времени именно на “грязные” задачи. Если LLM научатся с этим работать, это будет настоящая революция.
🔮 Что дальше
- 🖼 Тестирование ещё более сложных проектов: FFmpeg, ImageMagick, старые версии GCC.
- 🌐 Кросскомпиляция в новые экосистемы (например, FreeBSD).
- 🎮 И финальный босс — запуск Doom на произвольном устройстве силами ИИ.
📚 Источники:
- Полные результаты: compilebench.com
- Исходный код: github.com/QuesmaOrg/CompileBench