
Начало
Задача
Проанализировать состояние ОС и характерные ожидания СУБД при инциденте производительности для высоконагруженной СУБД.
- Количество ядер CPU : 192
- Размер RAM: 1TB
- Версия PostgreSQL: 15.13
Инцидент производительности СУБД
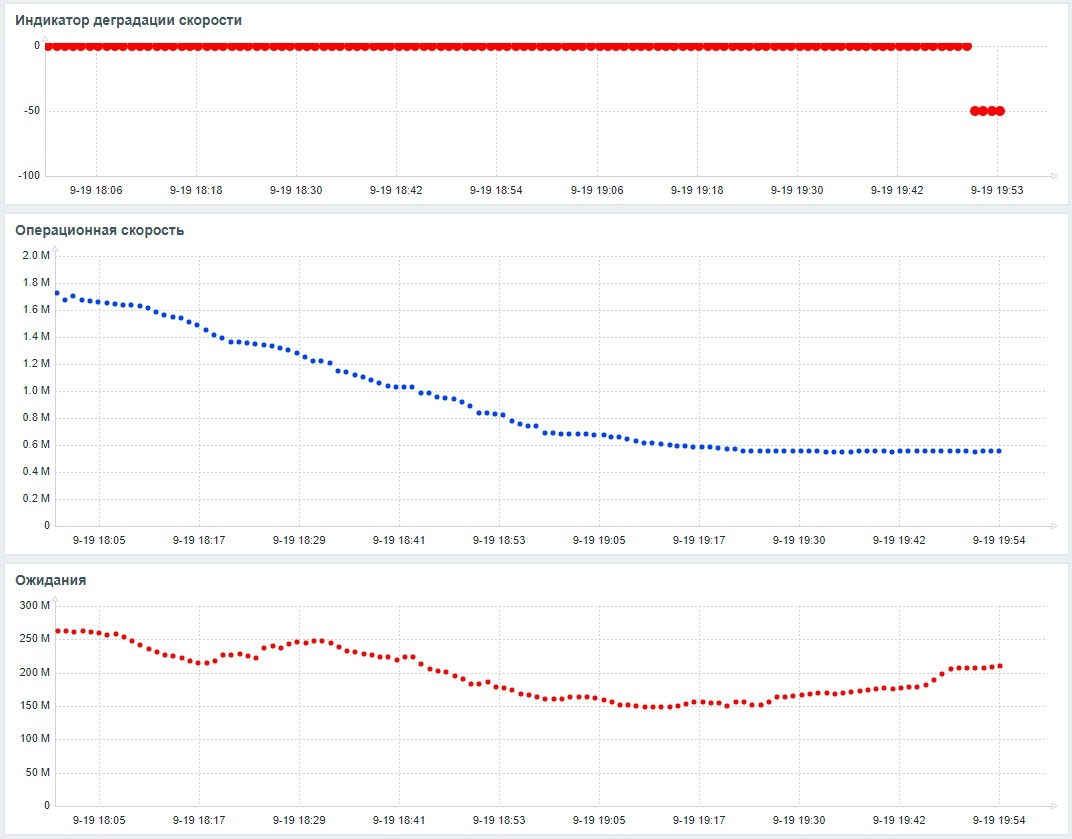
Часть 1 - ОС
Часть 2 - Производительность и ожидания СУБД
80% ожиданий СУБД вызваны ожиданиями типа LWLock и IO.
Часть 3 - характерные события ожиданий типа LWLock
Характерные события ожидания типа IO
- BufFileRead: Ожидание чтения из буферизованного файла.
- BufFileWrite: Ожидание записи в буферизованный файл.
- DataFileExtend: Ожидание расширения файла данных отношения.
- DataFileImmediateSync: Ожидание немедленной синхронизации файла данных отношения с надёжным хранилищем.
- DataFilePrefetch: Ожидание асинхронной предвыборки из файла данных отношения.
- DataFileRead: Ожидание чтения из файла данных отношения.
- DataFileTruncate: Ожидание усечения файла данных отношения.
- DataFileWrite: Ожидание записи в файл данных отношения.
- DSMFillZeroWrite: Ожидание заполнения нулями файла, применяемого для поддержки динамической общей памяти.
- RelationMapRead: Ожидание чтения файла отображений отношений.
- RelationMapSync: Ожидание помещения файла отображений отношений в надёжное хранилище.
- SLRURead: Ожидание чтения страницы SLRU.
- SLRUWrite: Ожидание записи страницы SLRU.
- VersionFileSync: Ожидание попадания файла версии в надёжное хранилище при создании базы данных.
