В последние годы мы привыкли к тому, что большие языковые модели вроде GPT могут писать статьи, решать задачи и даже объяснять научные концепции. Но вместе с этим возникло понятие «галлюцинации» — когда модель уверенно выдаёт неправду. OpenAI в своём исследовании Why language models hallucinate подробно объяснила, откуда берётся эта проблема и почему полностью избавиться от неё пока невозможно.
🔍 Почему это происходит
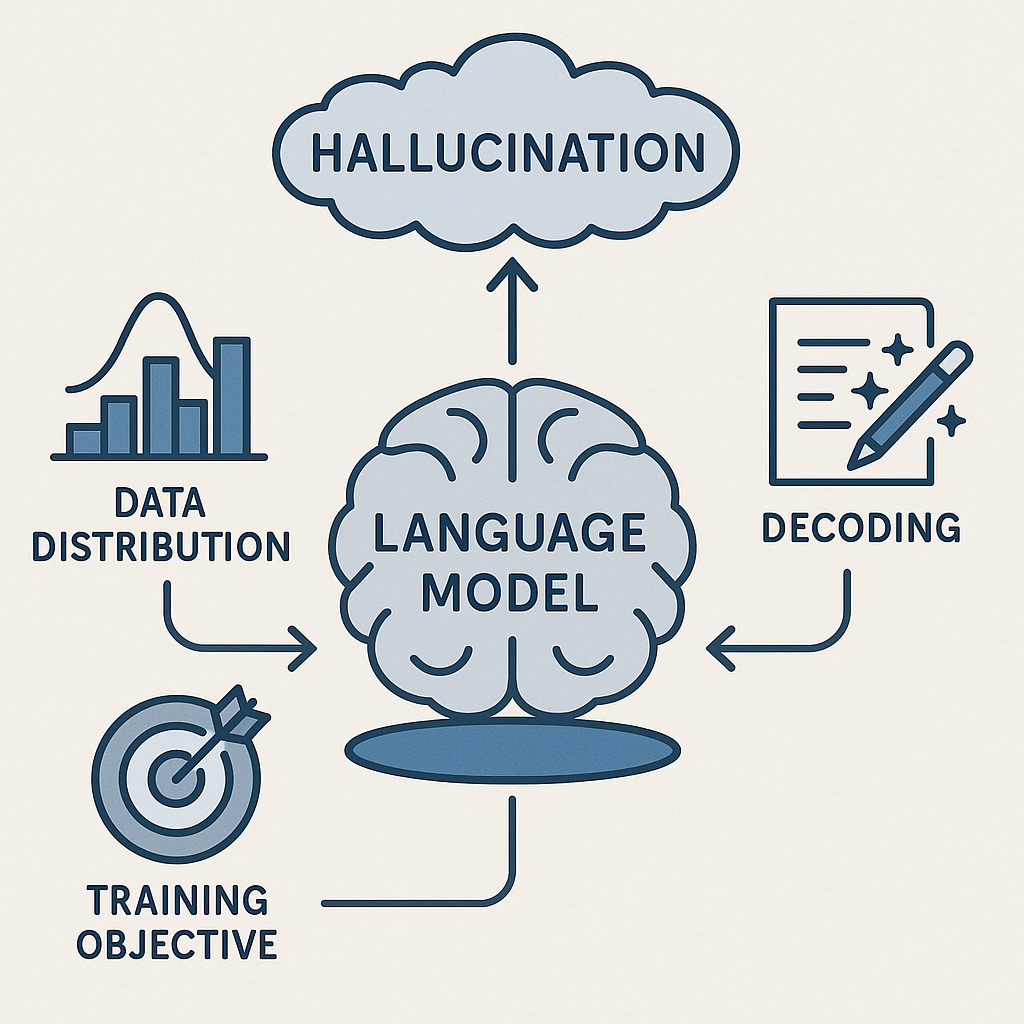
У галлюцинаций несколько источников:
📊 Цель обучения — модель предсказывает следующий токен по статистическим паттернам, а не проверяет факты. Она оптимизирована на правдоподобие текста, а не на истинность.
🌍 Несоответствие данных и запросов — в реальной жизни пользователи задают вопросы, на которые в обучающих данных может просто не быть ответа.
🌀 Стратегии декодирования — greedy search, beam search или сэмплинг усиливают уверенность модели, даже если база для ответа слабая.
🏆 Метрики — современные тесты поощряют угадывание, а не «смиренное» признание незнания. В итоге модели учатся чаще рисковать.
🧮 Пример с «экзаменом»
Представьте экзамен с тестами:
- если вы угадаете — шанс получить балл;
- если честно скажете «не знаю» — баллов не будет.
Модель выбирает угадывание, ведь так она «лучше выглядит» в метриках. Но именно это и создаёт галлюцинации.
🛠 Что помогает снизить проблему
Сейчас исследователи используют несколько подходов:
🔎 RAG (retrieval-augmented generation) — подключение внешних баз знаний для фактической поддержки ответов.
🧩 Инструменты и плагины — например, калькулятор или поиск.
🤝 RLHF (обучение с подкреплением от человека) — дообучение на предпочтениях людей, чтобы модель училась признавать неопределённость.
✍️ Улучшение промптов — корректно заданный запрос снижает шанс на ошибку.
💡 Мой взгляд
Меня впечатляет, что проблема здесь не столько в «умности» моделей, сколько в статистической природе обучения. Они невероятно хорошо схватывают закономерности, но когда речь заходит о редких фактах, мы словно спрашиваем у них дату дня рождения кота из случайной фотографии — информация просто недоступна, и модель вынуждена «догадаться».
Важно, что OpenAI честно признаёт: полностью избавиться от галлюцинаций нельзя, но можно изменить систему оценивания. Если мы перестанем поощрять угадывания и начнём ценить честное «не знаю», это не только сделает модели надёжнее, но и изменит стиль взаимодействия человека с ИИ.
📚 Ссылки:
🔗 OpenAI: Why language models hallucinate