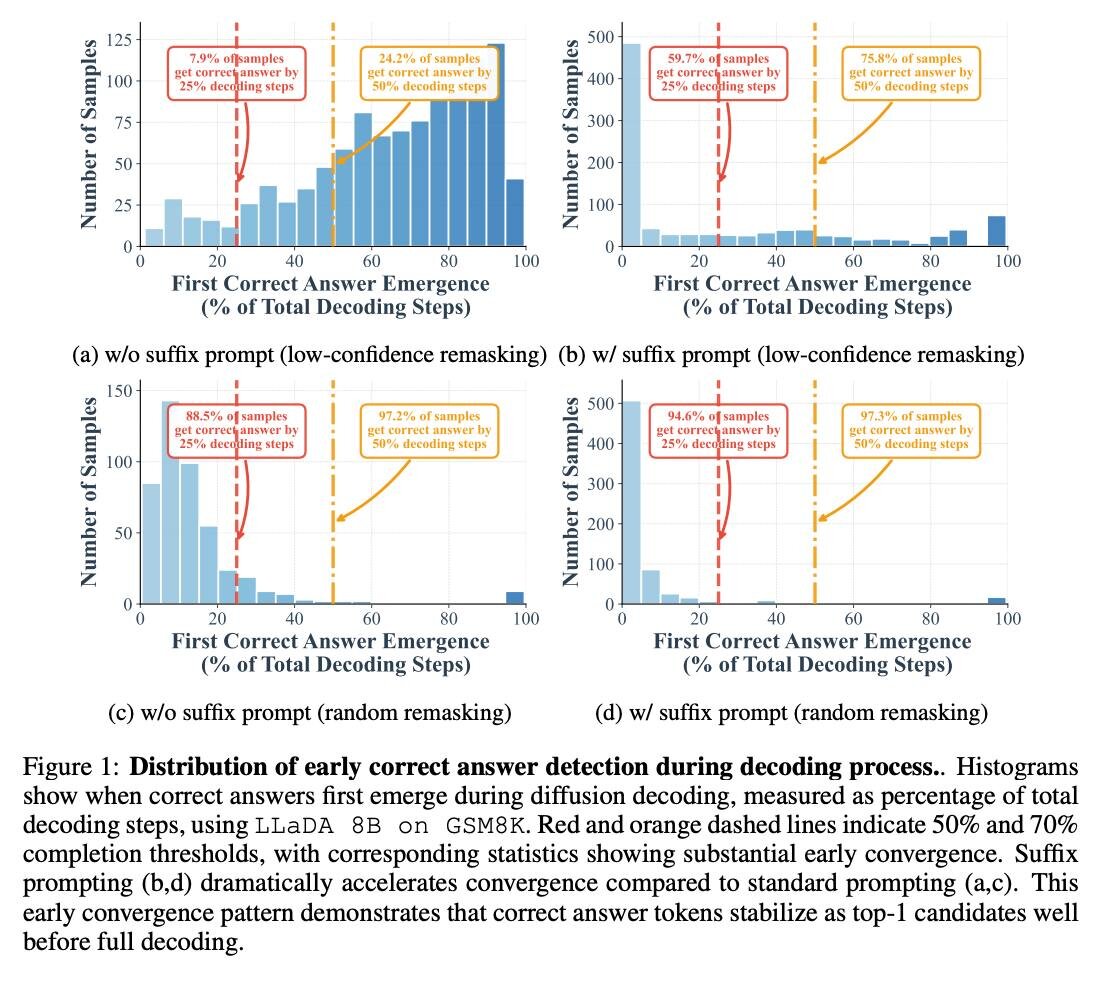
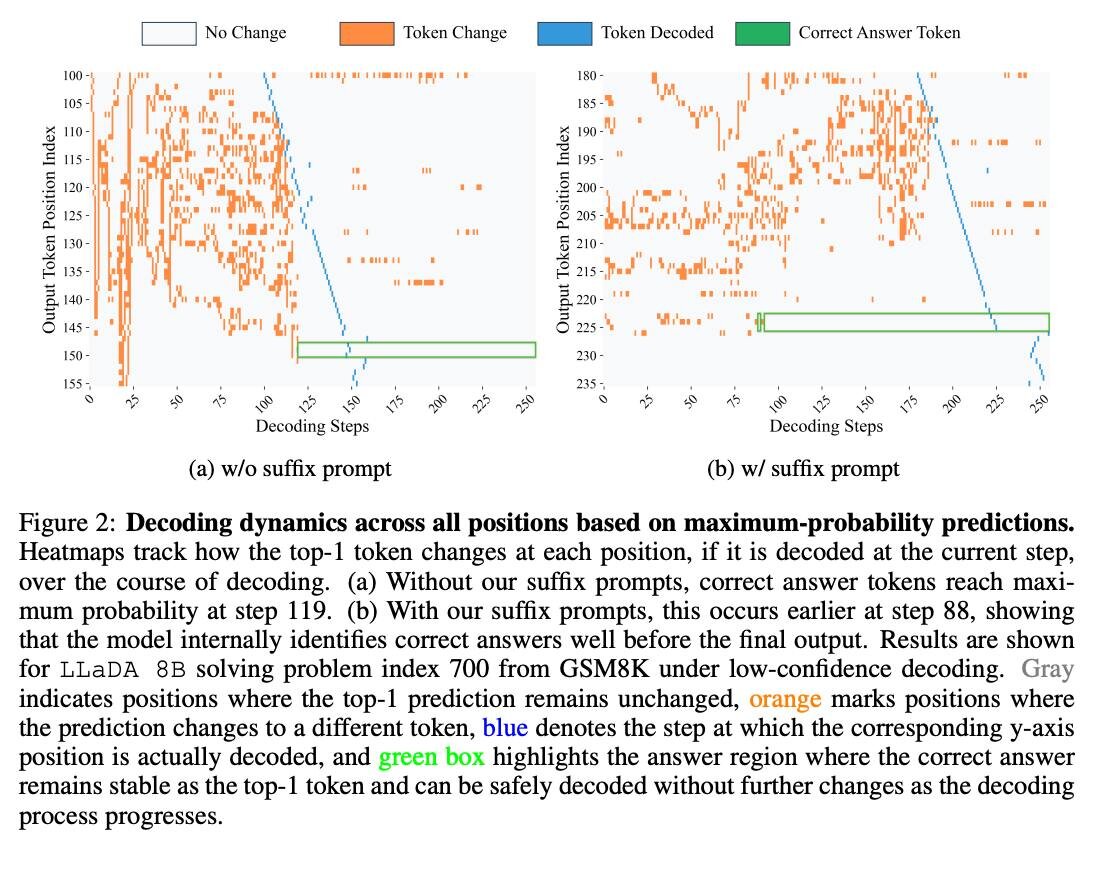
🆕 Исследование: LLM могут находить правильный ответ ещё до конца генерации. На GSM8K — до 97% задач, на MMLU — до 99% ответов верны уже на середине шагов. Метод Prophet позволяет остановить генерацию раньше и ускорить модель в 3.4 раза без потери качества. 💡 Как работает Prophet: 1. На каждом шаге смотрит на разрыв уверенности между топ-1 и топ-2 токенами 2. Если разрыв большой → модель уже «уверена» 3. Декодирование останавливается досрочно, оставшиеся токены фиксируются сразу 🔗 Подробности: arxiv.org/pdf/2508.19982
🆕 Исследование: LLM могут находить правильный ответ ещё до конца генерации.
На GSM8K — до 97% задач, на MMLU — до 99% ответов верны уже на середине шагов.
Метод Prophet позволяет остановить генерацию раньше и ускорить модель в 3.4 раза без потери качества.
💡 Как работает Prophet:
1. На каждом шаге смотрит на разрыв уверенности между топ-1 и топ-2 токенами
2. Если разрыв большой → модель уже «уверена»
3. Декодирование останавливается досрочно, оставшиеся токены фиксируются сразу
🔗 Подробности: arxiv.org/pdf/2508.19982