- WALInitSync: Ожидание помещения в надёжное хранилище нового инициализированного файла WAL.
- WALInitWrite: Ожидание записи при инициализации нового файла WAL.
- WALSync: Ожидание помещения файла WAL в надёжное хранилище.
- WALWrite: Ожидание записи в файл WAL.
BufFileRead
Ожидания типа BufFileRead в PostgreSQL связаны с операциями чтения из временных файлов, которые используются для обработки данных, не помещающихся в оперативную память. Эти ожидания указывают на проблемы с производительностью операций, требующих использования дискового ввода-вывода для временных данных.
🔍 Основные причины роста ожиданий BufFileRead
- Недостаточный объем памяти для операций
Нехватка work_mem: Когда операции (сортировка, хеширование, агрегация) не помещаются в выделенную память (work_mem), PostgreSQL вынужден использовать временные файлы на диске
Большие наборы данных: Обработка больших таблиц или выполнение сложных JOIN-операций с большими объемами данных - Проблемы с дисковой подсистемой
Медленные диски: Использование HDD вместо SSD для временных файлов
Высокая задержка I/O: Проблемы с производительностью дисковой подсистемы
Конкуренция за ресурсы: Одновременное выполнение множества операций, использующих временные файлы - Неоптимальные запросы
Отсутствие индексов: Полное сканирование больших таблиц
Сложные агрегации: Операции GROUP BY над большими наборами данных
Неэффективные JOIN: Многократные соединения больших таблиц - Настройки PostgreSQL
Недостаточный temp_buffers: Маленькое значение параметра temp_buffers
Неправильная конфигурация: Неоптимальные настройки памяти
BufFileWrite
Ожидания типа BufFileWrite в PostgreSQL связаны с операциями записи во временные файлы, которые используются для обработки данных, не помещающихся в оперативную память. Эти ожидания указывают на проблемы с производительностью операций, требующих использования дискового ввода-вывода для временных данных.
🔍 Основные причины роста ожиданий BufFileWrite
- Недостаточный объем памяти для операций
Нехватка work_mem: Когда операции (сортировка, хеширование, агрегация) не помещаются в выделенную память (work_mem), PostgreSQL вынужден использовать временные файлы на диске
Большие наборы данных: Обработка больших таблиц или выполнение сложных JOIN-операций с большими объемами данных - Интенсивные операции записи во временные файлы
Сложные сортировки: Операции ORDER BY с большими объемами данных
Агрегации: GROUP BY и агрегатные функции над большими наборами данных
Хеш-соединения: Hash joins, требующие создания хеш-таблиц на диске
Материализация: Принудительная материализация результатов подзапросов - Проблемы с дисковой подсистемой
Медленные диски: Использование HDD вместо SSD для временных файлов
Высокая задержка I/O: Проблемы с производительностью дисковой подсистемы
Конкуренция за ресурсы: Одновременное выполнение множества операций, использующих временные файлы - Неоптимальные запросы и отсутствие индексов
Полное сканирование таблиц: Отсутствие подходящих индексов
Неэффективные планы выполнения: Неоптимальные планы запросов
Избыточная материализация: Ненужная материализация промежуточных результатов
DataFileExtend
Ожидания типа DataFileExtend в PostgreSQL связаны с операциями расширения файлов данных (таблиц, индексов) на диске. Эти ожидания возникают, когда процессам требуется увеличить размер физического файла для размещения новых данных.
🔍 Основные причины роста ожиданий DataFileExtend
- Интенсивные операции вставки данных
Массовые INSERT-операции, особенно пакетная загрузка данных
Высокая частота вставки новых записей в таблицы
Отсутствие свободного пространства в существующих данных - Недостаточное предварительное выделение пространства
Таблицы и индексы не имеют достаточного свободного пространства для новых данных
Неправильная настройка параметров хранения (FILLFACTOR) - Автоматическое расширение табличных пространств
PostgreSQL вынужден постоянно расширять файлы данных для размещения новых записей
Частое выделение новых экстентов (extents) на диске - Проблемы с дисковой подсистемой
Медленные диски (HDD вместо SSD)
Высокая задержка операций выделения пространства на диске
Фрагментация дискового пространства - Отсутствие профилактического обслуживания
Нерегулярное выполнение VACUUM и ANALYZE
Неиспользование pg_prewarm для предварительной загрузки данных
DataFileImmediateSync
Ожидания типа DataFileImmediateSync в PostgreSQL связаны с синхронными операциями записи на диск, которые требуют немедленного физического сброса данных из кэша на диск. Эти ожидания указывают на проблемы с производительностью операций, требующих гарантированной записи данных.
