Цель: взять базу знаний в виде текстовых файлов и векторизовать ее для нахождения подходящего контекста по пользовательскому запросу и синтеза ответа нейросетью.
Алгоритм действий:
Устанавливаем ollama для запросов к локальной нейросети
yay -S ollama
sudo systemctl start ollama.service
Скачиваем модели для ollama:
ollama pull mxbai-embed-large
ollama pull llama3:8b
Создаем каталог, в котором будет хранится векторная база chromadb
mkdir /home/username/persistent/store -p
Создаем каталог, в котором будут текстовые файлы с базой знаний
mkdir /home/username/dataset
Для теста будем использовать файл main.txt с абсурдным содержанием, чтобы
убедится, что контекст точно берется из векторной базы
cd ~/dataset
nano main.txt
Вставляем тестовый текст:
Название компании - "Рога и копыта"
Год основания - 666 до нашей эры
Создадим каталог для двух скриптов - один будет строить векторную базу, другой отвечать на запрос пользователя согласно найденным контекстам. Одновременно сделаем виртуальное окружение для Python
cd
python -m venv myrag
cd myrag/
source bin/activate
Скачиваем зависимости
pip install ollama
pip install chromadb
Создаем файл с построителем векторной базы
nano vectorize.py
Вставляем исходный код:
import ollama
import chromadb
import os
client = chromadb.PersistentClient(path="/home/username/persistent/store")
collection = client.create_collection(name="documents")
dataset_path = "/home/artem/dataset"
for i, filename in enumerate(os.listdir(dataset_path)):
if filename.endswith(".txt"):
with open(os.path.join(dataset_path, filename), "r") as f:
data = f.read()
response = ollama.embed(model="mxbai-embed-large", input=data)
embeddings = response["embeddings"]
collection.add(ids=[str(i)], embeddings=embeddings, documents=[data])
Запускаем векторизацию
python vectorize.py
После завершения исполнения в каталоге ~/persistent/store появится база данных ChromaDb в sqlite формате, которую можно открыть в SqliteBrowser
Создаем диалоговый файл dialog.py:
nano dialog.py
Исходный код
import chromadb
import ollama
import os
# === Шаг 1: Подключаемся к ChromaDB ===
persist_directory = os.path.expanduser("~/persistent/store")
client = chromadb.PersistentClient(path=persist_directory)
# === Шаг 2: Загружаем коллекцию "documents" ===
try:
collection = client.get_collection(name="documents")
print("✅ Коллекция 'documents' загружена")
except Exception as e:
print("❌ Ошибка: не удалось загрузить коллекцию 'documents'.")
raise e
# === Шаг 3: Задаём вопрос ===
query_text = input("💬 Задайте вопрос: ")
# === Шаг 4: Генерируем эмбеддинг запроса той же моделью: mxbai-embed-large ===
try:
response = ollama.embed(model="mxbai-embed-large", input=query_text)
query_embedding = response["embeddings"][0]
except Exception as e:
print("❌ Ошибка генерации эмбеддинга:", e)
print("💡 Выполните: ollama pull mxbai-embed-large")
raise e
# === Шаг 5: Запрашиваем релевантные документы ===
results = collection.query(
query_embeddings=[query_embedding],
n_results=3,
include=["documents"]
)
# === Шаг 6: Формируем контекст ===
context_list = [doc for doc_list in results['documents'] for doc in doc_list]
context = "\n\n".join(context_list)
if not context.strip():
print("⚠️ Контекст не найден.")
context = "Нет данных."
print("\n" + "="*60)
print("📄 КОНТЕКСТ:")
print("="*60)
print(context[:1500] + "..." if len(context) > 1500 else context)
print("="*60)
# === Шаг 7: Генерируем ответ с помощью llama3 и русского промпта ===
prompt = f"""
Отвечай ТОЛЬКО на основе контекста ниже. Не добавляй ничего от себя.
Если в контексте нет ответа — скажи "Не знаю".
Контекст:
{context}
Вопрос: {query_text}
Ответ:
"""
print("\n🧠 Генерация ответа с помощью llama3...\n")
try:
response = ollama.generate(model="llama3:8b", prompt=prompt)
print("✅ ОТВЕТ:")
print("="*60)
print(response['response'].strip())
except Exception as e:
print("❌ Ошибка:", e)
print("💡 Установите модель: ollama pull llama3:8b")
Теперь запускаем диалог:
python dialog.py
Результат в терминале:
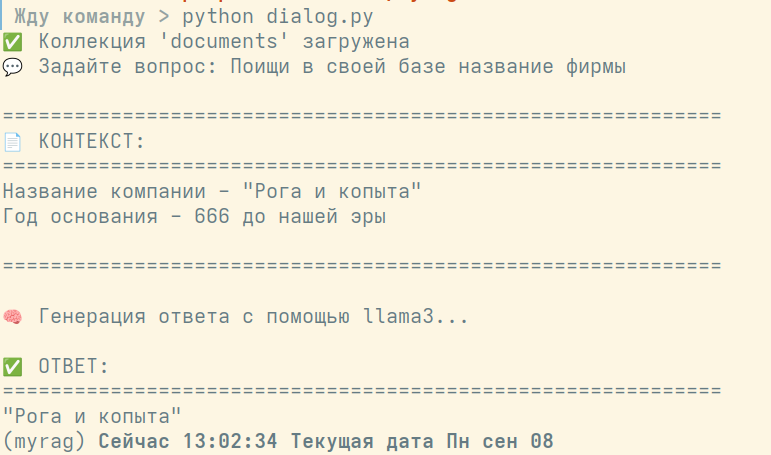
Жду команду > python dialog.py
✅ Коллекция 'documents' загружена
💬 Задайте вопрос: Поищи в своей базе название фирмы
============================================================
📄 КОНТЕКСТ:
============================================================
Название компании - "Рога и копыта"
Год основания - 666 до нашей эры
============================================================
🧠 Генерация ответа с помощью llama3...
✅ ОТВЕТ:
============================================================
"Рога и копыта"
(myrag) Сейчас 13:02:34 Текущая дата Пн сен 08