В воздухе запахло сентябрем, лето подходит к концу. А это значит, что важно не проебать лето закрыть все летние дела. В начале лета я начал писать «большую и красивую статью» про новый алгоритм Muvera, но так и не закончил. Помешало мое системное мышление: статья предполагала много формул и интерпретацию математики на язык среднестатистического seo-специалиста. Поэтому я хотел написать её в своем блоге, а не в ТГ. Понял, что блог надо переделывать. Запустил масштабное планирование блога, сайта, а с ним и менеджмента своей жизни… В общем, статья пылится в черновиках уже почти 2 месяца. Обязательно её выложу). Ну а пока что напишу краткие выжимки и тезисы, иначе не смогу спать спокойно.
Что такое Muvera?
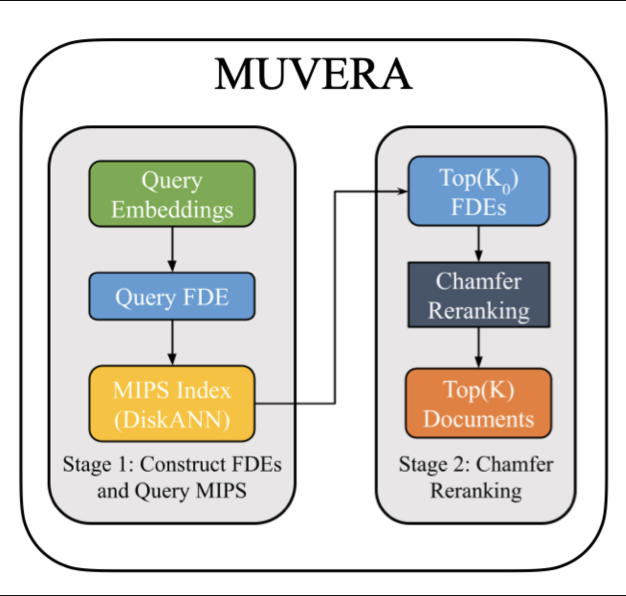
Multi‑Vector Retrieval via Fixed‑Dimensional Encodings (MUVERA) - новая мультивекторная модель поиска в поисковой системе Google. Модель не заменяет, а дополняет существующие технологии понимания контекста, такие как Bert, решая проблемы масштабируемости и скорости.
В чем суть алгоритма?
Текущие алгоритмы нейросетевого поиска строятся на эмбеддингах – векторах. Упрощенно: запрос и документ преобразуются в вектора по различным моделям – наборы чисел. А дальше вычисляются разные метрики, например, как косинусное сходство. Вектора с наилучшей метрикой признаются близкими, т.е. запросу присваивается наиболее релевантные текстовые документы. Такая модель быстрая, но не всегда учитывает все аспекты точности. Запросу могут быть релевантны документы по разным причинам, а модель это усредняет.
Мультивекторный поиск действует по похожему принципу, но каждому запросу и документу присваиваются несколько векторов. Общее число в датасете векторов увеличивается на порядки, что осложняет вычисления. Задачу решают двумя этапами: на первом для запроса и документа создают в отдельном пространстве вектора фиксированной размерности (FDE), вычисляют их скалярное произведение (MIPS) и возвращают ТОП k кандидатов документов. А на втором этапе более точно (сходство Чамфера) ранжируют запрос среди этих k кандидатов.
Пример работы Muvera
Запрос «где купить диван?» разбивается на вектора, которые попадают в блоки: «где» блок «место», «купить» блок «действие», «диван» блок «объект». Слова текста из документов также разбивается на векторы и блоки. Часть векторов из документа попадают в одни блоки векторов запроса. И если на странице не было векторов, которые попали бы в блок «место» (красноярск, торговый центр), «действие» (купить, заказать) и «объект» (кровать, диван, тумбочка), то они упрощенно говоря, пролетают (на самом деле нет, просто их суммарный вектор будет «хуже»).
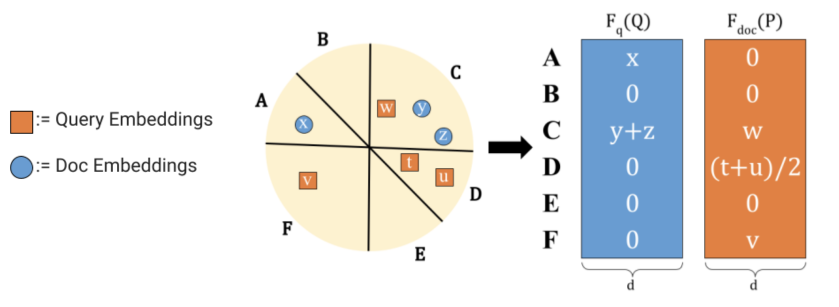
Далее на стороне запроса суммируются все векторы, попавшие в один блок, а на стороне страницы усредняются векторы, попавшие в этот же блок. Ну и затем опять все агрегированные векторы запроса объединяются в один вектрор q, все векторы страницы в другой вектор p. Вычисляется Mips между этими двумя векторами, обираются k кандидатов (страницы с диванами, покупками и местами), и из них уже вычисляют что подходит по точно алгоритмам релевантности – документы более точно нацеленные на решение задачи выбора месте для покупки диванов.
Muvera уже работает?
Новый алгоритм был анонсирован в конце июня. В июле представители Google заявили, что развернули в поиске что-то похожее, но не совсем Muvera. Поэтому что-то похожее работает.
Практическая ценность для SEO?
Принципиально ничего не изменилось. Muvera просто дал возможность вычислять на 90% быстрее и на 10% точнее, при этом экономя память и ресурсы. Если мы говорим про текстовую оптимизацию (или ссылочную текстовую релевантность) для Google, то мы также должны подготавливать контент, основанный на сущностях (entity). Если мы продвигаем страницу под запрос «где купить диван» в тексте и ссылках раскрывайте сущности запросов: локация объектов, конкретные названия офисов и улицы, условия покупки, ценовой диапазон, формы оплаты, ассортимент и вариации диванов. Само же вхождение «где купить диван» или «покупка дивана» использовать уже давно совсем не обязательно.
Ссылки на research: ссылка 1, ссылка 2
Не стесняйтесь комментировать и не забывайте подписываться и читать меня в на Дзене, группе VK, Youtube, Rutube, блоге VC и на моем ТГ канале "SEO PRO Деньги".