🔍 Основные причины роста ожиданий DataFileImmediateSync
- Частые принудительные синхронные операции
Выполнение команд CHECKPOINT вручную
Использование pg_backup_start()/pg_backup_stop() для резервного копирования
Создание контрольных точек по требованию - Настройки надежности записи
Параметр synchronous_commit = on (значение по умолчанию)
Использование fsync = on для гарантии сохранности данных
Настройки синхронной репликации - Операции с высокой требовательностью к надежности
Критичные транзакции, требующие немедленной записи
Операции с важными данными, которые нельзя потерять
Системные операции, требующие гарантированной сохранности - Проблемы с дисковой подсистемой
Медленные диски (HDD вместо SSD)
Высокая задержка операций записи (write latency)
Перегруженная дисковая подсистема
Неоптимальная конфигурация RAID - Конфигурационные особенности
Малое значение wal_buffers
Частые контрольные точки из-за неправильной настройки
Использование синхронной репликации
DataFilePrefetch
Ожидания типа DataFilePrefetch в PostgreSQL связаны с операциями упреждающего чтения (prefetch) данных с диска. Эти ожидания возникают, когда процессы пытаются предварительно загрузить данные в кэш до того, как они понадобятся для обработки запросов.
🔍 Основные причины роста ожиданий DataFilePrefetch
- Неэффективные последовательные сканирования
Полное сканирование больших таблиц (sequential scan)
Отсутствие подходящих индексов для запросов
Неоптимальные планы выполнения запросов - Проблемы с дисковой подсистемой
Медленные диски (HDD вместо SSD)
Высокая задержка операций чтения (read latency)
Недостаточная пропускная способность I/O
Конкуренция за ресурсы дисковой подсистемы - Недостаточный размер кэшей
Маленький shared_buffers
Нехватка оперативной памяти для кэширования данных
Частое вытеснение данных из кэша - Особенности рабочих нагрузок
Аналитические запросы (OLAP), требующие чтения больших объемов данных
Отчеты и агрегации, обрабатывающие значительные части таблиц
Отсутствие партиционирования для больших таблиц - Настройки PostgreSQL
Неоптимальные значения effective_io_concurrency
Неправильная настройка maintenance_io_concurrency
Слишком агрессивная или пассивная стратегия prefetch.
DataFileRead
Ожидания типа DataFileRead в PostgreSQL связаны с операциями чтения данных с диска при обработке запросов. Эти ожидания возникают, когда данные не находятся в кэше (shared_buffers) и должны быть загружены с диска.
🔍 Основные причины роста ожиданий DataFileRead
- Недостаточный размер shared_buffers
Слишком маленький размер буферного кэша
Частое вытеснение данных из кэша
Неспособность удерживать рабочий набор данных в памяти - Неоптимальные запросы
Полное сканирование больших таблиц (sequential scan)
Отсутствие или неэффективное использование индексов
Сложные JOIN-операции с большими объемами данных - Проблемы с дисковой подсистемой
Медленные диски (HDD вместо SSD)
Высокая задержка операций чтения
Недостаточная пропускная способность I/O
Конкуренция за ресурсы дисковой подсистемы - Особенности рабочих нагрузок
Аналитические запросы, обрабатывающие большие объемы данных
Отчеты и агрегации, требующие полного сканирования таблиц
Отсутствие партиционирования для больших таблиц - Проблемы с планировщиком запросов
Неправильная оценка селективности условий
Неактуальная статистика по таблицам
Неоптимальные планы выполнения запросов
DataFileTruncate
Ожидания типа DataFileTruncate в PostgreSQL возникают, когда процесс ожидает операции усечения (truncation) файла данных, связанного с таблицей или индексом. Это происходит, когда PostgreSQL пытается освободить пространство на диске, уменьшая размер файла данных.
🔍 Основные причины роста ожиданий DataFileTruncate
- Частые операции усечения таблиц:
Выполнение команд TRUNCATE TABLE или DROP TABLE, которые требуют физического усечения файлов данных .
Автоматическое усечение при выполнении VACUUM FULL или CLUSTER, когда освобождаются целые страницы в конце файла. - Блокировки и конкуренция за ресурсы:
Операция TRUNCATE требует эксклюзивной блокировки таблицы (ACCESS EXCLUSIVE). Если другие транзакции удерживают блокировки на таблице (например, долгие запросы или незавершённые транзакции), процесс усечения будет ждать .
