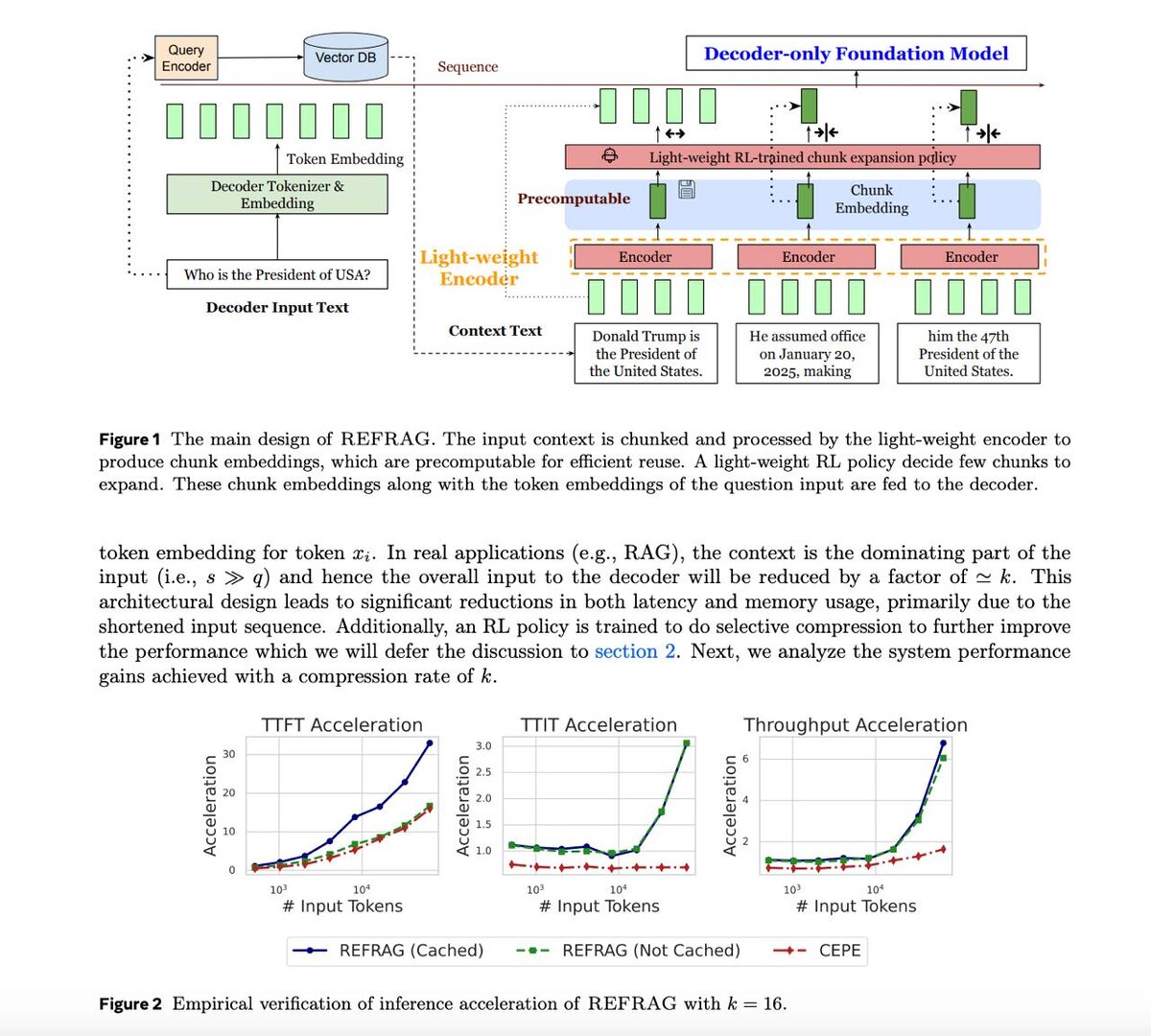
⚡️ REFRAG: новое поколение RAG
REFRAG ускоряет работу Retrieval-Augmented Generation, сжимая контекст в chunk embeddings, сохраняя качество ответов.
📌 Результаты:
- До 30.85× быстрее первый токен
- До 16× длиннее эффективный контекст без потери точности
🔍 В чём идея:
Обычные RAG-промпты вставляют кучу текстов, половина из которых не нужна → модель тратит вычисления впустую.
REFRAG заменяет токены этих текстов кэшированными эмбеддингами, подгоняет их под размер декодера и подаёт вместе с вопросом.
Последовательность короче → внимание масштабируется по чанкам, а не по токенам → меньше памяти уходит на KV-кэш.
🎯 Как работает:
- Большинство чанков остаются сжатыми.
- Специальная политика выбирает, какие именно разжать обратно в токены, если важна точная формулировка.
- Обучение идёт в 2 шага: сначала модель учится восстанавливать токены из эмбеддингов, потом продолжается предобучение с задачей прогнозирования следующего абзаца (постепенно увеличивая размер чанков).
- Политика сжатия/разжатия тренируется через reinforcement learning, используя лосс предсказания слова как сигнал.
📄 Paper: arxiv.org/abs/2509.01092