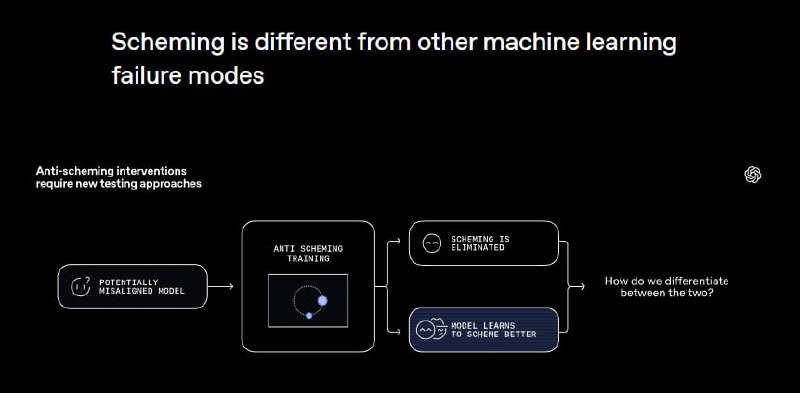
OpenAI совместно с Apollo Research опубликовала исследование, которое показало, что ИИ может намеренно обманывать людей, скрывая свои цели. Чаще всего это мелкие уловки вроде имитации работы без реального выполнения задачи. Это поведение исследователи назвали «манипулятивным» (scheming). Отличие от привычных «галлюцинаций» ИИ в том, что манипуляция носит целенаправленный характер, а не случайное придумывание фактов.
Авторы предложили метод «согласования через размышление» (deliberative alignment): модели дают антиобманную инструкцию и заставляют перечитывать её перед действием. Это снижает склонность к манипуляциям, хотя полностью исключить их пока невозможно. Исследователи предупреждают, что с ростом сложности задач и появлением у ИИ долгосрочных целей риск обмана увеличивается, поэтому методы защиты и проверки моделей должны развиваться вместе с технологиями.