Конкуренция за доступ к файлам данных, когда несколько процессов пытаются изменить размер одного и того же файла. - Неэффективное управление пространством:
Таблицы с частыми операциями DELETE или UPDATE могут приводить к образованию "мертвых" кортежей. Если autovacuum не успевает очищать их, может потребоваться принудительное усечение файла .
Большие таблицы с высокой степенью фрагментации требуют частого усечения для освобождения пространства. - Проблемы с дисковой подсистемой:
Медленные диски (HDD вместо SSD) увеличивают время операции усечения, так как требуется физическое освобождение пространства на диске.
Высокая задержка операций ввода-вывода (I/O latency) усугубляет ожидания. - Длительные транзакции:
Если транзакция выполняется долго и блокирует таблицу, это может предотвратить усечение файла, так как PostgreSQL не может освободить пространство, которое может потребоваться для видимости данных .
DataFileWrite
Ожидания типа DataFileWrite в PostgreSQL возникают, когда процессы ожидают завершения операций физической записи данных на диск. Эти ожидания указывают на проблемы с производительностью операций ввода-вывода (I/O) и могут значительно влиять на общую производительность системы.
🔍 Основные причины роста ожиданий DataFileWrite
- Интенсивные операции записи:
Частые операции INSERT, UPDATE, DELETE или COPY, которые генерируют большой объем изменений данных.
Пакетная обработка данных (ETL-процессы), которая приводит к массовой записи на диск. - Недостаточный размер буферов:
Маленький размер shared_buffers приводит к тому, что измененные страницы (dirty pages) чаще сбрасываются на диск.
Нехватка оперативной памяти для кэширования данных, что увеличивает частоту операций записи. - Проблемы с дисковой подсистемой:
Медленные диски (HDD вместо SSD), которые не справляются с высокой нагрузкой на запись.
Высокая задержка операций записи (write latency) или недостаточная пропускная способность I/O.
Конкуренция за ресурсы дисковой подсистемы со стороны других процессов. - Настройки контрольных точек (Checkpoints):
Слишком частые контрольные точки из-за неправильной настройки checkpoint_timeout или max_wal_size.
Высокое значение checkpoint_completion_target может растягивать процесс записи, но при неправильной настройке увеличивает нагрузку. - Работа фоновых процессов:
Активность autovacuum или VACUUM FULL, которая требует записи измененных страниц на диск.
Создание индексов или операции обслуживания (например, CLUSTER), которые генерируют дополнительную нагрузку на I/O. - Режим надежности записи:
Использование synchronous_commit = on (по умолчанию), который требует немедленной записи WAL на диск для подтверждения транзакции.
Настройки синхронной репликации, которые могут увеличивать задержки записи.
DSMFillZeroWrite
Ожидания типа DSMFillZeroWrite в PostgreSQL связаны с операциями записи в сегменты динамической разделяемой памяти (Dynamic Shared Memory, DSM), которые требуют предварительного заполнения нулями для обеспечения безопасности и изоляции данных. Эти ожидания указывают на конкуренцию за ресурсы при инициализации новых сегментов DSM.
🔍 Основные причины роста ожиданий DSMFillZeroWrite
- Интенсивное использование параллельных запросов:
Параллельные операции (например, параллельное сканирование, сортировка или соединение) активно используют сегменты DSM для обмена данными между рабочими процессами. Частое создание новых сегментов увеличивает нагрузку на систему инициализации памяти.
Пример: Сложные аналитические запросы (OLAP) с большими объёмами данных. - Частое создание и уничтожение сегментов DSM:
Workload'ы, которые интенсивно используют временные сегменты DSM (например, короткие параллельные запросы), могут увеличивать нагрузку на систему управления из-за постоянного выделения и освобождения памяти.
Связь с пулерами соединений: Использование пулеров соединений (например, PgBouncer) в режиме transaction pooling может усугубить проблему, так как процессы часто переиспользуются для разных сеансов, что требует повторной инициализации сегментов. - Недостаточный размер буферов памяти:
Если объём оперативной памяти недостаточен для рабочих процессов, это может приводить к более частому созданию и уничтожению сегментов DSM, увеличивая нагрузку на систему инициализации.
Параметр dynamic_shared_memory_type: Использование неэффективного типа DSM (например, mmap) может увеличивать накладные расходы на запись нулей. - Проблемы с дисковой подсистемой:
Если используется тип DSM, требующий дисковых операций (например, mmap через файлы), медленные диски (HDD) могут увеличивать задержки при записи нулей в сегменты.
Высокая задержка I/O усугубляет ожидания, особенно при интенсивной работе с DSM. - Конкуренция за ресурсы:
Множество одновременных процессов, пытающихся инициализировать сегменты DSM, могут конкурировать за доступ к общим структурам управления памятью, что приводит к ожиданиям.
RelationMapRead
Ожидания типа RelationMapRead в PostgreSQL связаны с операциями чтения файлов отображения отношений (relation mapping files), которые хранят соответствия между системными каталогами и файлами данных. Эти ожидания указывают на проблемы с доступом к метаданным и могут влиять на общую производительность системы.
🔍 Основные причины роста ожиданий RelationMapRead
- Частые операции изменения схемы базы данных (DDL):
Операции CREATE, ALTER, DROP для таблиц, индексов, табличных пространств или других объектов базы данных требуют обновления файлов отображения отношений. Это приводит к частым операциям чтения этих файлов для проверки и обновления метаданных .
Пример: Массовое создание или изменение таблиц в рамках деплоя приложений или миграций. - Проблемы с дисковой подсистемой:
Медленные диски (HDD вместо SSD) или высокая задержка операций ввода-вывода (I/O latency) увеличивают время чтения файлов отображения отношений .
Конкуренция за ресурсы дисковой подсистемы со стороны других процессов может усугублять проблему. - Большое количество объектов в базе данных:
Если база данных содержит очень большое количество таблиц, индексов и других объектов, файлы отображения отношений становятся крупнее, а их чтение — более ресурсоемким .
Следствие: Увеличивается время, необходимое для доступа к метаданным при выполнении запросов или DDL-операций. - Неэффективное кэширование:
Если файлы отображения отношений не кэшируются в памяти (например, из-за нехватки оперативной памяти или частого вытеснения из кэша), это приводит к необходимости их частого чтения с диска . - Активность autovacuum и обслуживающих процессов:
Процессы autovacuum, VACUUM FULL или ANALYZE могут обращаться к файлам отображения отношений для обновления метаданных, особенно после массовых изменений данных .
RelationMapSync
Ожидания типа RelationMapSync в PostgreSQL связаны с операциями синхронизации файлов отображения отношений (relation mapping files), которые обеспечивают целостность метаданных при изменениях схемы базы данных. Эти ожидания указывают на проблемы с записью изменений в метаданные и могут существенно влиять на производительность.
🔍 Основные причины роста ожиданий RelationMapSync
- Интенсивные операции изменения схемы (DDL):
Частые операции CREATE, ALTER, DROP таблиц, индексов или табличных пространств требуют синхронизации файлов отображения отношений (pg_filenode.map, pg_tblspc.map).
Пример: Массовые миграции схемы, развертывание приложений с частыми обновлениями структуры БД. - Синхронная запись для обеспечения надежности:
PostgreSQL по умолчанию использует синхронную запись критичных метаданных для гарантии целостности данных после сбоя. Это требует физического сброса изменений на диск перед завершением операции, что приводит к ожиданиям.
Важно: Это поведение необходимо для консистентности, но может стать узким местом. - Проблемы с дисковой подсистемой:
Медленные диски (HDD): Высокая задержка операций записи (write latency) увеличивает время синхронизации.
Перегруженный I/O: Конкуренция за дисковые ресурсы с другими процессами (например, запись WAL, данные пользовательских таблиц).
Неоптимальная конфигурация FS: Файловая система без поддержки барьерных записей или с медленной синхронизацией. - Большое количество объектов в БД:
Крупные базы данных с десятками тысяч таблиц и индексов имеют большие файлы отображения, что увеличивает время их синхронизации. - Конкуренция за доступ к файлам отображения:
Несколько одновременных DDL-операций пытаются обновить одни и те же файлы метаданных, создавая конкуренцию за эксклюзивный доступ.
SLRURead
Ожидания типа SLRURead в PostgreSQL связаны с операциями чтения из SLRU-кэшей (Simple Least Recently Used), которые используются для управления специализированными структурами данных. Эти ожидания указывают на проблемы с доступом к критически важным системным буферам.
🔍 Основные причины роста ожиданий SLRURead
- Интенсивная работа с транзакциями и MultiXact:
Причина: SLRU-кэши используются для хранения статусов транзакций (в pg_xact, ранее pg_clog) и данных о мультитранзакциях (pg_multixact). Высокая концентрация коротких транзакций или активное использование SELECT FOR SHARE приводит к частым чтениям из этих структур.
Следствие: Каждая транзакция должна проверить свой статус или статус других транзакций, что вызывает обращения к SLRU-буферам. - Недостаточный размер буферов SLRU:
Причина: Буферы SLRU имеют фиксированный размер. При высокой нагрузке данные не помещаются в кэш, и возникают промахи (cache misses), требующие чтения с диска.
Пример: Частые чтения из pg_xact для проверки статусов транзакций. - Проблемы с дисковой подсистемой:
Медленные диски (HDD): Высокая задержка операций чтения увеличивает время доступа к SLRU-структурам.
Конкуренция за I/O: Другие процессы активно используют диск, что замедляет чтение данных SLRU. - Активность autovacuum:
Причина: autovacuum часто обращается к SLRU-структурам (особенно к pg_xact) для определения видимости кортежей. Если autovacuum не успевает за нагрузкой, это может приводить к росту ожиданий.
Следствие: Дополнительная нагрузка на SLRU-кэши. - Длительные транзакции:
Причина: Старые транзакции сохраняются в pg_xact, увеличивая объем данных, которые необходимо читать и проверять.
Следствие: Увеличивается размер SLRU-структур и частота обращений к ним.
SLRUWrite
Ожидания типа SLRUWrite в PostgreSQL связаны с операциями записи в SLRU-кэши (Simple Least Recently Used), которые используются для управления специализированными структурами данных, такими как статусы транзакций (pg_xact), данные о мультитранзакциях (pg_multixact), и другие служебные буферы. Эти ожидания указывают на проблемы с производительностью операций записи в эти критически важные системные буферы.
🔍 Основные причины роста ожиданий SLRUWrite
- Интенсивная работа с транзакциями и MultiXact:
Причина: SLRU-кэши используются для хранения статусов транзакций (в pg_xact, ранее pg_clog) и данных о мультитранзакциях (pg_multixact). Высокая концентрация коротких транзакций, активное использование SELECT FOR SHARE, или частые операции, затрагивающие множество транзакций, приводят к частым записям в эти структуры.
Следствие: Каждая транзакция или изменение статуса требует записи в SLRU-буферы, что увеличивает нагрузку. - Недостаточный размер буферов SLRU:
Причина: Буферы SLRU имеют фиксированный размер. При высокой нагрузке данные часто сбрасываются на диск (write-back), что приводит к операциям записи и ожиданиям SLRUWrite.
Пример: Частые записи в pg_xact или pg_multixact из-за нехватки места в буферах. - Проблемы с дисковой подсистемой:
Медленные диски (HDD): Высокая задержка операций записи (write latency) увеличивает время сброса данных SLRU на диск.
Конкуренция за I/O: Другие процессы активно используют диск, что замедляет запись данных SLRU. - Активность autovacuum и обслуживающих процессов:
Причина: Процессы autovacuum, VACUUM FULL, или операции обслуживания (например, CLUSTER) могут активно обновлять SLRU-структуры, особенно после массовых изменений данных.
Следствие: Дополнительная нагрузка на запись в SLRU-кэши. - Длительные транзакции и большое количество активных транзакций:
Причина: Старые транзакции или высокое количество одновременных транзакций увеличивают объем данных, которые необходимо записывать в SLRU-структуры (например, для поддержания статусов транзакций).
Следствие: Увеличивается частота операций записи и размер данных.
VersionFileSync
Ожидания типа VersionFileSync в PostgreSQL связаны с операциями синхронизации файлов версий (version files), которые используются для управления данными в многовариантном окружении, таких как обработка строк с несколькими версиями (MVCC — Multi-Version Concurrency Control) или работа с TOAST-таблицами. Эти ожидания указывают на проблемы с записью и синхронизацией данных на диск.
🔍 Основные причины роста ожиданий VersionFileSync
- Интенсивные операции обновления данных:
Частые операции UPDATE или DELETE, которые создают новые версии строк (из-за MVCC), могут увеличивать нагрузку на запись и синхронизацию файлов версий.
Большое количество версий строк в таблицах требует более частой синхронизации с диском. - Работа с большими объектами (TOAST):
Таблицы с большими объектами (TOAST) могут генерировать дополнительные операции записи и синхронизации, особенно при обновлении или удалении больших данных.
Частое изменение TOAST-данных приводит к росту ожиданий VersionFileSync. - Проблемы с дисковой подсистемой:
Медленные диски (HDD вместо SSD) или высокая задержка операций записи (write latency) увеличивают время синхронизации файлов версий.
Конкуренция за ресурсы дисковой подсистемы со стороны других процессов (например, запись WAL, операции VACUUM). - Настройки контроля устойчивости:
Использование synchronous_commit = on (по умолчанию) требует немедленной синхронизации критичных данных с диском, что может усиливать ожидания.
Высокие требования к надежности данных, такие как синхронная репликация, также contribute to these waits. - Активность autovacuum:
Процессы autovacuum или VACUUM FULL, которые обрабатывают старые версии строк, могут вызывать дополнительные операции записи и синхронизации.
Если autovacuum не успевает за нагрузкой, это может приводить к накоплению версий строк и увеличению синхронизации.
WALInitSync
Ожидания типа WALInitSync в PostgreSQL связаны с операциями синхронизации при инициализации новых сегментов WAL (Write-Ahead Log). Эти ожидания возникают, когда PostgreSQL создает новые WAL-сегменты и требуется гарантировать их корректную запись на диск перед использованием.
🔍 Основные причины роста ожиданий WALInitSync
- Частое создание новых WAL-сегментов:
Быстрое заполнение WAL: Интенсивные операции записи (массовые INSERT, UPDATE, COPY) приводят к быстрому заполнению существующих WAL-сегментов и необходимости создания новых.
Недостаточный размер WAL: Малое значение max_wal_size или слишком частые контрольные точки (checkpoint_timeout) могут увеличивать частоту создания новых сегментов. - Синхронные требования к надежности:
Режим synchronous_commit = on: Требует немедленной синхронизации WAL-данных с диском для гарантии сохранности транзакций.
Синхронная репликация: Если настроена синхронная репликация, подтверждение транзакции требует гарантированной записи WAL на диск основного сервера и реплик. - Проблемы с дисковой подсистемой:
Медленные диски (HDD): Высокая задержка операций записи (write latency) увеличивает время инициализации и синхронизации новых WAL-сегментов.
Конкуренция за I/O: Другие процессы (например, запись данных, VACUUM) создают нагрузку на диск, замедляя операции с WAL. - Настройки WAL:
Маленький размер wal_segment_size (по умолчанию 16 МБ): Меньший размер сегментов означает их более частое создание, что может увеличивать нагрузку на синхронизацию.
Неоптимальный wal_buffers: Недостаточный размер буферов WAL может приводить к более частым сбросам данных на диск. - Активность репликации и архивации:
Задержки репликации: Если реплики отстают, это может косвенно влиять на работу WAL.
Проблемы с archive_command: Медленная или failing команда архивации может приводить к накоплению WAL-сегментов.
WALInitWrite
Ожидания типа WALInitWrite в PostgreSQL связаны с операциями инициализации и записи новых сегментов WAL (Write-Ahead Log). Эти ожидания возникают, когда процессы должны создать и проинициализировать новый сегмент WAL, заполнив его начальными данными (часто нулями или заголовками), чтобы обеспечить целостность журнала перед его использованием. Это критически важный процесс для поддержания надежности и согласованности данных, но он может стать узким местом при определенных условиях.
🔍 Основные причины роста ожиданий WALInitWrite
- Интенсивная нагрузка на запись и частое переключение WAL-сегментов:
Высокая частота операций записи (например, массовые INSERT, UPDATE, COPY) приводит к быстрому заполнению существующих WAL-сегментов. Когда сегмент заполняется, PostgreSQL должен создать новый, что требует операции инициализации и записи (WALInitWrite). Это особенно заметно при нагрузках, генерирующих большой объем WAL-данных за короткое время .
Недостаточный размер WAL: Если параметр max_wal_size установлен слишком низким или система генерирует необычно много WAL-данных (например, из-за длительных транзакций или больших объемов данных), это может приводить к более частому созданию новых сегментов . - Проблемы с дисковой подсистемой:
Медленные диски (HDD): Операции инициализации WAL требуют записи на диск. Высокая задержка операций ввода-вывода (write latency) на HDD-дисках значительно увеличивает время выполнения WALInitWrite .
Конкуренция за ресурсы I/O: Если дисковая подсистема перегружена другими операциями (например, запись данных пользовательских таблиц, работа VACUUM, репликация), это может замедлить инициализацию WAL . - Настройки контрольных точек (Checkpoints):
Частые контрольные точки (из-за малого значения checkpoint_timeout или быстрого достижения max_wal_size) могут увеличивать нагрузку на WAL-подсистему, включая операции инициализации новых сегментов . - Настройки WAL:
Размер сегмента WAL: Стандартный размер сегмента WAL в PostgreSQL составляет 16 МБ. В некоторых сценариях (очень высокая нагрузка) это может приводить к частому переключению сегментов. Хотя изменение размера сегмента требует переинициализации кластера, это может быть рассмотрено для специализированных окружений.
Недостаточный размер wal_buffers: Если буфер WAL слишком мал, данные чаще сбрасываются на диск, что может косвенно влиять на операции инициализации . - Активность репликации и архивации:
Синхронная репликация: Если настроена синхронная репликация, это может увеличивать задержки записи WAL, включая этап инициализации, так как требуется подтверждение от реплик .
Проблемы с archive_command: Если команда архивации выполняется медленно или завершается с ошибками, это может приводить к накоплению WAL-сегментов и увеличению нагрузки на систему .
WALSync
Ожидания типа WALSync в PostgreSQL связаны с операциями синхронной записи буферов WAL (Write-Ahead Log) на диск. Эти ожидания возникают, когда процессы должны гарантировать, что данные WAL физически записаны на диск перед подтверждением транзакции. Это критически важный механизм обеспечения надежности, но он может стать узким местом производительности.
🔍 Основные причины роста ожиданий WALSync
- Синхронная фиксация транзакций (synchronous_commit = on):
Это основная причина. При значении on или remote_write PostgreSQL ждет подтверждения физической записи WAL на диск перед подтверждением транзакции клиенту. Это обеспечивает максимальную надежность (данные не потеряются при сбое), но создает задержки, так как процесс блокируется в ожидании завершения дискового I/O. - Медленная дисковая подсистема:
Высокая задержка записи (high write latency): Это самая частая техническая причина. Медленные HDD (особенно SMR) или перегруженные диски (высокий await в iostat) не успевают обрабатывать поток синхронных записей.
Недостаточная пропускная способность (low IOPS): Дисковая система не справляется с объемом синхронных записей, требуемым рабочей нагрузкой. - Синхронная репликация:
При использовании синхронной репликации (synchronous_standby_names) подтверждение транзакции требует не только записи на диск основного сервера, но и подтверждения от одной или нескольких реплик (в зависимости от настроек). Если реплики физически далеко или сами испытывают проблемы с I/O, это значительно увеличивает время ожидания WALSync. - Интенсивная нагрузка на запись:
Высокий rate транзакций, изменяющих данные (особенно небольшие транзакции с частым коммитом), создает постоянный поток операций fsync, что перегружает диск. - Конкуренция за ресурсы:
Другие процессы, активно использующие тот же диск (например, VACUUM, запись данных больших таблиц, обработка TOAST-объектов), конкурируют с WAL за пропускную способность I/O.
WALWrite
Ожидания типа WALWrite в PostgreSQL возникают, когда процессы ожидают завершения операций физической записи буферов WAL (Write-Ahead Log) на диск. Эти ожидания указывают на проблемы с производительностью операций ввода-вывода (I/O) и могут значительно влиять на общую производительность системы.
🔍 Основные причины роста ожиданий WALWrite
- Интенсивные операции записи:
Частые операции INSERT, UPDATE, DELETE или COPY, которые генерируют большой объем изменений данных. Это приводит к активному использованию WAL и увеличивает частоту операций записи на диск .
Пакетная обработка данных (ETL-процессы), которая приводит к массовой записи на диск. - Медленная дисковая подсистема:
Использование медленных дисков (HDD вместо SSD), которые не справляются с высокой нагрузкой на запись. Высокая задержка операций записи (write latency) или недостаточная пропускная способность I/O значительно увеличивают время записи буферов WAL на диск .
Конкуренция за ресурсы дисковой подсистемы со стороны других процессов (например, запись данных пользовательских таблиц, работа VACUUM). - Недостаточный размер буферов WAL:
Маленький размер wal_buffers приводит к тому, что данные чаще сбрасываются на диск, что увеличивает конкуренцию и ожидания .
Нехватка оперативной памяти для кэширования данных, что увеличивает частоту операций записи. - Настройки контрольных точек (Checkpoints):
Слишком частые контрольные точки из-за неправильной настройки checkpoint_timeout или max_wal_size могут увеличивать нагрузку на WAL-подсистему .
Низкое значение checkpoint_completion_target может приводить к резким пикам нагрузки на запись. - Синхронная фиксация транзакций:
Использование synchronous_commit = on (по умолчанию) требует немедленной записи WAL на диск для подтверждения транзакции. Это обеспечивает надежность, но увеличивает задержки .
Синхронная репликация (synchronous_standby_names) требует подтверждения записи не только от основного сервера, но и от реплик, что дополнительно увеличивает время ожидания . - Проблемы с репликацией и архивацией:
Задержки репликации или неисправность archive_command могут приводить к накоплению WAL-сегментов и увеличению нагрузки на систему .